🚀 AnimateDiff-Lightning
AnimateDiff-Lightning 是一款闪电般快速的文本到视频生成模型,其视频生成速度比原始的 AnimateDiff 快十倍以上。更多信息请参考我们的研究论文:AnimateDiff-Lightning: Cross-Model Diffusion Distillation。我们将该模型作为研究成果发布。
🚀 快速开始
你可以通过以下方式快速体验 AnimateDiff-Lightning:
✨ 主要特性
- 高速生成:比原始的 AnimateDiff 快十倍以上。
- 多步选择:提供 1 步、2 步、4 步和 8 步的蒸馏模型。
- 适配多种基础模型:与多种风格化的基础模型配合使用效果更佳。
- 支持视频到视频生成:可实现视频到视频的转换。
📦 安装指南
本部分未提及具体安装步骤,暂不展示。
💻 使用示例
基础用法
Diffusers 库使用示例
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism"
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")
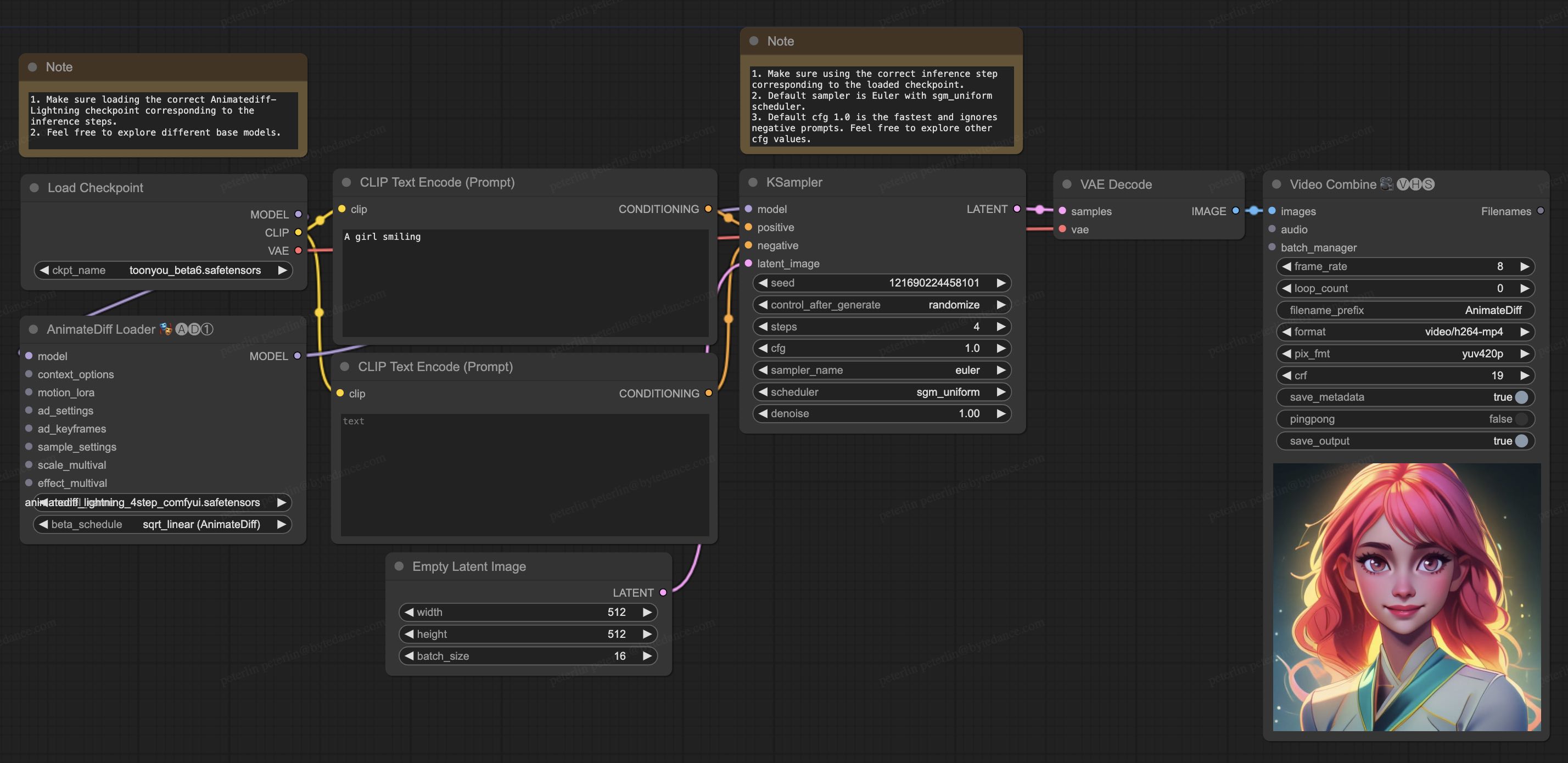
ComfyUI 使用示例
- 下载 animatediff_lightning_workflow.json 并在 ComfyUI 中导入。
- 安装节点。你可以手动安装,也可以使用 ComfyUI-Manager。
- 下载你喜欢的基础模型检查点,并将其放在
/models/checkpoints/ 目录下。
- 下载 AnimateDiff-Lightning 检查点
animatediff_lightning_Nstep_comfyui.safetensors 并将其放在 /custom_nodes/ComfyUI-AnimateDiff-Evolved/models/ 目录下。
高级用法
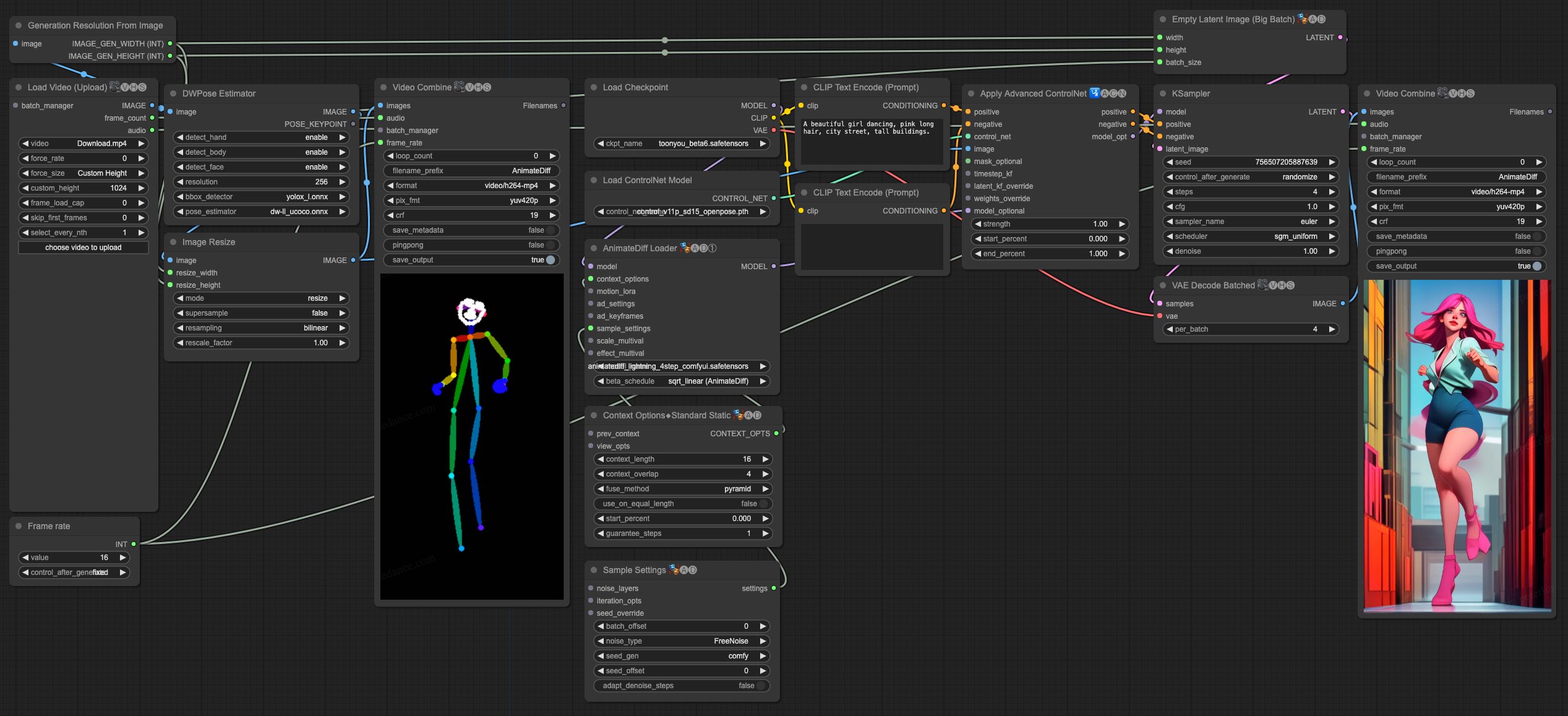
视频到视频生成示例
AnimateDiff-Lightning 非常适合视频到视频的生成。我们提供了使用 ControlNet 的最简单的 ComfyUI 工作流。
- 下载 animatediff_lightning_v2v_openpose_workflow.json 并在 ComfyUI 中导入。
- 安装节点。你可以手动安装,也可以使用 ComfyUI-Manager。
- 下载你喜欢的基础模型检查点,并将其放在
/models/checkpoints/ 目录下。
- 下载 AnimateDiff-Lightning 检查点
animatediff_lightning_Nstep_comfyui.safetensors 并将其放在 /custom_nodes/ComfyUI-AnimateDiff-Evolved/models/ 目录下。
- 下载 ControlNet OpenPose
control_v11p_sd15_openpose.pth 检查点到 /models/controlnet/ 目录下。
- 上传你的视频并运行管道。
额外注意事项:
- 视频不宜过长或分辨率过高。我们使用 576x1024、8 秒、30fps 的视频进行测试。
- 设置帧率以匹配输入视频,这样可以使音频与输出视频匹配。
- DWPose 在首次运行时会自行下载检查点。
- DWPose 可能会在 UI 中卡住,但实际上管道仍在后台运行。请检查 ComfyUI 日志和输出文件夹。
📚 详细文档
推荐基础模型
AnimateDiff-Lightning 与风格化的基础模型配合使用时效果最佳。我们推荐使用以下基础模型:
写实风格
动漫与卡通风格
使用建议
- 你可以自由探索不同的设置。我们发现对 2 步模型使用 3 次推理步骤会产生很好的效果。
- 某些基础模型在使用 CFG 时效果更好。
- 我们还建议使用 Motion LoRAs,因为它们可以产生更强的动态效果。我们使用强度为 0.7 - 0.8 的 Motion LoRAs 来避免水印。
📄 许可证
本项目采用 creativeml-openrail-m 许可证。
📚 引用我们的工作
如果你使用了本项目的相关内容,请引用以下论文:
@misc{lin2024animatedifflightning,
title={AnimateDiff-Lightning: Cross-Model Diffusion Distillation},
author={Shanchuan Lin and Xiao Yang},
year={2024},
eprint={2403.12706},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)