🚀 视觉变换器(ViT)NSFW检测器
本模型基于视觉变换器架构,在约25000张图像(包括绘画、照片等)上微调而来,可精准识别图像是否包含不适宜内容,为图像筛选提供高效解决方案。
🚀 快速开始
本模型是 vit-base-patch16-384 的微调版本,在约25000张图像(绘画、照片等)上进行了微调。它在评估集上取得了以下结果:
最新消息 [07/30]:我专门为稳定扩散应用创建了一个新的ViT模型,用于检测NSFW/SFW图像(原因请阅读下面的免责声明):AdamCodd/vit-nsfw-stable-diffusion。
免责声明:本模型并非针对生成图像设计!这里使用的数据集中没有生成图像,并且它在生成图像上的表现明显较差,这需要另一个专门针对生成图像训练的ViT模型。以下是该模型在生成图像上的实际得分,供您参考:
- 损失值:0.3682(↑ 292.95%)
- 准确率:0.8600(↓ 10.91%)
- F1值:0.8654
- AUC值:0.9376(↓ 5.75%)
- 精确率:0.8350
- 召回率:0.8980
✨ 主要特性
- 精准识别:在评估集上准确率高达0.9654,能有效识别图像是否包含不适宜内容。
- 多类型支持:在多种类型图像(写实、3D、绘画)上进行训练,具有广泛适用性。
📦 安装指南
文档未提及安装步骤,可参考Hugging Face官方文档进行安装。
💻 使用示例
基础用法
本地图像使用示例
from transformers import pipeline
from PIL import Image
img = Image.open("<path_to_image_file>")
predict = pipeline("image-classification", model="AdamCodd/vit-base-nsfw-detector")
predict(img)
远程图像使用示例
from transformers import ViTImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('AdamCodd/vit-base-nsfw-detector')
model = AutoModelForImageClassification.from_pretrained('AdamCodd/vit-base-nsfw-detector')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
高级用法
使用Transformers.js(原生JS)的示例
import { pipeline, env } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.1';
env.allowLocalModels = false;
const classifier = await pipeline('image-classification', 'AdamCodd/vit-base-nsfw-detector');
async function classifyImage(url) {
try {
const response = await fetch(url);
if (!response.ok) throw new Error('Failed to load image');
const blob = await response.blob();
const image = new Image();
const imagePromise = new Promise((resolve, reject) => {
image.onload = () => resolve(image);
image.onerror = reject;
image.src = URL.createObjectURL(blob);
});
const img = await imagePromise;
const classificationResults = await classifier([img.src]);
console.log('Predicted class: ', classificationResults[0].label);
} catch (error) {
console.error('Error classifying image:', error);
}
}
classifyImage('https://example.com/path/to/image.jpg');
📚 详细文档
模型描述
视觉变换器(ViT)是一种基于Transformer编码器的模型(类似BERT),它在大量图像上进行了有监督的预训练,特别是在ImageNet - 21k数据集上,图像分辨率为224x224像素。随后,该模型在ImageNet(也称为ILSVRC2012)数据集上进行了微调,该数据集包含100万张图像和1000个类别,图像分辨率提高到384x384。
预期用途和限制
该模型有两个类别:SFW(适宜内容)和NSFW(不适宜内容)。模型经过训练,具有较高的限制性,因此会将“性感”的图像分类为NSFW。也就是说,如果图像显示出乳沟或过多的皮肤,它将被分类为NSFW,这是正常现象。
该模型在各种图像(写实、3D、绘画)上进行了训练,但并不完美,有些图像可能会被错误地分类为NSFW。此外,请注意,在transformers.js管道中使用量化的ONNX模型会略微降低模型的准确性。
您可以在 这里 找到使用Transformers.js对该模型的简单实现。
训练和评估数据
更多信息待补充。
训练过程
训练超参数
训练过程中使用了以下超参数:
- 学习率:3e - 05
- 训练批次大小:32
- 评估批次大小:32
- 随机种子:42
- 优化器:Adam,β值为(0.9, 0.999),ε值为1e - 08
- 训练轮数:1
训练结果
- 验证损失值:0.0937
- 准确率:0.9654
- AUC值:0.9948
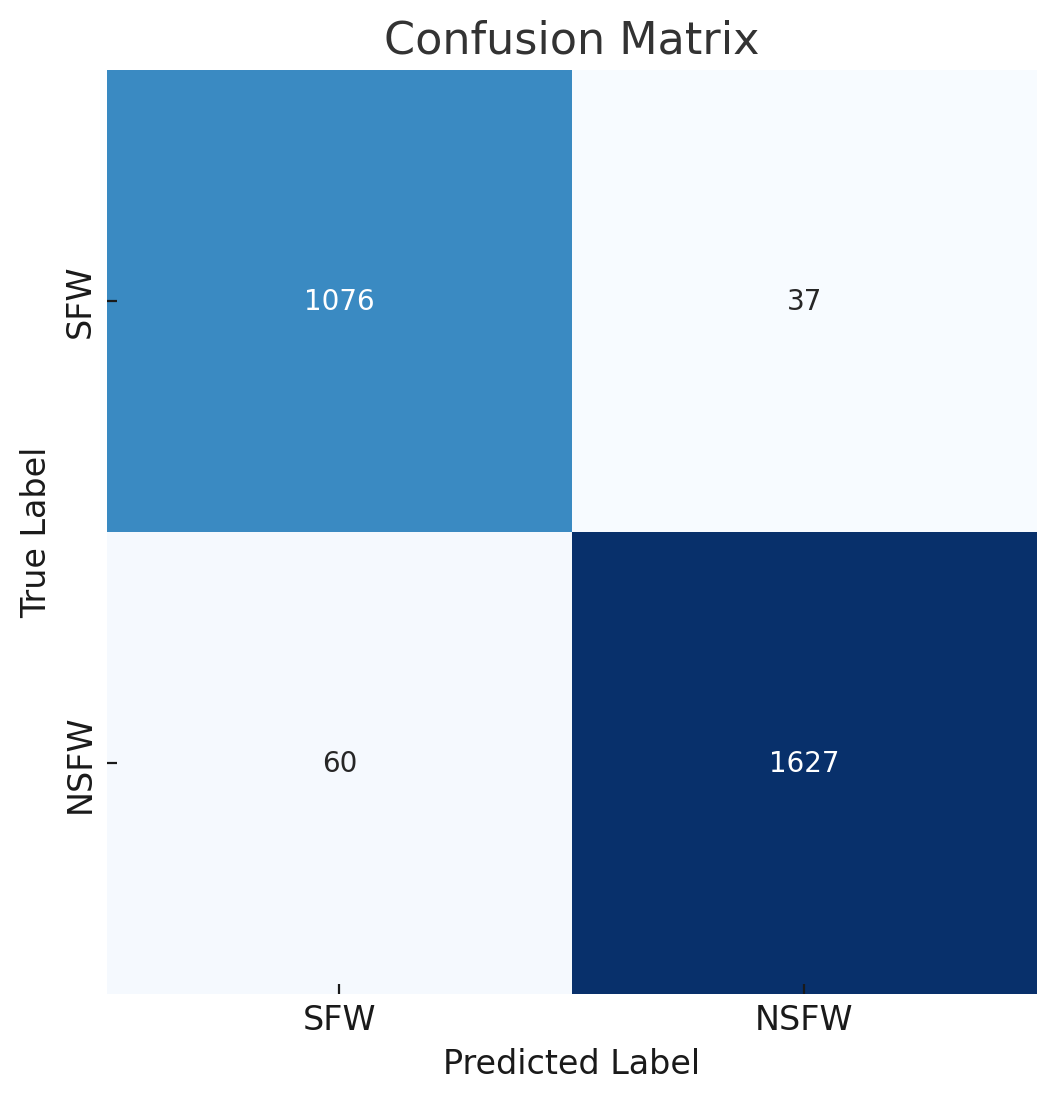
混淆矩阵(评估):
[1076 37]
[ 60 1627]
框架版本
- Transformers 4.36.2
- Evaluate 0.4.1
支持作者
如果您想支持作者,可以点击 这里。
🔧 技术细节
本模型基于视觉变换器架构,在预训练模型基础上进行微调。训练过程中使用了Adam优化器,学习率为3e - 05,经过1轮训练,在评估集上取得了较高的准确率和较低的损失值。但由于训练数据集中不包含生成图像,模型在生成图像上的表现有所下降。
📄 许可证
本模型使用的许可证为Apache 2.0许可证。
信息表格
| 属性 |
详情 |
| 模型类型 |
视觉变换器(ViT)微调模型 |
| 基础模型 |
google/vit-base-patch16-384 |
| 评估指标 |
损失值:0.0937;准确率:0.9654;AUC值:0.9948 |
| 训练超参数 |
学习率:3e - 05;训练批次大小:32;评估批次大小:32;随机种子:42;优化器:Adam(β=(0.9, 0.999),ε=1e - 08);训练轮数:1 |
| 框架版本 |
Transformers 4.36.2;Evaluate 0.4.1 |
| 许可证 |
Apache 2.0 |
{kind=link}
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)