🚀 BERTugues Base(又名 "BERTugues-base-portuguese-cased")
BERTugues是一个基于BERT架构的预训练模型,专为葡萄牙语设计。它在多个自然语言处理任务中展现出了出色的性能,尤其在处理葡萄牙语文本时具有显著优势。
🚀 快速开始
BERTugues按照BERT原论文的步骤进行预训练,目标是进行掩码语言模型(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)。它经过100万步的训练,使用了超过20GB的文本数据。更多训练细节请阅读已发表的论文。与Bertimbau类似,BERTugues使用BrWAC数据集和葡萄牙语维基百科进行分词器的预训练,同时在训练流程上进行了一些改进:
- 去除分词器训练中不常见的葡萄牙语字符:在Bertimbau中,29794个标记里有超过7000个使用了东方字符或特殊字符,这些字符在葡萄牙语中几乎从不使用。例如,存在标记 "##漫"、"##켝"、"##前"。而在BERTugues中,我们在训练分词器之前去除了这些字符。
- 😀 在分词器中添加主要表情符号:维基百科文本中的表情符号较少,因此进入标记的表情符号数量也很少。正如文献所证明的,表情符号在一系列任务中非常重要。
- 过滤BrWAC文本的质量:遵循谷歌Gopher模型论文提出的启发式模型,我们从BrWAC中去除了低质量的文本。
✨ 主要特性
分词器优化
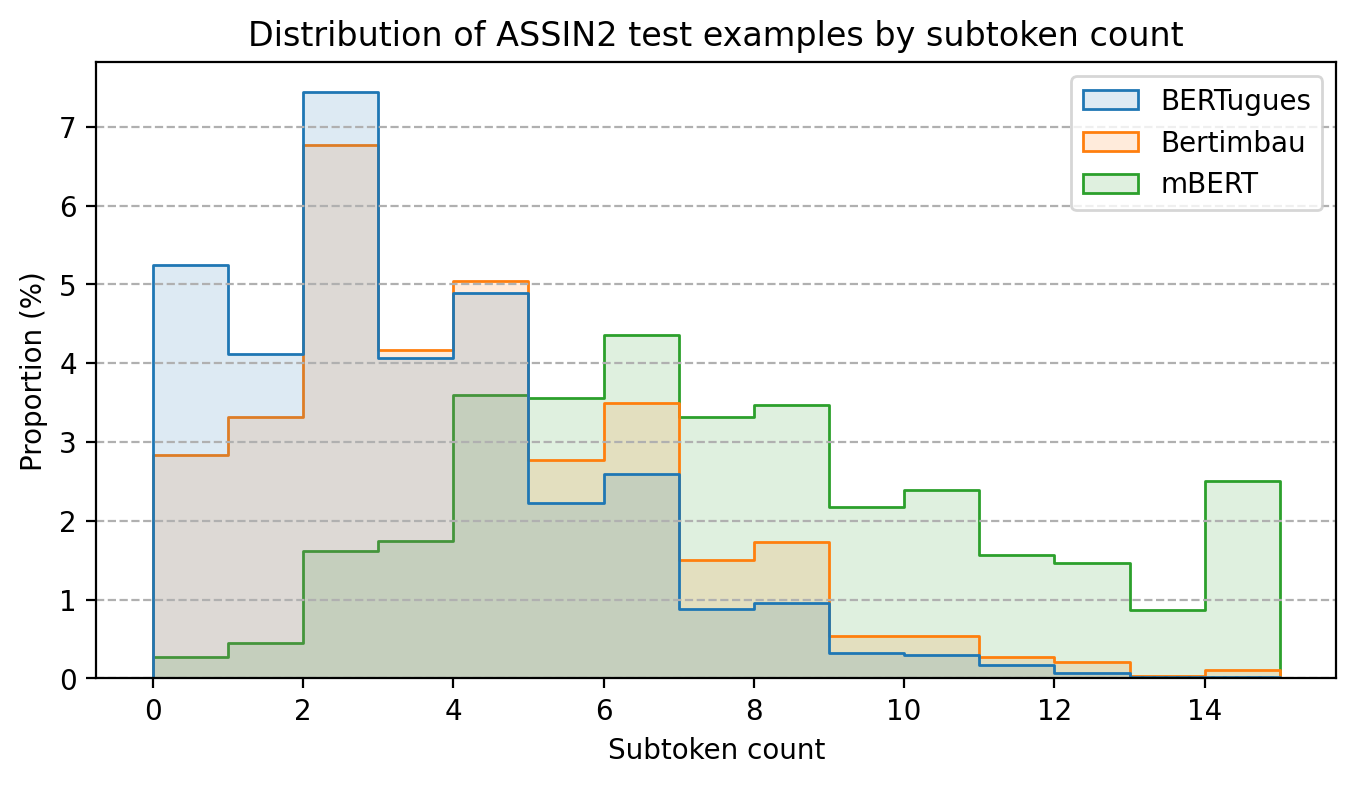
通过替换葡萄牙语中不常用的标记,我们减少了被拆分为多个标记的单词的平均数量。在使用assin2的测试中(这也是Bertimbau在硕士论文中使用的相同数据集),我们将每个文本中被拆分的单词的平均数量从3.8减少到了3.0,而多语言BERT的这一数字为7.4。
性能卓越
为了比较性能,我们测试了一个文本分类问题,使用了IMDB的电影评论数据集,该数据集已被翻译成葡萄牙语,质量较高。在这个问题中,我们使用BERTugues的句子表示,并将其输入到随机森林模型中进行分类。
我们还参考了论文JurisBERT: Transformer-based model for embedding legal texts的性能比较,该论文专门针对特定领域的文本预训练了一个BERT模型,使用多语言BERT和Bertimbau作为基线。在这种情况下,我们使用了论文团队提供的代码并添加了BERTugues。该模型用于比较两个文本是否属于同一主题。
| 模型 |
IMDB (F1) |
STJ (F1) |
PJERJ (F1) |
TJMS (F1) |
F1平均值 |
| 多语言BERT |
72.0% |
30.4% |
63.8% |
65.0% |
57.8% |
| Bertimbau-Base |
82.2% |
35.6% |
63.9% |
71.2% |
63.2% |
| Bertimbau-Large |
85.3% |
43.0% |
63.8% |
74.0% |
66.5% |
| BERTugues-Base |
84.0% |
45.2% |
67.5% |
70.0% |
66.7% |
与Bertimbau-base相比,BERTugues在4项任务中的3项上表现更优;与Bertimbau-Large(一个参数多3倍且计算成本更高的模型)相比,BERTugues在4项任务中的2项上表现更优。
💻 使用示例
基础用法
掩码语言模型预测
from transformers import BertTokenizer, BertForMaskedLM, pipeline
model = BertForMaskedLM.from_pretrained("ricardoz/BERTugues-base-portuguese-cased")
tokenizer = BertTokenizer.from_pretrained("ricardoz/BERTugues-base-portuguese-cased", do_lower_case=False)
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer, top_k = 3)
pipe('[CLS] Eduardo abriu os [MASK], mas não quis se levantar. Ficou deitado e viu que horas eram.')
句子嵌入创建
from transformers import BertTokenizer, BertModel, pipeline
import torch
model = BertModel.from_pretrained("ricardoz/BERTugues-base-portuguese-cased")
tokenizer = BertTokenizer.from_pretrained("ricardoz/BERTugues-base-portuguese-cased", do_lower_case=False)
input_ids = tokenizer.encode('[CLS] Eduardo abriu os olhos, mas não quis se levantar. Ficou deitado e viu que horas eram.', return_tensors='pt')
with torch.no_grad():
last_hidden_state = model(input_ids).last_hidden_state[:, 0]
last_hidden_state
📄 许可证
许可证类型:其他
📚 详细文档
更多信息请访问我们的GitHub!
📚 引用
如果您在出版物中使用BERTugues,请务必引用它!这将有助于该模型在科学界获得认可和重视。
@article{Zago2024bertugues,
title = {BERTugues: A Novel BERT Transformer Model Pre-trained for Brazilian Portuguese},
volume = {45},
url = {https://ojs.uel.br/revistas/uel/index.php/semexatas/article/view/50630},
DOI = {10.5433/1679-0375.2024.v45.50630},
journal = {Semina: Ciências Exatas e Tecnológicas},
author = {Mazza Zago, Ricardo and Agnoletti dos Santos Pedotti, Luciane},
year = {2024},
month = {Dec.},
pages = {e50630}
}
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)