模型简介
模型特点
模型能力
使用案例
🚀 Typhoon-OCR-7B:双语文档解析模型
Typhoon-OCR-7B 是一款专门为泰语和英语的现实文档解析而构建的双语模型。它受到了类似 olmOCR 模型的启发,并基于 Qwen2.5-VL-Instruction 开发。该模型能够高效处理多种类型的文档,为用户提供准确的文档解析服务。
点击下方链接体验更多:
⚠️ 重要提示
此模型仅适用于特定的提示,使用其他提示可能无法正常工作。
🚀 快速开始
环境准备
确保你已经安装了必要的依赖库,你可以使用以下命令安装 typhoon-ocr 包:
pip install typhoon-ocr
代码示例
以下是一个简单的使用示例,展示了如何使用 typhoon-ocr 包进行文档解析:
from typhoon_ocr import ocr_document
# 请设置环境变量 TYPHOON_OCR_API_KEY 或 OPENAI_API_KEY 以使用此函数
markdown = ocr_document("test.png")
print(markdown)
✨ 主要特性
支持现实文档类型
1. 结构化文档
支持金融报告、学术论文、书籍、政府表格等结构化文档。输出格式丰富多样:
- 普通文本采用 Markdown 格式。
- 表格采用 HTML 格式(包括合并单元格和复杂布局)。
- 图表和图形使用
<figure>标签进行结构化视觉理解。
每个图形都会经过多层解释:
- 观察:检测风景、建筑、人物、标志和嵌入式文本等元素。
- 上下文分析:推断位置、事件或文档部分等上下文信息。
- 文本识别:提取和解释泰语或英语的嵌入式文本(如图表标签、标题)。
- 艺术与结构分析:捕捉布局风格、图表类型或设计选择,以体现文档的基调。
- 最终总结:将所有见解整合到结构化的图形描述中,用于总结和检索等任务。
2. 布局复杂和非正式文档
支持收据、菜单、门票、信息图表等布局复杂和非正式文档。输出格式为带有嵌入式表格和布局感知结构的 Markdown。
性能表现
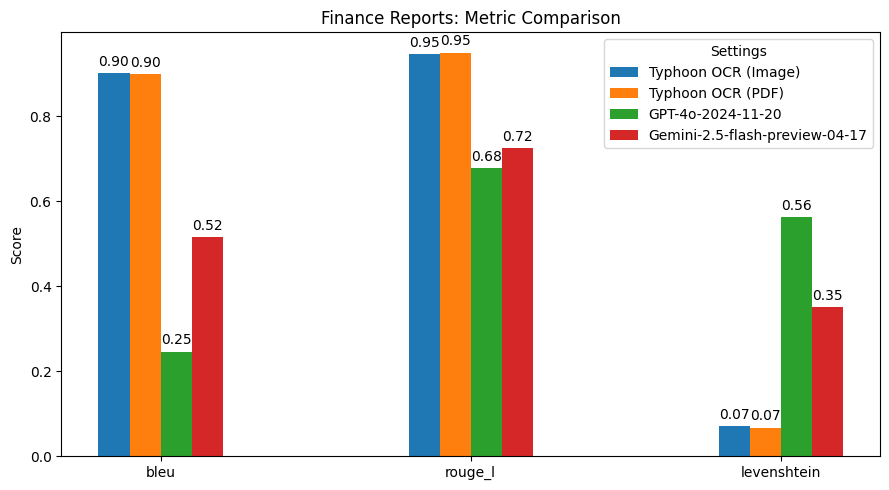
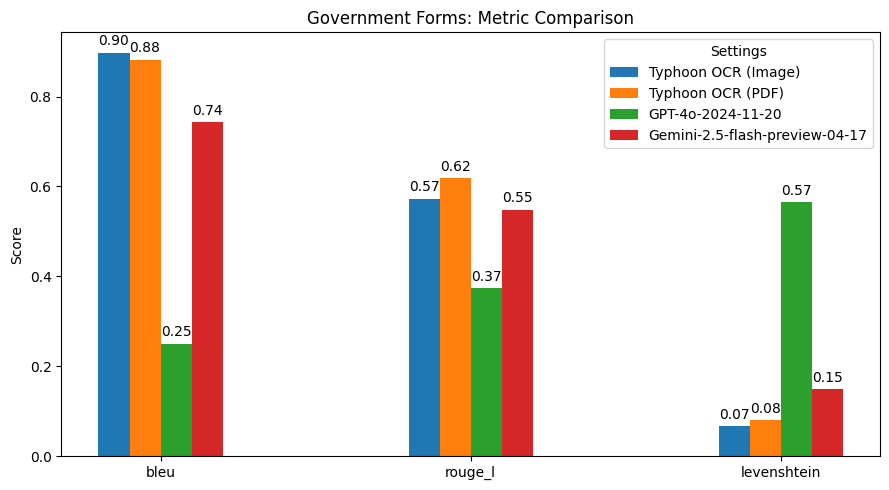
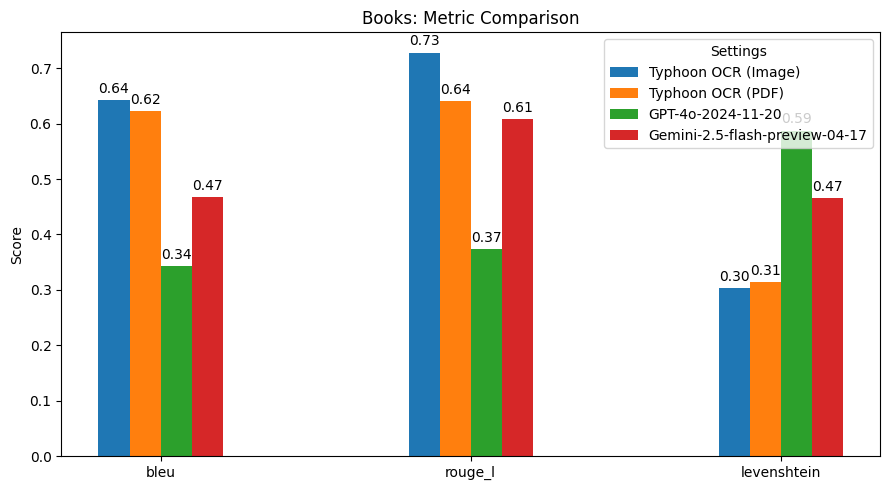
总结发现
Typhoon OCR 在泰语文档理解方面优于 GPT - 4o 和 Gemini 2.5 Flash,尤其在处理复杂布局和混合语言内容的文档时表现出色。不过,在泰语书籍基准测试中,由于嵌入式图形的高频和多样性,性能略有下降。这也指出了未来的改进方向,即增强模型的图像理解能力。此版本主要专注于实现高质量的英语和泰语文本 OCR,未来版本可能会扩展到更高级的图像分析和图形解释。
💻 使用示例
基础用法
from typhoon_ocr import ocr_document
# 请设置环境变量 TYPHOON_OCR_API_KEY 或 OPENAI_API_KEY 以使用此函数
markdown = ocr_document("test.png")
print(markdown)
高级用法
使用 API 进行推理
from typing import Callable
from openai import OpenAI
from PIL import Image
from typhoon_ocr.ocr_utils import render_pdf_to_base64png, get_anchor_text
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
def get_prompt(prompt_name: str) -> Callable[[str], str]:
"""
Fetches the system prompt based on the provided PROMPT_NAME.
:param prompt_name: The identifier for the desired prompt.
:return: The system prompt as a string.
"""
return PROMPTS_SYS.get(prompt_name, lambda x: "Invalid PROMPT_NAME provided.")
# Render the first page to base64 PNG and then load it into a PIL image.
image_base64 = render_pdf_to_base64png(filename, page_num, target_longest_image_dim=1800)
image_pil = Image.open(BytesIO(base64.b64decode(image_base64)))
# Extract anchor text from the PDF (first page)
anchor_text = get_anchor_text(filename, page_num, pdf_engine="pdfreport", target_length=8000)
# Retrieve and fill in the prompt template with the anchor_text
prompt_template_fn = get_prompt(task_type)
PROMPT = prompt_template_fn(anchor_text)
messages = [{
"role": "user",
"content": [
{"type": "text", "text": PROMPT},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_base64}"}},
],
}]
# send messages to openai compatible api
openai = OpenAI(base_url="https://api.opentyphoon.ai/v1", api_key="TYPHOON_API_KEY")
response = openai.chat.completions.create(
model="typhoon-ocr-preview",
messages=messages,
max_tokens=16384,
temperature=0.1,
top_p=0.6,
extra_body={
"repetition_penalty": 1.2,
},
)
text_output = response.choices[0].message.content
print(text_output)
使用本地模型(需要 GPU)
# Initialize the model
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("scb10x/typhoon-ocr-7b", torch_dtype=torch.bfloat16 ).eval()
processor = AutoProcessor.from_pretrained("scb10x/typhoon-ocr-7b")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Apply the chat template and processor
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# Generate the output
output = model.generate(
**inputs,
temperature=0.1,
max_new_tokens=12000,
num_return_sequences=1,
repetition_penalty=1.2,
do_sample=True,
)
# Decode the output
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(text_output[0])
📚 详细文档
提示信息
此模型仅适用于以下特定提示,其中 {base_text} 指的是使用 typhoon-ocr 包中的 get_anchor_text 函数从 PDF 元数据中提取的信息。使用其他提示可能无法正常工作。
PROMPTS_SYS = {
"default": lambda base_text: (f"Below is an image of a document page along with its dimensions. "
f"Simply return the markdown representation of this document, presenting tables in markdown format as they naturally appear.\n"
f"If the document contains images, use a placeholder like dummy.png for each image.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"),
"structure": lambda base_text: (
f"Below is an image of a document page, along with its dimensions and possibly some raw textual content previously extracted from it. "
f"Note that the text extraction may be incomplete or partially missing. Carefully consider both the layout and any available text to reconstruct the document accurately.\n"
f"Your task is to return the markdown representation of this document, presenting tables in HTML format as they naturally appear.\n"
f"If the document contains images or figures, analyze them and include the tag <figure>IMAGE_ANALYSIS</figure> in the appropriate location.\n"
f"Your final output must be in JSON format with a single key `natural_text` containing the response.\n"
f"RAW_TEXT_START\n{base_text}\nRAW_TEXT_END"
),
}
生成参数
建议使用以下生成参数。由于这是一个 OCR 模型,不建议使用较高的温度。请确保温度设置为 0 或 0.1,不要更高。
temperature=0.1,
top_p=0.6,
repetition_penalty: 1.2
🔧 技术细节
模型信息
| 属性 | 详情 |
|---|---|
| 模型类型 | 基于 Qwen2.5-VL-Instruction 的双语文档解析模型 |
| 支持语言 | 英语、泰语 |
| 标签 | OCR、视觉语言、文档理解、多语言 |
预期用途和局限性
这是一个特定任务的模型,仅适用于提供的提示。它不包含任何护栏或 VQA 功能。由于大语言模型(LLM)的性质,可能会出现一定程度的幻觉。建议开发人员在特定用例的上下文中仔细评估这些风险。
📄 许可证
文档中未提及相关许可证信息。
🔗 相关链接
📖 引用
如果您发现 Typhoon2 对您的工作有帮助,请使用以下 BibTeX 格式进行引用:
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)