🚀 Whisper-Large-V3-Distil-Italian-v0.2
这是Whisper的蒸馏版本,具有2个解码器层,专为意大利语语音转文本任务进行了优化。该版本将训练扩展到30秒的音频片段,以保持长格式转录能力。在蒸馏过程中,使用了 "耐心" 教师,即更长的训练时间和更激进的数据增强,从而提高了整体性能。
🚀 快速开始
本模型可用于意大利语的自动语音识别任务。它使用 openai/whisper-large-v3 作为教师模型,同时保持编码器架构不变。这使得它适合作为推测解码的草稿模型,在仅添加2个额外解码器层并仅运行一次编码器的情况下,可能获得2倍的推理速度,同时保持相同的输出。它也可以作为独立模型,以牺牲一些准确性为代价来提高效率,运行速度快5.8倍,同时仅使用49%的参数。
✨ 主要特性
- 优化的意大利语识别:专门为意大利语语音转文本进行优化,提高了在该语言上的识别性能。
- 长格式转录能力:通过扩展训练到30秒音频片段,保持了长格式转录的能力。
- 多种使用方式:可以作为推测解码的草稿模型,也可以作为独立模型使用。
- 广泛的兼容性:已转换为多种格式,确保在包括transformers、openai-whisper、faster-whisper、whisper.cpp、candle、mlx等库中的广泛兼容性。
📦 安装指南
根据不同的使用方式,需要安装不同的依赖库:
- Hugging Face Pipeline和低级别API:
pip install torch datasets transformers
pip install -U openai-whisper
pip install faster-whisper
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
make
git clone https://github.com/huggingface/candle.git
cd candle/candle-examples/examples/whisper
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/whisper
pip install -r requirements.txt
💻 使用示例
基础用法
以下是使用Hugging Face Pipeline进行音频转录的示例:
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_name_or_path = "bofenghuang/whisper-large-v3-distil-it-v0.2"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
max_new_tokens=128,
)
dataset = load_dataset("bofenghuang/asr-dummy", "it", split="test")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
高级用法
以下是使用推测解码的示例:
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
pipeline,
)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_name_or_path = "openai/whisper-large-v3"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
assistant_model_name_or_path = "bofenghuang/whisper-large-v3-distil-it-v0.2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
assistant_model.to(device)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
generate_kwargs={"assistant_model": assistant_model},
max_new_tokens=128,
)
dataset = load_dataset("bofenghuang/asr-dummy", "it", split="test")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
📚 详细文档
性能评估
模型在短格式和长格式转录上进行了评估,使用了分布内(ID)和分布外(OOD)数据集来评估准确性、泛化能力和鲁棒性。所有公共数据集的评估结果可以在 这里 找到。
短格式转录
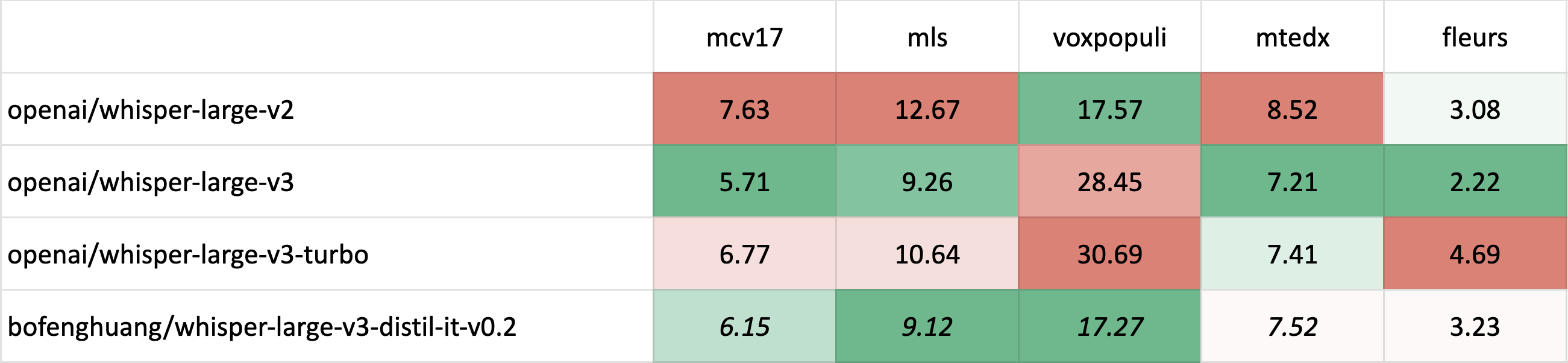 斜体 表示分布内(ID)评估,其中测试集对应于训练期间看到的数据分布,通常比分布外(OOD)评估具有更高的性能。
斜体 表示分布内(ID)评估,其中测试集对应于训练期间看到的数据分布,通常比分布外(OOD)评估具有更高的性能。斜体和删除线 表示潜在的测试集污染 - 例如,当训练和评估使用不同版本的Common Voice时,可能会出现数据重叠的可能性。
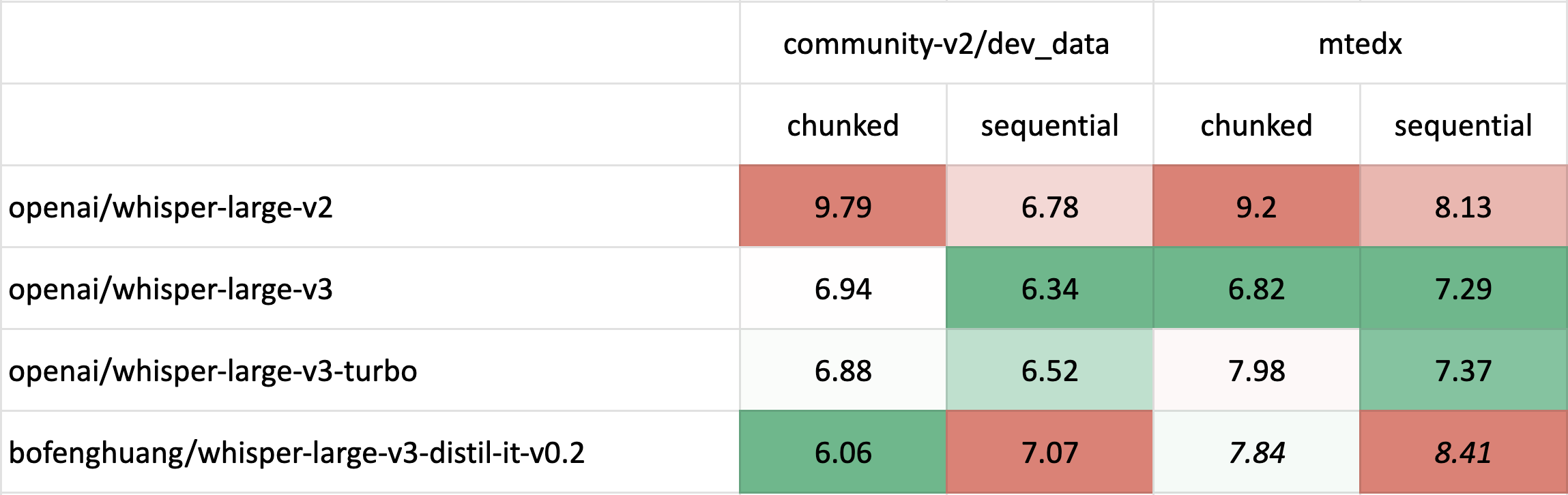
长格式转录
长格式转录评估使用了 🤗 Hugging Face 的 pipeline,同时使用了 分块(chunk_length_s=30)和原始顺序解码方法。
🔧 技术细节
训练数据集
构建了一个超过11,000小时的标注和半标注意大利语语音识别数据集。在通过Whisper-Large-V3解码该数据集并过滤掉WER高于20%的片段后,保留了约6,500小时的高质量音频。
| 数据集 |
总时长 (h) |
过滤后时长 (h) <20% WER |
| mcv |
249.92 |
232.87 |
| mls |
247.38 |
234.14 |
| voxpopuli |
74.11 |
58.25 |
| mtedx |
94.10 |
88.69 |
| yodas-it000 |
1447.25 |
953.19 |
| yodas-it100 |
4929.73 |
2665.54 |
| yodas-it101 |
4192.61 |
2275.90 |
| 总计 |
11235.10 |
6508.58 |
训练策略
大多数数据首先被连接成30秒的片段,主要保留相同的说话者,然后一起进行推理。50%的片段使用时间戳进行训练,以确保良好的时间戳预测,只有20%的片段使用先前的上下文进行训练,因为不期望2层解码器在这项任务上表现出色。该模型使用激进的数据增强进行了100个epoch的相当长的训练,评估WER持续下降。一些超参数选择倾向于长格式转录而不是短格式转录。更多详细信息,请参考 Distil-Whisper 仓库。
📄 许可证
本项目采用MIT许可证。
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)