模型简介
模型特点
模型能力
使用案例
🚀 RT-DETR 模型卡片
RT-DETR 是首个实时端到端目标检测器,解决了现有目标检测框架在速度和准确性方面的困境。它通过高效混合编码器和不确定性最小查询选择等方法,在保持准确性的同时提高速度,或在保持速度的同时提高准确性。
🚀 快速开始
使用以下代码开始使用该模型:
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
这段代码的输出应该如下:
sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
cat: 0.96 [343.38, 24.28, 640.14, 371.5]
cat: 0.96 [13.23, 54.18, 318.98, 472.22]
remote: 0.95 [40.11, 73.44, 175.96, 118.48]
✨ 主要特性
- 实时端到端检测:RT-DETR 是首个实时端到端目标检测器,解决了现有目标检测框架在速度和准确性方面的困境。
- 高效混合编码器:通过解耦尺度内交互和跨尺度融合,快速处理多尺度特征,提高速度。
- 不确定性最小查询选择:为解码器提供高质量的初始查询,提高准确性。
- 灵活的速度调整:通过调整解码器层数,支持灵活的速度调整,适应各种场景,无需重新训练。
📦 安装指南
文档未提及安装步骤,故跳过此章节。
💻 使用示例
基础用法
import torch
import requests
from PIL import Image
from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r18vd_coco_o365")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
for result in results:
for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
score, label = score.item(), label_id.item()
box = [round(i, 2) for i in box.tolist()]
print(f"{model.config.id2label[label]}: {score:.2f} {box}")
高级用法
文档未提及高级用法代码示例,故跳过此部分。
📚 详细文档
模型详情

YOLO 系列由于在速度和准确性之间进行了合理的权衡,已成为实时目标检测最流行的框架。然而,我们观察到 YOLO 的速度和准确性受到 NMS 的负面影响。最近,基于端到端 Transformer 的检测器(DETR)提供了一种消除 NMS 的替代方案。然而,高计算成本限制了它们的实用性,并阻碍了它们充分发挥排除 NMS 的优势。在本文中,我们提出了实时检测 Transformer(RT-DETR),据我们所知,这是第一个解决上述困境的实时端到端目标检测器。我们借鉴先进的 DETR,分两步构建 RT-DETR:首先,我们专注于在提高速度的同时保持准确性,然后在保持速度的同时提高准确性。具体来说,我们设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来快速处理多尺度特征,以提高速度。然后,我们提出了不确定性最小查询选择,为解码器提供高质量的初始查询,从而提高准确性。此外,RT-DETR 支持通过调整解码器层数来灵活调整速度,以适应各种场景,无需重新训练。我们的 RT-DETR-R50 / R101 在 COCO 上达到了 53.1% / 54.3% 的 AP,在 T4 GPU 上达到了 108 / 74 FPS,在速度和准确性上都优于之前先进的 YOLO。我们还开发了缩放版的 RT-DETR,优于较轻量级的 YOLO 检测器(S 和 M 模型)。此外,RT-DETR-R50 在准确性上比 DINO-R50 高 2.2% 的 AP,在 FPS 上约高 21 倍。在使用 Objects365 进行预训练后,RT-DETR-R50 / R101 达到了 55.3% / 56.2% 的 AP。项目页面:https URL。
模型来源
- HF 文档:RT-DETR
- 代码仓库:https://github.com/lyuwenyu/RT-DETR
- 论文:https://arxiv.org/abs/2304.08069
- 演示:RT-DETR 跟踪
训练详情
训练数据
RTDETR 模型在 COCO 2017 目标检测 数据集上进行训练,该数据集分别包含 118k/5k 张带注释的图像用于训练/验证。
训练过程
我们在 COCO 和 Objects365 数据集上进行实验,其中 RT-DETR 在 COCO train2017 上进行训练,并在 COCO val2017 数据集上进行验证。我们报告了标准的 COCO 指标,包括 AP(在从 0.50 到 0.95 的均匀采样 IoU 阈值上平均,步长为 0.05)、AP50、AP75,以及不同尺度下的 AP:AP-s、AP-m、AP-l。
预处理
图像被调整为 640x640 像素,并使用 image_mean=[0.485, 0.456, 0.406] 和 image_std=[0.229, 0.224, 0.225] 进行重新缩放。
训练超参数

评估
| 模型 | 训练轮数 | 参数数量(M) | GFLOPs | FPS_bs=1 | AP (验证集) | AP50 (验证集) | AP75 (验证集) | AP-s (验证集) | AP-m (验证集) | AP-l (验证集) |
|---|---|---|---|---|---|---|---|---|---|---|
| RT-DETR-R18 | 72 | 20 | 60.7 | 217 | 46.5 | 63.8 | 50.4 | 28.4 | 49.8 | 63.0 |
| RT-DETR-R34 | 72 | 31 | 91.0 | 172 | 48.5 | 66.2 | 52.3 | 30.2 | 51.9 | 66.2 |
| RT-DETR R50 | 72 | 42 | 136 | 108 | 53.1 | 71.3 | 57.7 | 34.8 | 58.0 | 70.0 |
| RT-DETR R101 | 72 | 76 | 259 | 74 | 54.3 | 72.7 | 58.6 | 36.0 | 58.8 | 72.1 |
| RT-DETR-R18 (Objects 365 预训练) | 60 | 20 | 61 | 217 | 49.2 | 66.6 | 53.5 | 33.2 | 52.3 | 64.8 |
| RT-DETR-R50 (Objects 365 预训练) | 24 | 42 | 136 | 108 | 55.3 | 73.4 | 60.1 | 37.9 | 59.9 | 71.8 |
| RT-DETR-R101 (Objects 365 预训练) | 24 | 76 | 259 | 74 | 56.2 | 74.6 | 61.3 | 38.3 | 60.5 | 73.5 |
模型架构和目标
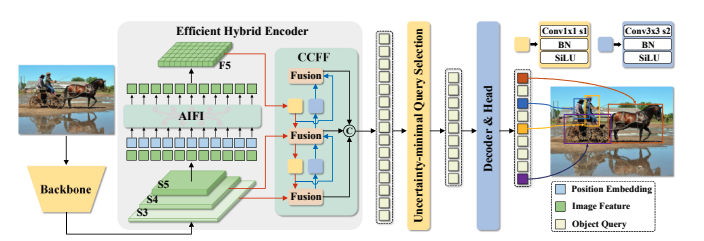
RT-DETR 概述。我们将骨干网络最后三个阶段的特征输入到编码器中。高效的混合编码器通过基于注意力的尺度内特征交互(AIFI)和基于 CNN 的跨尺度特征融合(CCFF)将多尺度特征转换为图像特征序列。然后,不确定性最小查询选择选择固定数量的编码器特征作为解码器的初始目标查询。最后,带有辅助预测头的解码器迭代优化目标查询,以生成类别和边界框。
引用
BibTeX:
@misc{lv2023detrs,
title={DETRs Beat YOLOs on Real-time Object Detection},
author={Yian Zhao and Wenyu Lv and Shangliang Xu and Jinman Wei and Guanzhong Wang and Qingqing Dang and Yi Liu and Jie Chen},
year={2023},
eprint={2304.08069},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
模型卡片作者
🔧 技术细节
文档未提及具体技术实现细节(>50 字),故跳过此章节。
📄 许可证
本模型使用的许可证为 Apache-2.0。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)