模型简介
模型特点
模型能力
使用案例
🚀 deberta-v3-base-zeroshot-v2.0
本项目的 deberta-v3-base-zeroshot-v2.0 模型专注于零样本分类任务,可在无训练数据的情况下进行高效分类,支持GPU和CPU运行。该模型系列的部分模型使用了完全商业友好的数据进行训练,适用于有严格许可要求的用户。
🚀 快速开始
本模型可通过Hugging Face的pipeline进行零样本分类任务,无需训练数据,即可在GPU和CPU上运行。下面是一个简单的使用示例:
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
✨ 主要特性
- 零样本分类能力:无需训练数据,即可完成分类任务。
- 跨平台运行:支持在GPU和CPU上运行。
- 商业友好数据训练:部分模型使用完全商业友好的数据进行训练,满足严格许可要求。
- 通用分类任务:可将任何分类任务转化为判断假设是否为“真”的任务。
📚 详细文档
zeroshot-v2.0系列模型概述
此系列模型专为使用Hugging Face管道进行高效零样本分类而设计。这些模型无需训练数据即可进行分类,并且可以在GPU和CPU上运行。最新零样本分类器的概述可在零样本分类器集合中找到。
zeroshot-v2.0系列模型的主要更新在于,部分模型针对有严格许可要求的用户,使用完全商业友好的数据进行训练。这些模型可以完成一项通用分类任务:给定一段文本,判断一个假设是“真”还是“非真”(entailment与not_entailment)。此任务格式基于自然语言推理任务(NLI),Hugging Face管道可以将任何分类任务重新表述为该任务。
训练数据
名称中带有“-c”的模型在两种完全商业友好的数据上进行训练:
- 合成数据:使用Mixtral-8x7B-Instruct-v0.1生成。首先与Mistral-large对话,为25种职业创建了500多个不同的文本分类任务列表,并手动整理数据。然后使用这些种子数据,通过Mixtral-8x7B-Instruct-v0.1为这些任务生成了数十万个文本。最终使用的数据集可在synthetic_zeroshot_mixtral_v0.1数据集中的
mixtral_written_text_for_tasks_v4子集中找到。数据整理经过多次迭代,未来还将进一步改进。 - 两个商业友好的NLI数据集:(MNLI,FEVER-NLI)。添加这些数据集是为了提高模型的泛化能力。
名称中没有“-c”的模型还包括了更广泛的训练数据,这些数据的许可范围也更广,如ANLI、WANLI、LingNLI,以及此列表中used_in_v1.1==True的所有数据集。
何时使用哪种模型
- deberta-v3-零样本与roberta-零样本:deberta-v3的性能明显优于roberta,但速度稍慢。roberta与Hugging Face的生产推理TEI容器和闪存注意力直接兼容,这些容器适用于生产用例。简而言之,为了追求准确性,可使用deberta-v3模型;如果关注生产推理速度,可以考虑使用roberta模型(例如在TEI容器和HF推理端点中)。
- 商业用例:名称中带有“
-c”的模型保证仅使用商业友好的数据进行训练。没有“-c”的模型使用了更多数据,性能更好,但包含了非商业许可的数据。关于这些训练数据是否会影响训练模型的许可,法律意见存在分歧。对于有严格法律要求的用户,建议使用名称中带有“-c”的模型。 - 多语言/非英语用例:使用bge-m3-zeroshot-v2.0或bge-m3-zeroshot-v2.0-c。请注意,多语言模型的性能不如仅支持英语的模型。因此,您也可以先使用EasyNMT等库将文本机器翻译为英语,然后将任何仅支持英语的模型应用于翻译后的数据。如果您的团队不精通数据中的所有语言,机器翻译也便于进行验证。
- 上下文窗口:
bge-m3模型最多可以处理8192个标记,其他模型最多可以处理512个标记。请注意,较长的文本输入会使模型变慢并降低性能,因此如果您只处理最多400个单词/1页的文本,建议使用deberta模型以获得更好的性能。
最新的模型更新信息可在零样本分类器集合中查看。
可重复性
复现代码可在以下目录中找到:https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
局限性和偏差
该模型仅能处理文本分类任务。偏差可能来自基础模型、人类NLI训练数据以及Mixtral生成的合成数据。
灵活使用和“提示”
您可以通过更改零样本管道的hypothesis_template来制定自己的假设。类似于大型语言模型的“提示工程”,您可以测试不同的hypothesis_template表述和语言化类别,以提高性能。
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# 表述1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# 表述2,根据您的用例而定
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# 测试不同的表述
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # 更改模型标识符
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
💻 使用示例
基础用法
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
高级用法
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# 表述1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# 表述2,根据您的用例而定
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# 测试不同的表述
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # 更改模型标识符
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
🔧 技术细节
评估指标
模型在28个不同的文本分类任务上使用f1_macro指标进行评估。主要参考点是facebook/bart-large-mnli,在撰写本文时(2024年4月3日),它是最常用的商业友好型零样本分类器。
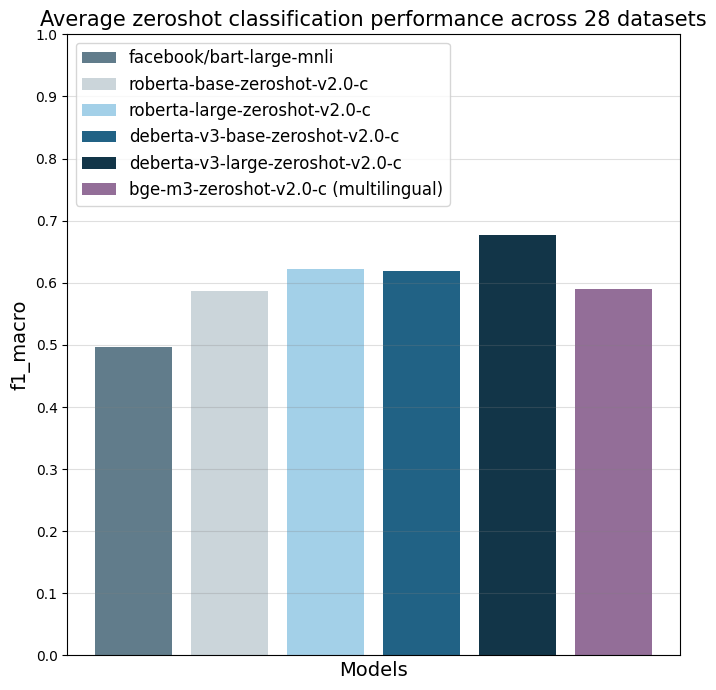
这些数字表示零样本性能,因为训练数据中未添加这些数据集的数据。请注意,名称中没有“-c”的模型进行了两次评估:一次不使用这28个数据集中的任何数据,以测试纯零样本性能(相应列中的第一个数字);最后一次包括每个数据集每个类别最多500个训练数据点(列中括号内的第二个数字,“fewshot”)。没有模型在测试数据上进行训练。
不同数据集的详细信息可在此处找到:https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
📄 许可证
基础模型根据MIT许可证发布。训练数据的许可证因模型而异,请参见上文。
📖 引用
此模型是本文所述研究的扩展。
如果您在学术上使用此模型,请引用:
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
合作建议或问题咨询
如果您有问题或合作建议,请通过moritz{at}huggingface{dot}co联系我,或在LinkedIn上与我交流。
灵活使用和“提示”
您可以通过更改零样本管道的hypothesis_template来制定自己的假设。类似于大型语言模型的“提示工程”,您可以测试不同的hypothesis_template表述和语言化类别,以提高性能。
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# 表述1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# 表述2,根据您的用例而定
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# 测试不同的表述
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # 更改模型标识符
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
📋 模型信息表格
| 属性 | 详情 |
|---|---|
| 模型类型 | 用于零样本分类的deberta-v3-base模型 |
| 训练数据 | 名称中带有“-c”的模型使用两种完全商业友好的数据进行训练:一是使用Mixtral-8x7B-Instruct-v0.1生成的合成数据;二是两个商业友好的NLI数据集(MNLI,FEVER-NLI)。名称中没有“-c”的模型还包括更广泛的训练数据,许可范围也更广。 |
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)