Jina Embeddings V2 Base Zh
模型简介
模型特点
模型能力
使用案例
🚀 jina-embeddings-v2-base-zh
jina-embeddings-v2-base-zh 是由 Jina AI 训练的文本嵌入模型,支持中英双语,具备 8192 的序列长度。它能为单语言和跨语言应用提供高质量的文本嵌入,可用于文档检索等多种场景。
🚀 快速开始
使用 jina-embeddings-v2-base-zh 最简单的方法是使用 Jina AI 的 Embedding API。
✨ 主要特性
- 双语支持:支持中文和英文两种语言,能处理中英混合输入,无语言偏向性。
- 长序列处理:支持长达 8192 的序列长度,可对较长文本进行编码。
- 高性能架构:基于 BERT 架构(JinaBERT),并应用了 ALiBi 以支持更长序列。
- 多模型选择:除了
jina-embeddings-v2-base-zh,还提供多种不同参数和语言支持的嵌入模型。
📦 安装指南
使用该模型前,你需要安装 transformers 库:
!pip install transformers
若要使用 sentence-transformers 库,可通过以下命令安装:
!pip install -U sentence-transformers
💻 使用示例
基础用法
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['How is the weather today?', '今天天气怎么样?']
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh')
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
高级用法
使用 encode 函数
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', '今天天气怎么样?'])
print(cos_sim(embeddings[0], embeddings[1]))
控制输入序列长度
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
使用 sentence-transformers 库
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-zh",
trust_remote_code=True
)
# 控制输入序列长度,最大为 8192
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'今天天气怎么样?'
])
print(cos_sim(embeddings[0], embeddings[1]))
📚 详细文档
预期用途与模型信息
jina-embeddings-v2-base-zh 是一个支持中英双语的文本嵌入模型,支持 8192 的序列长度。它基于 BERT 架构(JinaBERT),该架构支持 ALiBi 的对称双向变体,以允许更长的序列长度。该模型专为单语言和跨语言应用的高性能而设计,并经过专门训练以支持中英混合输入,无语言偏向性。
数据与参数
数据和训练细节请参考 技术报告。
替代使用方式
- 托管 SaaS:可在 Jina AI 的 Embedding API 上获取免费密钥开始使用。
- 私有高性能部署:可从模型套件中选择模型,并在 AWS Sagemaker 上进行部署。
在 RAG 中使用 Jina 嵌入
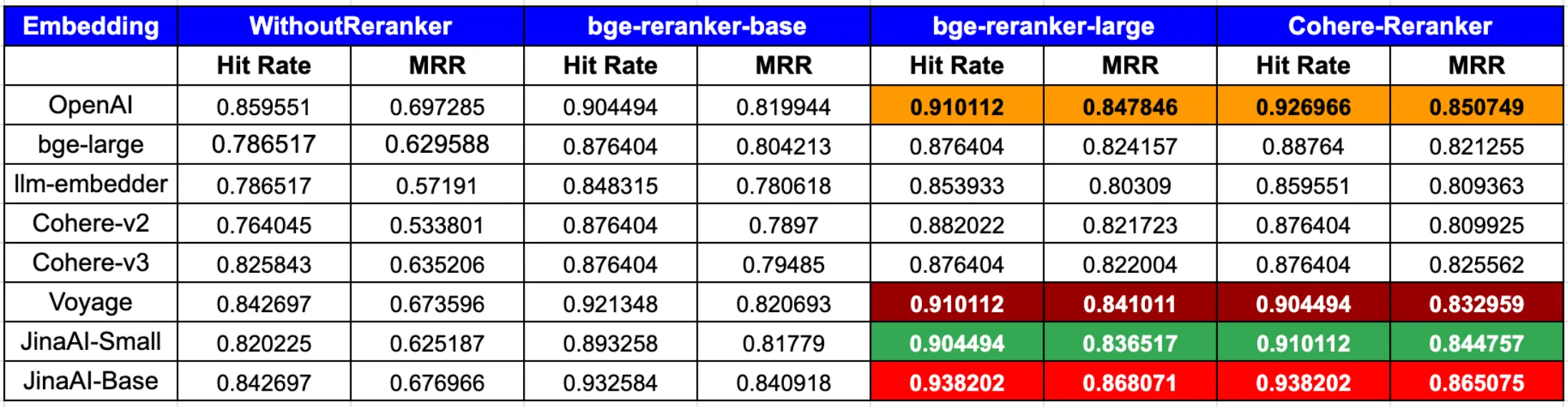
根据 LLamaIndex 的最新博客文章:
综上所述,为了在命中率和 MRR 方面达到最佳性能,将 OpenAI 或 JinaAI-Base 嵌入与 CohereRerank/bge-reranker-large 重排器结合使用效果显著。
故障排除
模型代码加载失败
如果在调用 AutoModel.from_pretrained 或通过 SentenceTransformer 类初始化模型时忘记传递 trust_remote_code=True 标志,将收到模型权重无法初始化的错误。这是因为 transformers 库会回退到创建默认的 BERT 模型,而不是 jina 嵌入模型:
Some weights of the model checkpoint at jinaai/jina-embeddings-v2-base-zh were not used when initializing BertModel: ['encoder.layer.2.mlp.layernorm.weight', 'encoder.layer.3.mlp.layernorm.weight', 'encoder.layer.10.mlp.wo.bias', 'encoder.layer.5.mlp.wo.bias', 'encoder.layer.2.mlp.layernorm.bias', 'encoder.layer.1.mlp.gated_layers.weight', 'encoder.layer.5.mlp.gated_layers.weight', 'encoder.layer.8.mlp.layernorm.bias', ...
用户未登录 Huggingface
该模型仅在 受限访问 下可用,这意味着你需要登录 Huggingface 才能加载它。如果你收到以下错误,需要提供访问令牌,可以使用 huggingface-cli 或通过环境变量提供令牌:
OSError: jinaai/jina-embeddings-v2-base-zh is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo with `use_auth_token` or log in with `huggingface-cli login` and pass `use_auth_token=True`.
🔧 技术细节
为什么使用平均池化?
平均池化 会从模型输出中获取所有标记嵌入,并在句子/段落级别对它们进行平均。实践证明,这是生成高质量句子嵌入最有效的方法。我们提供了一个 encode 函数来处理这个问题。
📄 许可证
该模型使用 apache-2.0 许可证。
📊 评估结果
| 任务类型 | 数据集 | 指标 | 值 |
|---|---|---|---|
| STS | C-MTEB/AFQMC | cos_sim_pearson | 48.51403119231363 |
| STS | C-MTEB/AFQMC | cos_sim_spearman | 50.5928547846445 |
| STS | C-MTEB/AFQMC | euclidean_pearson | 48.750436310559074 |
| STS | C-MTEB/AFQMC | euclidean_spearman | 50.50950238691385 |
| STS | C-MTEB/AFQMC | manhattan_pearson | 48.7866189440328 |
| STS | C-MTEB/AFQMC | manhattan_spearman | 50.58692402017165 |
| STS | C-MTEB/ATEC | cos_sim_pearson | 50.25985700105725 |
| STS | C-MTEB/ATEC | cos_sim_spearman | 51.28815934593989 |
| STS | C-MTEB/ATEC | euclidean_pearson | 52.70329248799904 |
| STS | C-MTEB/ATEC | euclidean_spearman | 50.94101139559258 |
| STS | C-MTEB/ATEC | manhattan_pearson | 52.6647237400892 |
| STS | C-MTEB/ATEC | manhattan_spearman | 50.922441325406176 |
| Classification | mteb/amazon_reviews_multi | accuracy | 34.944 |
| Classification | mteb/amazon_reviews_multi | f1 | 34.06478860660109 |
| STS | C-MTEB/BQ | cos_sim_pearson | 65.15667035488342 |
| STS | C-MTEB/BQ | cos_sim_spearman | 66.07110142081 |
| STS | C-MTEB/BQ | euclidean_pearson | 60.447598102249714 |
| STS | C-MTEB/BQ | euclidean_spearman | 61.826575796578766 |
| STS | C-MTEB/BQ | manhattan_pearson | 60.39364279354984 |
| STS | C-MTEB/BQ | manhattan_spearman | 61.78743491223281 |
| Clustering | C-MTEB/CLSClusteringP2P | v_measure | 39.96714175391701 |
| Clustering | C-MTEB/CLSClusteringS2S | v_measure | 38.39863566717934 |
| Reranking | C-MTEB/CMedQAv1-reranking | map | 83.63680381780644 |
| Reranking | C-MTEB/CMedQAv1-reranking | mrr | 86.16476190476192 |
| Reranking | C-MTEB/CMedQAv2-reranking | map | 83.74350667859487 |
| Reranking | C-MTEB/CMedQAv2-reranking | mrr | 86.10388888888889 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_1 | 22.072 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_10 | 32.942 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_100 | 34.768 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_1000 | 34.902 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_3 | 29.357 |
| Retrieval | C-MTEB/CmedqaRetrieval | map_at_5 | 31.236000000000004 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_1 | 34.259 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_10 | 41.957 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_100 | 42.982 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_1000 | 43.042 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_3 | 39.722 |
| Retrieval | C-MTEB/CmedqaRetrieval | mrr_at_5 | 40.898 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_1 | 34.259 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_10 | 39.153 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_100 | 46.493 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_1000 | 49.01 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_3 | 34.636 |
| Retrieval | C-MTEB/CmedqaRetrieval | ndcg_at_5 | 36.278 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_1 | 34.259 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_10 | 8.815000000000001 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_100 | 1.474 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_1000 | 0.179 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_3 | 19.73 |
| Retrieval | C-MTEB/CmedqaRetrieval | precision_at_5 | 14.174000000000001 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_1 | 22.072 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_10 | 48.484 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_100 | 79.035 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_1000 | 96.15 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_3 | 34.607 |
| Retrieval | C-MTEB/CmedqaRetrieval | recall_at_5 | 40.064 |
| PairClassification | C-MTEB/CMNLI | cos_sim_accuracy | 76.7047504509922 |
| PairClassification | C-MTEB/CMNLI | cos_sim_ap | 85.26649874800871 |
| PairClassification | C-MTEB/CMNLI | cos_sim_f1 | 78.13528724646915 |
| PairClassification | C-MTEB/CMNLI | cos_sim_precision | 71.57587548638132 |
| PairClassification | C-MTEB/CMNLI | cos_sim_recall | 86.01823708206688 |
| PairClassification | C-MTEB/CMNLI | dot_accuracy | 70.13830426939266 |
| PairClassification | C-MTEB/CMNLI | dot_ap | 77.01510412382171 |
| PairClassification | C-MTEB/CMNLI | dot_f1 | 73.56710042713817 |
| PairClassification | C-MTEB/CMNLI | dot_precision | 63.955094991364426 |
| PairClassification | C-MTEB/CMNLI | dot_recall | 86.57937806873977 |
| PairClassification | C-MTEB/CMNLI | euclidean_accuracy | 75.53818400481059 |
| PairClassification | C-MTEB/CMNLI | euclidean_ap | 84.34668448241264 |
| PairClassification | C-MTEB/CMNLI | euclidean_f1 | 77.51741608613047 |
| PairClassification | C-MTEB/CMNLI | euclidean_precision | 70.65614777756399 |
| PairClassification | C-MTEB/CMNLI | euclidean_recall | 85.85457096095394 |
| PairClassification | C-MTEB/CMNLI | manhattan_accuracy | 75.49007817197835 |
| PairClassification | C-MTEB/CMNLI | manhattan_ap | 84.40297506704299 |
| PairClassification | C-MTEB/CMNLI | manhattan_f1 | 77.63185324160932 |
| PairClassification | C-MTEB/CMNLI | manhattan_precision | 70.03949595636637 |
| PairClassification | C-MTEB/CMNLI | manhattan_recall | 87.07037643207856 |
| PairClassification | C-MTEB/CMNLI | max_accuracy | 76.7047504509922 |
| PairClassification | C-MTEB/CMNLI | max_ap | 85.26649874800871 |
| PairClassification | C-MTEB/CMNLI | max_f1 | 78.13528724646915 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_1 | 69.178 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_10 | 77.523 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_100 | 77.793 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_1000 | 77.79899999999999 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_3 | 75.878 |
| Retrieval | C-MTEB/CovidRetrieval | map_at_5 | 76.849 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_1 | 69.44200000000001 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_10 | 77.55 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_100 | 77.819 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_1000 | 77.826 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_3 | 75.957 |
| Retrieval | C-MTEB/CovidRetrieval | mrr_at_5 | 76.916 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_1 | 69.44200000000001 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_10 | 81.217 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_100 | 82.45 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_1000 | 82.636 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_3 | 77.931 |
| Retrieval | C-MTEB/CovidRetrieval | ndcg_at_5 | 79.655 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_1 | 69.44200000000001 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_10 | 9.357 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_100 | 0.993 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_1000 | 0.101 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_3 | 28.1 |
| Retrieval | C-MTEB/CovidRetrieval | precision_at_5 | 17.724 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_1 | 69.178 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_10 | 92.624 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_100 | 98.209 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_1000 | 99.684 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_3 | 83.772 |
| Retrieval | C-MTEB/CovidRetrieval | recall_at_5 | 87.882 |
| Retrieval | C-MTEB/DuRetrieval | map_at_1 | 25.163999999999998 |
| Retrieval | C-MTEB/DuRetrieval | map_at_10 | 76.386 |
| Retrieval | C-MTEB/DuRetrieval | map_at_100 | 79.339 |
| Retrieval | C-MTEB/DuRetrieval | map_at_1000 | 79.39500000000001 |
| Retrieval | C-MTEB/DuRetrieval | map_at_3 | 52.959 |
| Retrieval | C-MTEB/DuRetrieval | map_at_5 | 66.59 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_1 | 87.9 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_10 | 91.682 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_100 | 91.747 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_1000 | 91.751 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_3 | 91.267 |
| Retrieval | C-MTEB/DuRetrieval | mrr_at_5 | 91.527 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_1 | 87.9 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_10 | 84.569 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_100 | 87.83800000000001 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_1000 | 88.322 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_3 | 83.473 |
| Retrieval | C-MTEB/DuRetrieval | ndcg_at_5 | 82.178 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_1 | 87.9 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_10 | 40.605000000000004 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_100 | 4.752 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_1000 | 0.488 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_3 | 74.9 |
| Retrieval | C-MTEB/DuRetrieval | precision_at_5 | 62.96000000000001 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_1 | 25.163999999999998 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_10 | 85.97399999999999 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_100 | 96.63000000000001 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_1000 | 99.016 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_3 | 55.611999999999995 |
| Retrieval | C-MTEB/DuRetrieval | recall_at_5 | 71.936 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_1 | 48.6 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_10 | 58.831 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_100 | 59.427 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_1000 | 59.44199999999999 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_3 | 56.383 |
| Retrieval | C-MTEB/EcomRetrieval | map_at_5 | 57.753 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_1 | 48.6 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_10 | 58.831 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_100 | 59.427 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_1000 | 59.44199999999999 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_3 | 56.383 |
| Retrieval | C-MTEB/EcomRetrieval | mrr_at_5 | 57.753 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_1 | 48.6 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_10 | 63.951 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_100 | 66.72200000000001 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_1000 | 67.13900000000001 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_3 | 58.882 |
| Retrieval | C-MTEB/EcomRetrieval | ndcg_at_5 | 61.373 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_1 | 48.6 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_10 | 8.01 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_100 | 0.928 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_1000 | 0.096 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_3 | 22.033 |
| Retrieval | C-MTEB/EcomRetrieval | precision_at_5 | 14.44 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_1 | 48.6 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_10 | 80.10000000000001 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_100 | 92.80000000000001 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_1000 | 96.1 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_3 | 66.10000000000001 |
| Retrieval | C-MTEB/EcomRetrieval | recall_at_5 | 72.2 |
| Classification | C-MTEB/IFlyTek-classification | accuracy | 47.36437091188918 |
| Classification | C-MTEB/IFlyTek-classification | f1 | 36.60946954228577 |
| Classification | C-MTEB/JDReview-classification | accuracy | 79.5684803001876 |
| Classification | C-MTEB/JDReview-classification | ap | 42.671935929201524 |
| Classification | C-MTEB/JDReview-classification | f1 | 73.31912729103752 |
| STS | C-MTEB/LCQMC | cos_sim_pearson | 68.62670112113864 |
| STS | C-MTEB/LCQMC | cos_sim_spearman | 75.74009123170768 |
| STS | C-MTEB/LCQMC | euclidean_pearson | 73.93002595958237 |
| STS | C-MTEB/LCQMC | euclidean_spearman | 75.35222935003587 |
| STS | C-MTEB/LCQMC | manhattan_pearson | 73.89870445158144 |
| STS | C-MTEB/LCQMC | manhattan_spearman | 75.31714936339398 |
| Reranking | C-MTEB/Mmarco-reranking | map | 31.5372713650176 |
| Reranking | C-MTEB/Mmarco-reranking | mrr | 30.163095238095238 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_1 | 65.054 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_10 | 74.156 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_100 | 74.523 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_1000 | 74.535 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_3 | 72.269 |
| Retrieval | C-MTEB/MMarcoRetrieval | map_at_5 | 73.41 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_1 | 67.24900000000001 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_10 | 74.78399999999999 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_100 | 75.107 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_1000 | 75.117 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_3 | 73.13499999999999 |
| Retrieval | C-MTEB/MMarcoRetrieval | mrr_at_5 | 74.13499999999999 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_1 | 67.24900000000001 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_10 | 77.96300000000001 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_100 | 79.584 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_1000 | 79.884 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_3 | 74.342 |
| Retrieval | C-MTEB/MMarcoRetrieval | ndcg_at_5 | 76.278 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_1 | 67.24900000000001 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_10 | 9.466 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_100 | 1.027 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_1000 | 0.105 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_3 | 27.955999999999996 |
| Retrieval | C-MTEB/MMarcoRetrieval | precision_at_5 | 17.817 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_1 | 65.054 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_10 | 89.113 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_100 | 96.369 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_1000 | 98.714 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_3 | 79.45400000000001 |
| Retrieval | C-MTEB/MMarcoRetrieval | recall_at_5 | 84.06 |
| Classification | mteb/amazon_massive_intent | accuracy | 68.1977135171486 |
| Classification | mteb/amazon_massive_intent | f1 | 67.23114308718404 |
| Classification | mteb/amazon_massive_scenario | accuracy | 71.92669804976462 |
| Classification | mteb/amazon_massive_scenario | f1 | 72.90628475628779 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_1 | 49.2 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_10 | 54.539 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_100 | 55.135 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_1000 | 55.19199999999999 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_3 | 53.383 |
| Retrieval | C-MTEB/MedicalRetrieval | map_at_5 | 54.142999999999994 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_1 | 49.2 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_10 | 54.539 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_100 | 55.135999999999996 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_1000 | 55.19199999999999 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_3 | 53.383 |
| Retrieval | C-MTEB/MedicalRetrieval | mrr_at_5 | 54.142999999999994 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_1 | 49.2 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_10 | 57.123000000000005 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_100 | 60.21300000000001 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_1000 | 61.915 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_3 | 54.772 |
| Retrieval | C-MTEB/MedicalRetrieval | ndcg_at_5 | 56.157999999999994 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_1 | 49.2 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_10 | 6.52 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_100 | 0.8009999999999999 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_1000 | 0.094 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_3 | 19.6 |
| Retrieval | C-MTEB/MedicalRetrieval | precision_at_5 | 12.44 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_1 | 49.2 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_10 | 65.2 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_100 | 80.10000000000001 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_1000 | 93.89999999999999 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_3 | 58.8 |
| Retrieval | C-MTEB/MedicalRetrieval | recall_at_5 | 62.2 |
| Classification | C-MTEB/MultilingualSentiment-classification | accuracy | 63.29333333333334 |
| Classification | C-MTEB/MultilingualSentiment-classification | f1 | 63.03293854259612 |
| PairClassification | C-MTEB/OCNLI | cos_sim_accuracy | 75.69030860855442 |
| PairClassification | C-MTEB/OCNLI | cos_sim_ap | 80.6157833772759 |
| PairClassification | C-MTEB/OCNLI | cos_sim_f1 | 77.87524366471735 |
| PairClassification | C-MTEB/OCNLI | cos_sim_precision | 72.3076923076923 |
| PairClassification | C-MTEB/OCNLI | cos_sim_recall | 84.37170010559663 |
| PairClassification | C-MTEB/OCNLI | dot_accuracy | 67.78559826746074 |
| PairClassification | C-MTEB/OCNLI | dot_ap | 72.00871467527499 |
| PairClassification | C-MTEB/OCNLI | dot_f1 | 72.58722247394654 |
| PairClassification | C-MTEB/OCNLI | dot_precision | 63.57142857142857 |
| PairClassification | C-MTEB/OCNLI | dot_recall | 84.58289334741288 |
| PairClassification | C-MTEB/OCNLI | euclidean_accuracy | 75.20303194369248 |
| PairClassification | C-MTEB/OCNLI | euclidean_ap | 80.98587256415605 |
| PairClassification | C-MTEB/OCNLI | euclidean_f1 | 77.26396917148362 |
| PairClassification | C-MTEB/OCNLI | euclidean_precision | 71.03631532329496 |
| PairClassification | C-MTEB/OCNLI | euclidean_recall | 84.68848996832101 |
| PairClassification | C-MTEB/OCNLI | manhattan_accuracy | 75.20303194369248 |
| PairClassification | C-MTEB/OCNLI | manhattan_ap | 80.93460699513219 |
| PairClassification | C-MTEB/OCNLI | manhattan_f1 | 77.124773960217 |
| PairClassification | C-MTEB/OCNLI | manhattan_precision | 67.43083003952569 |
| PairClassification | C-MTEB/OCNLI | manhattan_recall | 90.07391763463569 |
| PairClassification | C-MTEB/OCNLI | max_accuracy | 75.69030860855442 |
| PairClassification | C-MTEB/OCNLI | max_ap | 80.98587256415605 |
| PairClassification | C-MTEB/OCNLI | max_f1 | 77.87524366471735 |
| Classification | C-MTEB/OnlineShopping-classification | accuracy | 87.00000000000001 |
| Classification | C-MTEB/OnlineShopping-classification | ap | 83.24372135949511 |
| Classification | C-MTEB/OnlineShopping-classification | f1 | 86.95554191530607 |
| STS | C-MTEB/PAWSX | cos_sim_pearson | 37.57616811591219 |
| STS | C-MTEB/PAWSX | cos_sim_spearman | 41.490259084930045 |
| STS | C-MTEB/PAWSX | euclidean_pearson | 38.9155043692188 |
| STS | C-MTEB/PAWSX | euclidean_spearman | 39.16056534305623 |
| STS | C-MTEB/PAWSX | manhattan_pearson | 38.76569892264335 |
| STS | C-MTEB/PAWSX | manhattan_spearman | 38.99891685590743 |
| STS | C-MTEB/QBQTC | cos_sim_pearson | 35.44858610359665 |
| STS | C-MTEB/QBQTC | cos_sim_spearman | 38.11128146262466 |
| STS | C-MTEB/QBQTC | euclidean_pearson | 31.928644189822457 |
| STS | C-MTEB/QBQTC | euclidean_spearman | 34.384936631696554 |
| STS | C-MTEB/QBQTC | manhattan_pearson | 31.90586687414376 |
| STS | C-MTEB/QBQTC | manhattan_spearman | 34.35770153777186 |
| STS | mteb/sts22-crosslingual-sts | cos_sim_pearson | 66.54931957553592 |
| STS | mteb/sts22-crosslingual-sts | cos_sim_spearman | 69.25068863016632 |
| STS | mteb/sts22-crosslingual-sts | euclidean_pearson | 50.26525596106869 |
| STS | mteb/sts22-crosslingual-sts | euclidean_spearman | 63.83352741910006 |
| STS | mteb/sts22-crosslingual-sts | manhattan_pearson | 49.98798282198196 |
| STS | mteb/sts22-crosslingual-sts | manhattan_spearman | 63.87649521907841 |
| STS | C-MTEB/STSB | cos_sim_pearson | 82.52782476625825 |
| STS | C-MTEB/STSB | cos_sim_spearman | 82.55618986168398 |
| STS | C-MTEB/STSB | euclidean_pearson | 78.48190631687673 |
| STS | C-MTEB/STSB | euclidean_spearman | 78.39479731354655 |
| STS | C-MTEB/STSB | manhattan_pearson | 78.51176592165885 |
| STS | C-MTEB/STSB | manhattan_spearman | 78.42363787303265 |
| Reranking | C-MTEB/T2Reranking | map | 67.36693873615643 |
| Reranking | C-MTEB/T2Reranking | mrr | 77.83847701797939 |
| Retrieval | C-MTEB/T2Retrieval | map_at_1 | 25.795 |
| Retrieval | C-MTEB/T2Retrieval | map_at_10 | 72.258 |
| Retrieval | C-MTEB/T2Retrieval | map_at_100 | 76.049 |
| Retrieval | C-MTEB/T2Retrieval | map_at_1000 | 76.134 |
| Retrieval | C-MTEB/T2Retrieval | map_at_3 | 50.697 |
| Retrieval | C-MTEB/T2Retrieval | map_at_5 | 62.324999999999996 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_1 | 86.634 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_10 | 89.792 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_100 | 89.91900000000001 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_1000 | 89.923 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_3 | 89.224 |
| Retrieval | C-MTEB/T2Retrieval | mrr_at_5 | 89.608 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_1 | 86.634 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_10 | 80.589 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_100 | 84.812 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_1000 | 85.662 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_3 | 82.169 |
| Retrieval | C-MTEB/T2Retrieval | ndcg_at_5 | 80.619 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_1 | 86.634 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_10 | 40.389 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_100 | 4.93 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_1000 | 0.513 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_3 | 72.104 |
| Retrieval | C-MTEB/T2Retrieval | precision_at_5 | 60.425 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_1 | 25.795 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_10 | 79.565 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_100 | 93.24799999999999 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_1000 | 97.595 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_3 | 52.583999999999996 |
| Retrieval | C-MTEB/T2Retrieval | recall_at_5 | 66.175 |
| Classification | C-MTEB/TNews-classification | accuracy | 47.648999999999994 |
| Classification | C-MTEB/TNews-classification | f1 | 46.28925837008413 |
| Clustering | C-MTEB/ThuNewsClusteringP2P | v_measure | 54.07641891287953 |
| Clustering | C-MTEB/ThuNewsClusteringS2S | v_measure | 53.423702062353954 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_1 | 55.7 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_10 | 65.923 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_100 | 66.42 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_1000 | 66.431 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_3 | 63.9 |
| Retrieval | C-MTEB/VideoRetrieval | map_at_5 | 65.225 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_1 | 55.60000000000001 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_10 | 65.873 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_100 | 66.36999999999999 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_1000 | 66.381 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_3 | 63.849999999999994 |
| Retrieval | C-MTEB/VideoRetrieval | mrr_at_5 | 65.17500000000001 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_1 | 55.7 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_10 | 70.621 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_100 | 72.944 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_1000 | 73.25399999999999 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_3 | 66.547 |
| Retrieval | C-MTEB/VideoRetrieval | ndcg_at_5 | 68.93599999999999 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_1 | 55.7 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_10 | 8.52 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_100 | 0.958 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_1000 | 0.098 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_3 | 24.733 |
| Retrieval | C-MTEB/VideoRetrieval | precision_at_5 | 16 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_1 | 55.7 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_10 | 85.2 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_100 | 95.8 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_1000 | 98.3 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_3 | 74.2 |
| Retrieval | C-MTEB/VideoRetrieval | recall_at_5 | 80 |
| Classification | C-MTEB/waimai-classification | accuracy | 84.54 |
| Classification | C-MTEB/waimai-classification | ap | 66.13603199670062 |
| Classification | C-MTEB/waimai-classification | f1 | 82.61420654584116 |
🤝 联系我们
加入我们的 Discord 社区,与其他社区成员交流想法。
📚 引用
如果您在研究中发现 Jina Embeddings 很有用,请引用以下论文:
@article{mohr2024multi,
title={Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings},
author={Mohr, Isabelle and Krimmel, Markus and Sturua, Saba and Akram, Mohammad Kalim and Koukounas, Andreas and Günther, Michael and Mastrapas, Georgios and Ravishankar, Vinit and Martínez, Joan Fontanals and Wang, Feng and others},
journal={arXiv preprint arXiv:2402.17016},
year={2024}
}
 Safetensors 英语
Safetensors 英语%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)