模型简介
模型特点
模型能力
使用案例
🚀 CogAgent
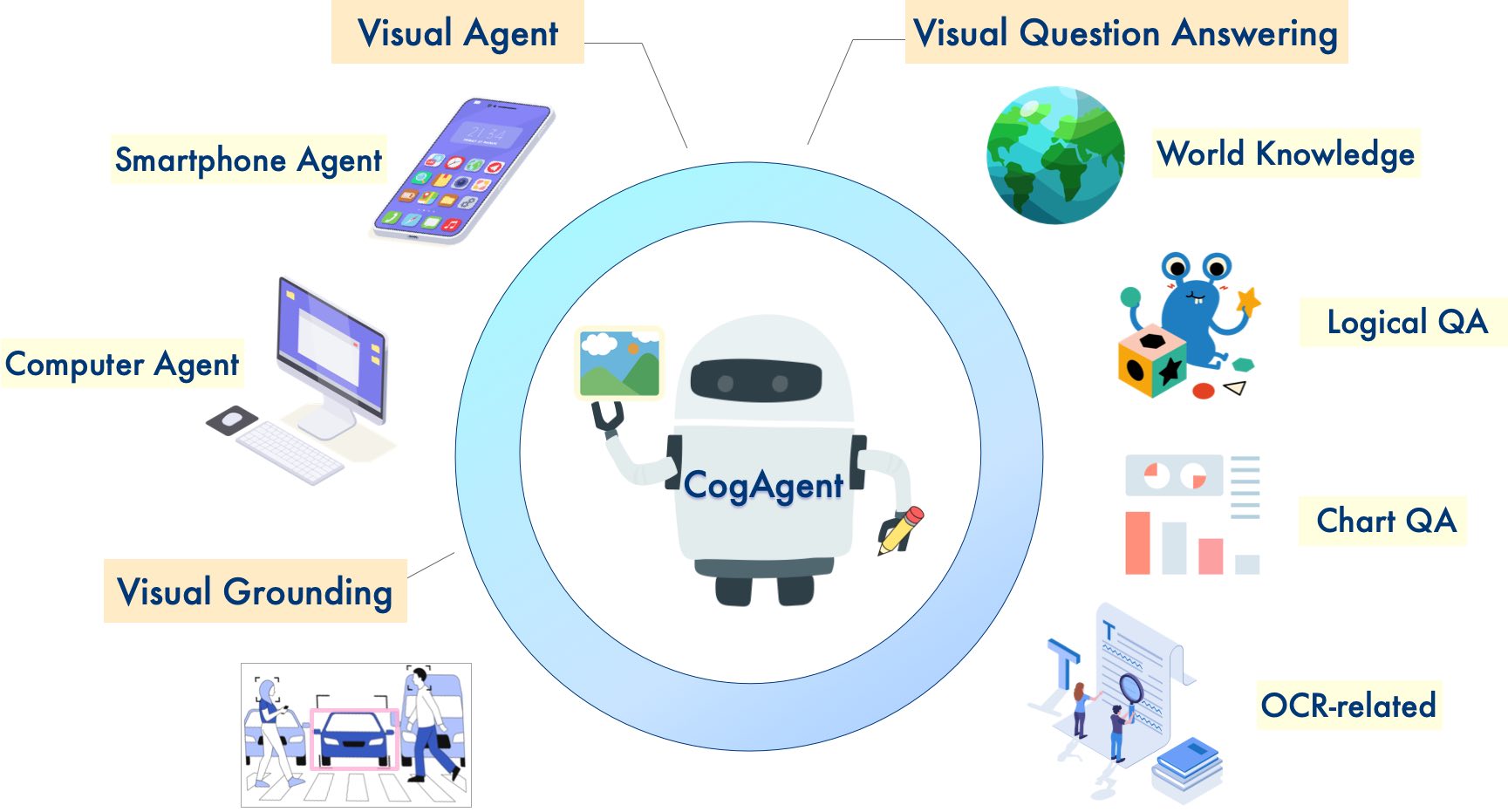
CogAgent 是一个基于 CogVLM 改进的开源视觉语言模型。它在图像理解和 GUI 代理方面表现出色,支持高分辨率视觉输入和对话问答,具备视觉 Agent 能力,还增强了 GUI 相关问答和 OCR 相关任务的能力。
🚀 快速开始
你可以使用以下 Python 代码在 cli_demo.py 中快速开始:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, LlamaTokenizer
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--quant", choices=[4], type=int, default=None, help='quantization bits')
parser.add_argument("--from_pretrained", type=str, default="THUDM/cogagent-chat-hf", help='pretrained ckpt')
parser.add_argument("--local_tokenizer", type=str, default="lmsys/vicuna-7b-v1.5", help='tokenizer path')
parser.add_argument("--fp16", action="store_true")
parser.add_argument("--bf16", action="store_true")
args = parser.parse_args()
MODEL_PATH = args.from_pretrained
TOKENIZER_PATH = args.local_tokenizer
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = LlamaTokenizer.from_pretrained(TOKENIZER_PATH)
if args.bf16:
torch_type = torch.bfloat16
else:
torch_type = torch.float16
print("========Use torch type as:{} with device:{}========\n\n".format(torch_type, DEVICE))
if args.quant:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=True,
trust_remote_code=True
).eval()
else:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=args.quant is not None,
trust_remote_code=True
).to(DEVICE).eval()
while True:
image_path = input("image path >>>>> ")
if image_path == "stop":
break
image = Image.open(image_path).convert('RGB')
history = []
while True:
query = input("Human:")
if query == "clear":
break
input_by_model = model.build_conversation_input_ids(tokenizer, query=query, history=history, images=[image])
inputs = {
'input_ids': input_by_model['input_ids'].unsqueeze(0).to(DEVICE),
'token_type_ids': input_by_model['token_type_ids'].unsqueeze(0).to(DEVICE),
'attention_mask': input_by_model['attention_mask'].unsqueeze(0).to(DEVICE),
'images': [[input_by_model['images'][0].to(DEVICE).to(torch_type)]],
}
if 'cross_images' in input_by_model and input_by_model['cross_images']:
inputs['cross_images'] = [[input_by_model['cross_images'][0].to(DEVICE).to(torch_type)]]
# add any transformers params here.
gen_kwargs = {"max_length": 2048,
"temperature": 0.9,
"do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = tokenizer.decode(outputs[0])
response = response.split("</s>")[0]
print("\nCog:", response)
history.append((query, response))
然后运行:
python cli_demo_hf.py --bf16
✨ 主要特性
🔥 新闻
新版本 CogAgent - 9B - 20241220 已发布!欢迎访问 CogAgent GitHub 和 技术报告 来探索和使用我们的最新模型。
模型版本选择
我们开源了 2 个版本的 CogAgent 检查点,你可以根据需求选择:
cogagent - chat:该模型 在 GUI 代理、视觉多轮对话、视觉定位 等方面具有强大的能力。如果你需要 GUI 代理和视觉定位功能,或者需要与给定图像进行多轮对话,我们建议使用此版本的模型。cogagent - vqa:该模型 在 单轮视觉对话 方面具有 更强 的能力。如果你需要 处理 VQA 基准测试(如 MMVET、VQAv2),我们建议使用此模型。
模型性能
- CogAgent - 18B 具有 110 亿视觉参数和 70 亿语言参数。
- 图像理解和 GUI 代理表现出色:
- CogAgent - 18B 在 9 个跨模态基准测试中达到了最先进的通用性能,包括:VQAv2、MM - Vet、POPE、ST - VQA、OK - VQA、TextVQA、ChartQA、InfoVQA、DocVQA。
- CogAgent - 18B 在 GUI 操作数据集(如 AITW 和 Mind2Web)上 显著超越了现有模型。
新增特性
除了 CogVLM 已有的所有 特性(视觉多轮对话、视觉定位)之外,CogAgent 还具备以下特性:
- 支持更高分辨率的视觉输入和对话问答:支持 1120x1120 的超高分辨率图像输入。
- 具备视觉 Agent 能力:能够针对任何给定的 GUI 截图上的任何任务返回计划、下一步行动和带有坐标的具体操作。
- 增强的 GUI 相关问答能力:能够处理关于任何 GUI 截图(如网页、PC 应用程序、移动应用程序等)的问题。
- 增强的 OCR 相关任务能力:通过改进的预训练和微调实现。
模型使用说明
此仓库中的模型权重用于学术研究是 免费的。希望将模型用于 商业目的 的用户必须在 此处 注册。注册用户可以免费将模型用于商业活动,但必须遵守本许可证的所有条款和条件。许可证声明应包含在软件的所有副本或重要部分中。
📚 详细文档
- 论文:https://arxiv.org/abs/2312.08914
- 技术报告:https://cogagent.aminer.cn/blog#/articles/cogagent-9b-20241220-technical-report-en
- GitHub:https://github.com/THUDM/CogAgent
- 模型页面:https://huggingface.co/THUDM/cogagent-9b-20241220
关于 THUDM/cogagent - chat - hf 的演示、微调以及查询提示等更多信息,请参考 此 GitHub。
📄 许可证
此仓库中的代码根据 Apache - 2.0 许可证 开源,而 CogAgent 和 CogVLM 模型权重的使用必须遵守 模型许可证。
🔗 引用与致谢
如果你觉得我们的工作有帮助,请考虑引用以下论文:
@misc{hong2023cogagent,
title={CogAgent: A Visual Language Model for GUI Agents},
author={Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2312.08914},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{wang2023cogvlm,
title={CogVLM: Visual Expert for Pretrained Language Models},
author={Weihan Wang and Qingsong Lv and Wenmeng Yu and Wenyi Hong and Ji Qi and Yan Wang and Junhui Ji and Zhuoyi Yang and Lei Zhao and Xixuan Song and Jiazheng Xu and Bin Xu and Juanzi Li and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2311.03079},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
在 CogVLM 的指令微调阶段,使用了来自 [MiniGPT - 4](https://github.com/Vision - CAIR/MiniGPT - 4)、[LLAVA](https://github.com/haotian - liu/LLaVA)、[LRV - Instruction](https://github.com/FuxiaoLiu/LRV - Instruction)、[LLaVAR](https://github.com/SALT - NLP/LLaVAR) 和 Shikra 项目的一些英文图像文本数据,以及许多经典的跨模态工作数据集。我们衷心感谢他们的贡献。
 Safetensors Safetensors
Safetensors Safetensors%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)