Japanese Reranker Tiny V2
模型简介
该模型是一个日语文本重排序器,主要用于对检索到的文档进行重新排序以提高相关性。基于ModernBert架构,特别优化了在资源受限环境下的性能。
模型特点
轻量高效
仅3层架构,在CPU或Apple Silicon环境下也能以实用速度运行
资源友好
无需昂贵GPU资源即可提升RAG系统的精度
边缘设备兼容
适用于边缘设备部署或对延迟要求较高的生产环境
优化推理
支持Flash Attention 2加速和ONNX量化优化
模型能力
日语文本相关性评分
检索结果重排序
快速推理
使用案例
信息检索
文档检索优化
对搜索引擎返回的结果进行重新排序以提高相关性
在JQaRA数据集上达到0.6455的评分
问答系统
问答候选答案排序
对问答系统生成的候选答案进行相关性排序
在JSQuAD数据集上达到0.9608的评分
🚀 hotchpotch/japanese-reranker-tiny-v2
这是一个非常小巧且快速的日语重排器模型系列(v2),能够在多种环境下高效运行,有效提升RAG系统的精度。
🚀 快速开始
本模型运行需要 transformers 库的 v4.48 及以上版本。
pip install -U "transformers>=4.48.0" sentence-transformers sentencepiece
若GPU支持 Flash Attention 2,安装 flash-attn 库可实现高速推理。
pip install flash-attn --no-build-isolation
✨ 主要特性
小型重排器的特点
japanese-reranker-tiny-v2 和 japanese-reranker-xsmall-v2 是具备以下特性的小型重排器模型:
- 可在CPU或Apple硅芯片环境下以实用速度运行。
- 无需昂贵的GPU资源,就能提升RAG系统的精度。
- 适用于边缘设备部署以及对低延迟有要求的生产环境。
- 采用了基于 ModernBert 的 ruri-v3-pt-30m。
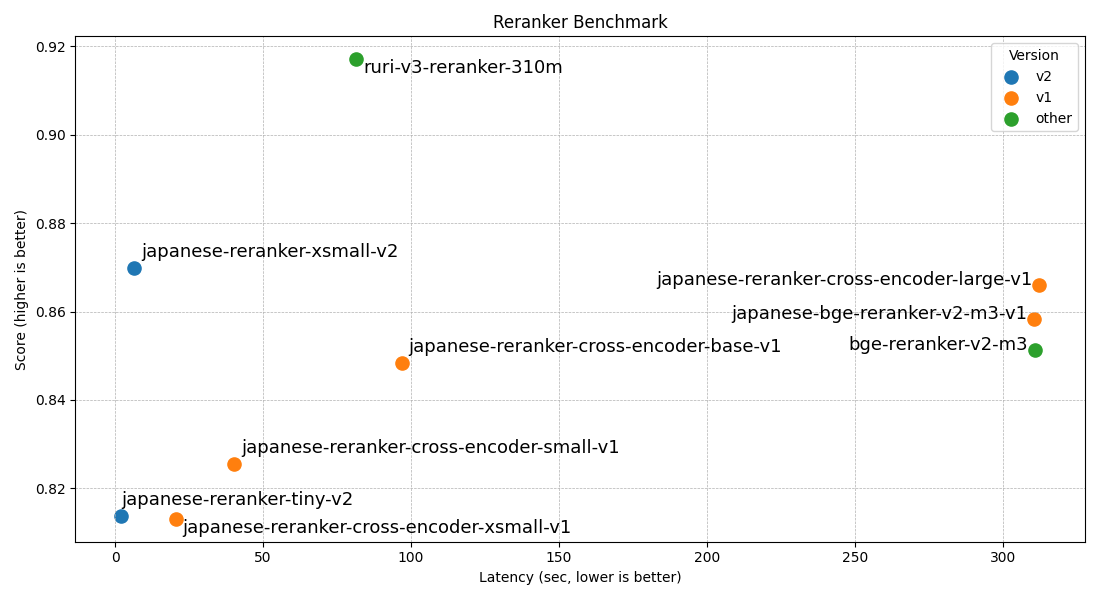
模型对比
| 模型名称 | 层数 | 隐藏层大小 | 得分(avg) | 速度(GPU) |
|---|---|---|---|---|
| hotchpotch/japanese-reranker-tiny-v2 | 3 | 256 | 0.8138 | 2.1s |
| hotchpotch/japanese-reranker-xsmall-v2 | 10 | 256 | 0.8699 | 6.5s |
| hotchpotch/japanese-reranker-cross-encoder-xsmall-v1 | 6 | 384 | 0.8131 | 20.5s |
| hotchpotch/japanese-reranker-cross-encoder-small-v1 | 12 | 384 | 0.8254 | 40.3s |
| hotchpotch/japanese-reranker-cross-encoder-base-v1 | 12 | 768 | 0.8484 | 96.8s |
| hotchpotch/japanese-reranker-cross-encoder-large-v1 | 24 | 1024 | 0.8661 | 312.2s |
| hotchpotch/japanese-bge-reranker-v2-m3-v1 | 24 | 1024 | 0.8584 | 310.6s |
评估结果
| 模型名称 | 平均分 | JQaRA | JaCWIR | MIRACL | JSQuAD |
|---|---|---|---|---|---|
| japanese-reranker-tiny-v2 | 0.8138 | 0.6455 | 0.9287 | 0.7201 | 0.9608 |
| japanese-reranker-xsmall-v2 | 0.8699 | 0.7403 | 0.9409 | 0.8206 | 0.9776 |
| japanese-reranker-cross-encoder-xsmall-v1 | 0.8131 | 0.6136 | 0.9376 | 0.7411 | 0.9602 |
| japanese-reranker-cross-encoder-small-v1 | 0.8254 | 0.6247 | 0.9390 | 0.7776 | 0.9604 |
| japanese-reranker-cross-encoder-base-v1 | 0.8484 | 0.6711 | 0.9337 | 0.8180 | 0.9708 |
| japanese-reranker-cross-encoder-large-v1 | 0.8661 | 0.7099 | 0.9364 | 0.8406 | 0.9773 |
| japanese-bge-reranker-v2-m3-v1 | 0.8584 | 0.6918 | 0.9372 | 0.8423 | 0.9624 |
| bge-reranker-v2-m3 | 0.8512 | 0.6730 | 0.9343 | 0.8374 | 0.9599 |
| ruri-v3-reranker-310m | 0.9171 | 0.8688 | 0.9506 | 0.8670 | 0.9820 |
推理速度
以下是对约15万对数据进行重排序时的推理速度结果(不包含分词时间的纯模型推理时间)。MPS(Apple硅芯片)和CPU测量使用M4 Max,GPU使用RTX5090。GPU处理使用了 flash-attention2。
| 模型名称 | 层数 | 隐藏层大小 | 速度(GPU) | 速度(MPS) | 速度(CPU) |
|---|---|---|---|---|---|
| japanese-reranker-tiny-v2 | 3 | 256 | 2.1s | 82s | 702s |
| japanese-reranker-xsmall-v2 | 10 | 256 | 6.5s | 303s | 2300s |
| japanese-reranker-cross-encoder-xsmall-v1 | 6 | 384 | 20.5s | ||
| japanese-reranker-cross-encoder-small-v1 | 12 | 384 | 40.3s | ||
| japanese-reranker-cross-encoder-base-v1 | 12 | 768 | 96.8s | ||
| japanese-reranker-cross-encoder-large-v1 | 24 | 1024 | 312.2s | ||
| japanese-bge-reranker-v2-m3-v1 | 24 | 1024 | 310.6s | ||
| bge-reranker-v2-m3 | 24 | 1024 | 310.7s | ||
| ruri-v3-reranker-310m | 25 | 768 | 81.4s |
推理速度基准测试所用的脚本在此。
💻 使用示例
SentenceTransformers
from sentence_transformers import CrossEncoder
import torch
MODEL_NAME = "hotchpotch/japanese-reranker-tiny-v2"
model = CrossEncoder(MODEL_NAME)
if model.device == "cuda" or model.device == "mps":
model.model.half()
query = "感動的な映画について"
passages = [
"深いテーマを持ちながらも、観る人の心を揺さぶる名作。登場人物の心情描写が秀逸で、ラストは涙なしでは見られない。",
"重要なメッセージ性は評価できるが、暗い話が続くので気分が落ち込んでしまった。もう少し明るい要素があればよかった。",
"どうにもリアリティに欠ける展開が気になった。もっと深みのある人間ドラマが見たかった。",
"アクションシーンが楽しすぎる。見ていて飽きない。ストーリーはシンプルだが、それが逆に良い。",
]
scores = model.predict(
[(query, passage) for passage in passages],
show_progress_bar=True,
)
print("Scores:", scores)
SentenceTransformers + onnx 的使用
若想在CPU环境或arm环境等中实现更快速的运行,可以使用 onnx 或量化模型。
pip install onnx onnxruntime accelerate optimum
from sentence_transformers import CrossEncoder
# oxxn のモデルを選ばないと model.onnx が自動で使われる
# onnx_filename = None
# 量子化された最適なモデルを使う場合は、onnx_filename にファイル名を指定する
# onnx_filename = "onnx/model_qint8_avx2.onnx"
onnx_filename = "onnx/model_qint8_arm64.onnx"
if onnx_filename:
model = CrossEncoder(
MODEL_NAME,
device="cpu",
backend="onnx",
model_kwargs={"file_name": onnx_filename},
)
else:
model = CrossEncoder(MODEL_NAME, device="cpu", backend="onnx")
...
HuggingFace transformers
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.nn import Sigmoid
def detect_device():
if torch.cuda.is_available():
return "cuda"
elif hasattr(torch, "mps") and torch.mps.is_available():
return "mps"
return "cpu"
device = detect_device()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME)
model.to(device)
model.eval()
if device == "cuda":
model.half()
query = "感動的な映画について"
passages = [
"深いテーマを持ちながらも、観る人の心を揺さぶる名作。登場人物の心情描写が秀逸で、ラストは涙なしでは見られない。",
"重要なメッセージ性は評価できるが、暗い話が続くので気分が落ち込んでしまった。もう少し明るい要素があればよかった。",
"どうにもリアリティに欠ける展開が気になった。もっと深みのある人間ドラマが見たかった。",
"アクションシーンが楽しすぎる。見ていて飽きない。ストーリーはシンプルだが、それが逆に良い。",
]
inputs = tokenizer(
[(query, passage) for passage in passages],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
inputs = {k: v.to(device) for k, v in inputs.items()}
logits = model(**inputs).logits
activation = Sigmoid()
scores = activation(logits).squeeze().tolist()
print("Scores:", scores)
📚 详细文档
关于重排器以及技术报告、评估等内容,请参考以下链接:
- とても小さく速く実用的な日本語リランカー japanese-reranker-tiny,xsmall v2 を公開
- 日本語最高性能のRerankerをリリース / そもそも Reranker とは?
- 日本語 Reranker 作成のテクニカルレポート
📄 许可证
MIT License
Jina Embeddings V3
Jina Embeddings V3 是一个多语言句子嵌入模型,支持超过100种语言,专注于句子相似度和特征提取任务。
文本嵌入 Transformers 支持多种语言
Transformers 支持多种语言
J
jinaai
3.7M
911
Ms Marco MiniLM L6 V2
Apache-2.0
基于MS Marco段落排序任务训练的交叉编码器模型,用于信息检索中的查询-段落相关性评分
文本嵌入 英语
M
cross-encoder
2.5M
86
Opensearch Neural Sparse Encoding Doc V2 Distill
Apache-2.0
基于蒸馏技术的稀疏检索模型,专为OpenSearch优化,支持免推理文档编码,在搜索相关性和效率上优于V1版本
文本嵌入 Transformers 英语
O
opensearch-project
1.8M
7
Sapbert From PubMedBERT Fulltext
Apache-2.0
基于PubMedBERT的生物医学实体表征模型,通过自对齐预训练优化语义关系捕捉
文本嵌入 英语
S
cambridgeltl
1.7M
49
Gte Large
MIT
GTE-Large 是一个强大的句子转换器模型,专注于句子相似度和文本嵌入任务,在多个基准测试中表现出色。
文本嵌入 英语
G
thenlper
1.5M
278
Gte Base En V1.5
Apache-2.0
GTE-base-en-v1.5 是一个英文句子转换器模型,专注于句子相似度任务,在多个文本嵌入基准测试中表现优异。
文本嵌入 Transformers 支持多种语言
G
Alibaba-NLP
1.5M
63
Gte Multilingual Base
Apache-2.0
GTE Multilingual Base 是一个多语言的句子嵌入模型,支持超过50种语言,适用于句子相似度计算等任务。
文本嵌入 Transformers 支持多种语言
G
Alibaba-NLP
1.2M
246
Polybert
polyBERT是一个化学语言模型,旨在实现完全由机器驱动的超快聚合物信息学。它将PSMILES字符串映射为600维密集指纹,以数值形式表示聚合物化学结构。
文本嵌入 Transformers
P
kuelumbus
1.0M
5
Bert Base Turkish Cased Mean Nli Stsb Tr
Apache-2.0
基于土耳其语BERT的句子嵌入模型,专为语义相似度任务优化
文本嵌入 Transformers 其他
B
emrecan
1.0M
40
GIST Small Embedding V0
MIT
基于BAAI/bge-small-en-v1.5模型微调的文本嵌入模型,通过MEDI数据集与MTEB分类任务数据集训练,优化了检索任务的查询编码能力。
文本嵌入 Safetensors 英语
Safetensors 英语
Safetensors 英语G
avsolatorio
945.68k
29
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文