🚀 Aero-1-Audio
Aero-1-Audio 是一款轻量级音频模型,擅长处理各类音频任务,包括语音识别、音频理解以及遵循音频指令。它基于 Qwen-2.5-1.5B 语言模型构建,在多个音频基准测试中表现出色,且参数效率高,即便与 Whisper、Qwen-2-Audio 和 Phi-4-Multimodal 等大型先进模型,或 ElevenLabs/Scribe 等商业服务相比也不逊色。此外,该模型仅使用 50k 小时的音频数据,在 16 个 H100 GPU 上仅用一天时间就完成了训练,这表明使用高质量且经过筛选的数据进行音频模型训练可以实现高效采样。同时,它能够对长达 15 分钟的连续音频输入进行准确的自动语音识别(ASR)和音频理解,而这一场景对其他模型来说仍是一项挑战。
- 开发者: [LMMs-Lab]
- 模型类型: [大语言模型(LLM)+ 音频编码器]
- 支持语言(自然语言处理): [英语]
- 许可证: [MIT]
🚀 快速开始
使用以下代码开始使用该模型。建议你通过以下命令安装 transformers:
python3 -m pip install transformers@git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
这是我们构建此模型时所使用的 transformers 版本。
💻 使用示例
基础用法
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
audios = [load_audio()]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True)[0])
高级用法
该模型支持使用 transformers 进行批量推理。示例代码如下:
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
def load_audio_2():
return librosa.load(librosa.ex("libri2"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
messages = [messages, messages]
audios = [load_audio(), load_audio_2()]
processor.tokenizer.padding_side="left"
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt", padding=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, pad_token_id=151643, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True))
📚 详细文档
训练数据
我们在此展示了数据混合的贡献。我们的监督微调(SFT)数据混合包含 20 多个公开可用的数据集,与其他模型的比较凸显了这些数据的轻量级特性。
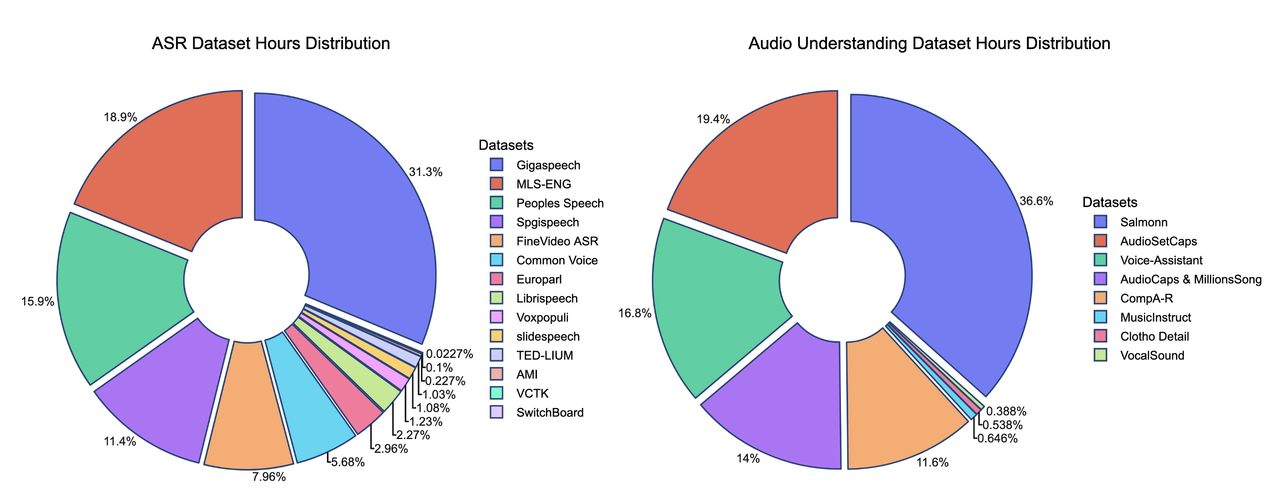
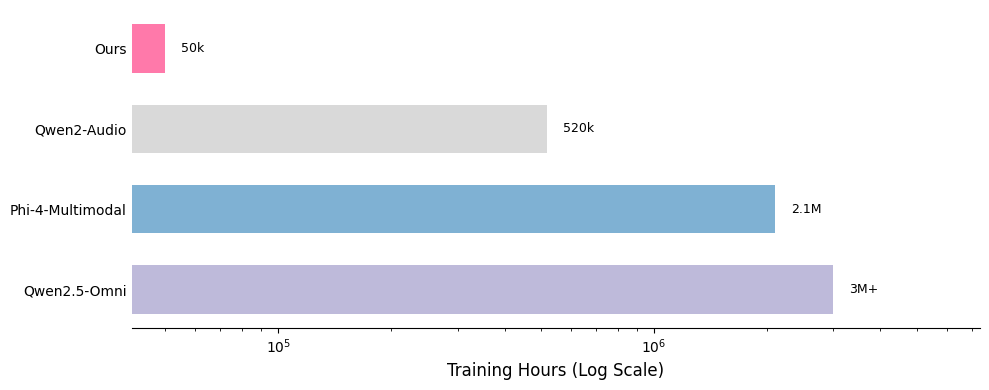
*部分训练数据集的时长是估算值,可能不完全准确
我们训练方法的关键优势之一在于数据的质量和数量。我们的训练数据集约由 50 亿个标记组成,相当于约 50,000 小时的音频。与 Qwen-Omni 和 Phi-4 等模型相比,我们的数据集小了 100 多倍,但我们的模型仍能取得有竞争力的性能。所有数据均来自公开可用的开源数据集,这凸显了我们训练方法的样本效率。以下是我们数据分布的详细细分,以及与其他模型的比较。
📄 许可证
本项目采用 MIT 许可证。
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)