🚀 BigVGAN:大规模训练的通用神经声码器
BigVGAN是一种经过大规模训练的通用神经声码器,可用于音频生成,能将输入的音频特征转换为高质量的音频波形。
作者信息
Sang - gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
相关链接
[论文] - [代码] - [[展示]](https://bigvgan - demo.github.io/) - [项目页面] - [[权重]](https://huggingface.co/collections/nvidia/bigvgan - 66959df3d97fd7d98d97dc9a) - [演示]
论文影响力
[ ](https://paperswithcode.com/sota/speech - synthesis - on - libritts?p=bigvgan - a - universal - neural - vocoder - with - large)
](https://paperswithcode.com/sota/speech - synthesis - on - libritts?p=bigvgan - a - universal - neural - vocoder - with - large)
模型图示
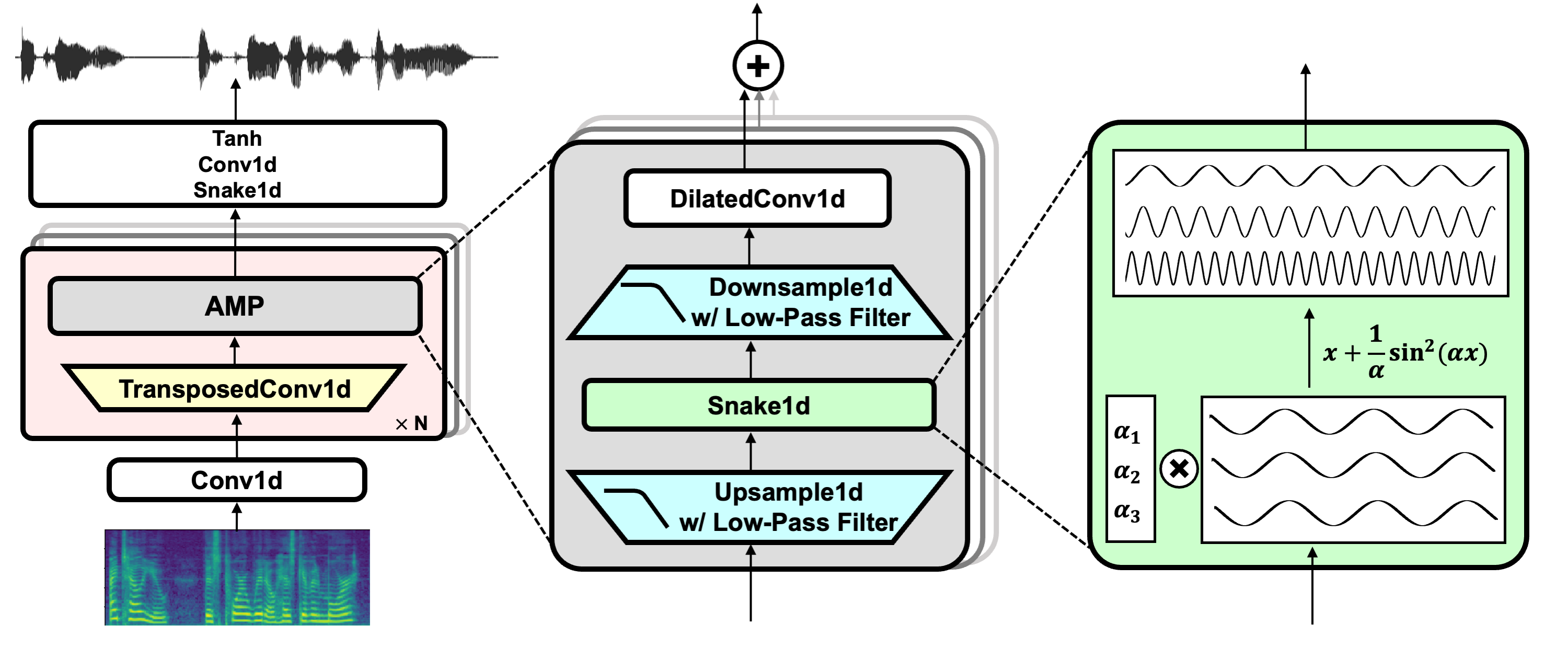
🚀 快速开始
最新消息
- 2024年7月 (v2.3):
- 进行了全面重构和代码改进,提高了代码的可读性。
- 实现了抗锯齿激活的全融合CUDA内核,并进行了推理速度基准测试。
- 2024年7月 (v2.2): 仓库现在包含一个使用Gradio的交互式本地演示。
- 2024年7月 (v2.1): BigVGAN现已与🤗 Hugging Face Hub集成,可轻松使用预训练检查点进行推理。我们还在Hugging Face Spaces上提供了一个交互式演示。
- 2024年7月 (v2): 我们发布了BigVGAN - v2以及预训练检查点。以下是主要亮点:
- 用于推理的自定义CUDA内核:我们提供了一个用CUDA编写的融合上采样 + 激活内核,以加快推理速度。我们的测试表明,在单个A100 GPU上速度可提高1.5 - 3倍。
- 改进的判别器和损失函数:BigVGAN - v2使用多尺度子带CQT判别器和多尺度梅尔频谱图损失进行训练。
- 更大的训练数据:BigVGAN - v2使用包含多种音频类型的数据集进行训练,包括多种语言的语音、环境声音和乐器声音。
- 我们提供了使用多种音频配置的BigVGAN - v2预训练检查点,支持高达44 kHz的采样率和512倍的上采样率。
📦 安装指南
本仓库包含预训练的BigVGAN检查点,可轻松进行推理,并额外支持huggingface_hub。
如果您对模型训练和其他功能感兴趣,请访问官方GitHub仓库获取更多信息:https://github.com/NVIDIA/BigVGAN
git lfs install
git clone https://huggingface.co/nvidia/bigvgan_v2_24khz_100band_256x
💻 使用示例
基础用法
以下示例描述了如何使用BigVGAN:从Hugging Face Hub加载预训练的BigVGAN生成器,从输入波形计算梅尔频谱图,并使用梅尔频谱图作为模型输入生成合成波形。
device = 'cuda'
import torch
import bigvgan
import librosa
from meldataset import get_mel_spectrogram
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_v2_24khz_100band_256x', use_cuda_kernel=False)
model.remove_weight_norm()
model = model.eval().to(device)
wav_path = '/path/to/your/audio.wav'
wav, sr = librosa.load(wav_path, sr=model.h.sampling_rate, mono=True)
wav = torch.FloatTensor(wav).unsqueeze(0)
mel = get_mel_spectrogram(wav, model.h).to(device)
with torch.inference_mode():
wav_gen = model(mel)
wav_gen_float = wav_gen.squeeze(0).cpu()
wav_gen_int16 = (wav_gen_float * 32767.0).numpy().astype('int16')
高级用法
使用自定义CUDA内核进行合成
您可以在实例化BigVGAN时使用参数use_cuda_kernel来应用快速CUDA推理内核:
import bigvgan
model = bigvgan.BigVGAN.from_pretrained('nvidia/bigvgan_v2_24khz_100band_256x', use_cuda_kernel=True)
首次应用时,它会使用nvcc和ninja构建内核。如果构建成功,内核将保存到alias_free_activation/cuda/build,模型会自动加载该内核。代码库已使用CUDA 12.1进行测试。
请确保您的系统中同时安装了这两个工具,并且系统中安装的nvcc版本与您的PyTorch版本相匹配。
如需详细信息,请参阅官方GitHub仓库:https://github.com/NVIDIA/BigVGAN?tab=readme-ov-file#using-custom-cuda-kernel-for-synthesis
📚 详细文档
预训练模型
我们在[Hugging Face Collections](https://huggingface.co/collections/nvidia/bigvgan - 66959df3d97fd7d98d97dc9a)上提供了预训练模型。您可以在列出的模型仓库中下载生成器权重(名为bigvgan_generator.pt)及其判别器/优化器状态(名为bigvgan_discriminator_optimizer.pt)的检查点。
📄 许可证
本项目采用MIT许可证,详情请见许可证链接。
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)