🚀 42dot_LLM-PLM-1.3B
42dot LLM-PLM 是由 42dot 42dot LLM (大语言模型)的一部分。42dot LLM-PLM 使用韩语和英语文本语料库进行预训练,可作为多种韩语和英语自然语言任务的基础语言模型。本仓库包含该模型的 13 亿参数版本。
📚 模型描述
超参数
42dot LLM-PLM 基于类似于 LLaMA 2 的 Transformer 解码器架构构建,其超参数如下:
参数
层数
注意力头数
隐藏层大小
前馈网络大小
13 亿
24
32
2048
5632
预训练
预训练大约花费了 49000 GPU 小时(NVIDIA A100)。相关设置如下:
参数
全局批次大小*
初始学习率
训练迭代次数*
最大长度*
权重衰减
13 亿
400 万
4E - 4
140 万亿
4096
0.1
(* 单位:词元)
预训练数据集
我们使用了一组公开可用的文本语料库,包括:
分词器
分词器基于字节级 BPE 算法。我们使用预训练语料库的一个子集从头开始训练其词汇表。为构建该子集,分别从韩语和英语语料库中采样了 1000 万个文档。最终的词汇表大小约为 5 万个。
零样本评估
我们在多种韩语和英语学术基准测试中对 42dot LLM-PLM 进行了评估。所有结果均使用 lm - eval - harness 和 Hugging Face Hub 上发布的模型获得。
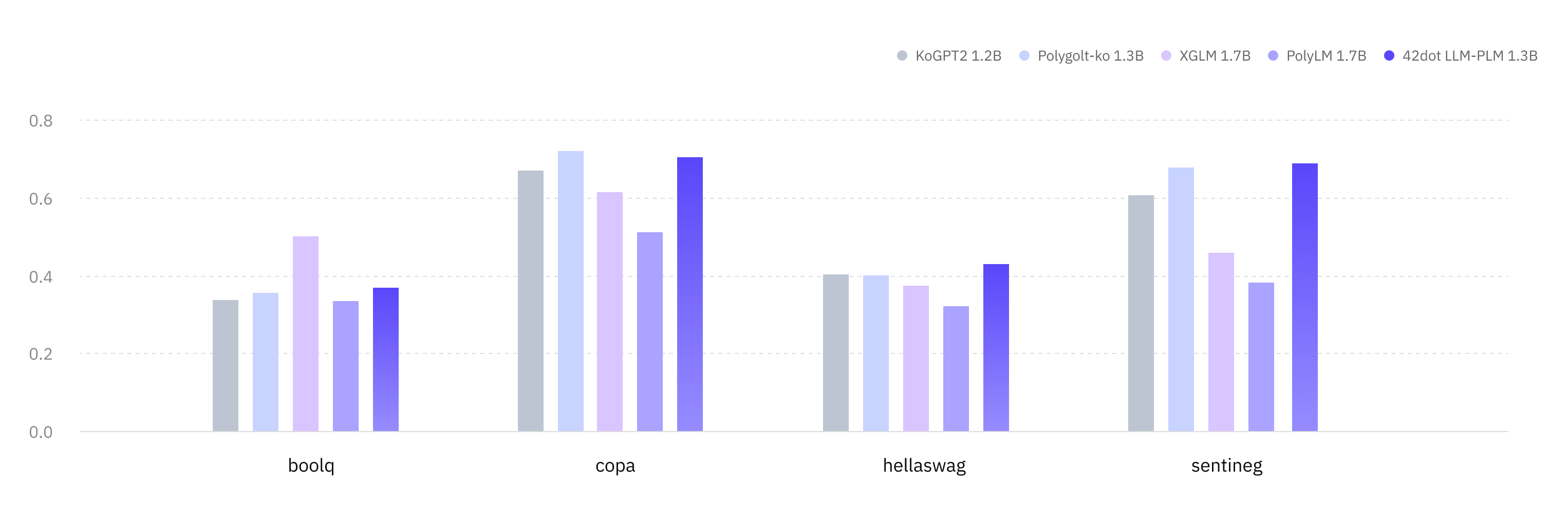
韩语(KOBEST)
任务 / 宏 F1 值
KoGPT2 Polyglot - Ko XGLM PolyLM 42dot LLM - PLM
boolq
0.337
0.355
0.502 0.334
0.369
copa
0.67
0.721 0.616
0.513
0.704
hellaswag
0.404
0.401
0.374
0.321
0.431
sentineg
0.606
0.679
0.46
0.382
0.69
平均 0.504
0.539
0.488
0.388
0.549
英语
任务 / 指标
MPT
OPT
XGLM
PolyLM
42dot LLM - PLM
anli_r1/acc
0.309
0.341 0.334
0.336
0.325
anli_r2/acc
0.334
0.339
0.331
0.314
0.34
anli_r3/acc
0.33
0.336
0.333
0.339 0.333
arc_challenge/acc
0.268
0.234
0.21
0.198
0.288
arc_challenge/acc_norm
0.291
0.295
0.243
0.256
0.317
arc_easy/acc
0.608
0.571
0.537
0.461
0.628
arc_easy/acc_norm
0.555
0.51
0.479
0.404
0.564
boolq/acc
0.517
0.578
0.585
0.617
0.624
hellaswag/acc
0.415
0.415
0.362
0.322
0.422
hellaswag/acc_norm
0.532
0.537
0.458
0.372
0.544
openbookqa/acc
0.238 0.234
0.17
0.166
0.222
openbookqa/acc_norm
0.334
0.334
0.298
0.334
0.34
piqa/acc
0.714
0.718
0.697
0.667
0.725
piqa/acc_norm
0.72
0.724
0.703
0.649
0.727
record/f1
0.84
0.857 0.775
0.681
0.848
record/em
0.832
0.849 0.769
0.674
0.839
rte/acc
0.541
0.523
0.559 0.513
0.542
truthfulqa_mc/mc1
0.224
0.237
0.215
0.251 0.236
truthfulqa_mc/mc2
0.387
0.386
0.373
0.428 0.387
wic/acc
0.498
0.509 0.503
0.5
0.502
winogrande/acc
0.574
0.595 0.55
0.519
0.583
平均 0.479
0.482
0.452
0.429
0.492
⚠️ 局限性与伦理考量
42dot LLM-PLM 存在一些其他大语言模型(LLM)常见的局限性。例如,由于 42dot LLM-PLM 也会出现 幻觉现象 ,它可能会生成虚假和误导性内容。此外,由于使用了网络可用的训练数据,42dot LLM-PLM 可能会生成有毒、有害和有偏见的内容。我们强烈建议 42dot LLM-PLM 用户了解这些局限性,并采取必要措施来减轻这些问题。
📢 免责声明
42dot LLM 系列(“42dot LLM”)生成的内容不一定反映 42dot 公司(“42dot”)的观点或意见。42dot 对因使用 42dot LLM 及其生成的内容而产生的任何直接、间接、暗示、惩罚性、特殊、偶然或其他后果性损害,不承担任何责任。
📄 许可证
42dot LLM-PLM 采用知识共享署名 - 非商业性使用 4.0 国际许可协议(CC BY - NC 4.0)。
📝 引用
@misc{42dot2023llm,
title={42dot LLM: A Series of Large Language Model by 42dot},
author={42dot Inc.},
year={2023},
url = {https://github.com/42dot/42dot_LLM},
version = {1.0.0},
}

 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)