Videoscore V1.1
模型简介
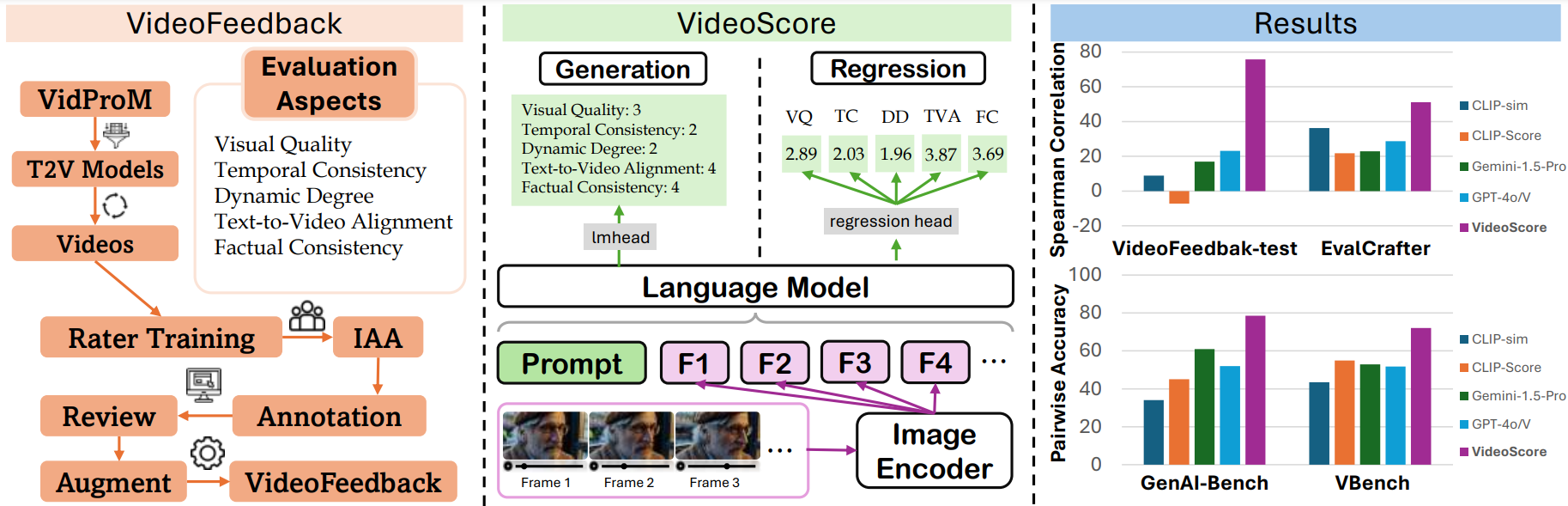
VideoScore系列是用于视频质量评估的模型,能够从多个维度评估AI生成视频的质量,包括视觉质量、时间一致性、动态程度、文本到视频对齐和事实一致性。
模型特点
多维度评估
能够从视觉质量、时间一致性、动态程度、文本到视频对齐和事实一致性五个维度评估视频质量。
高帧数支持
支持处理48帧视频,相比前代模型有显著提升。
高性能
在VideoFeedback-test上达到74.0的Spearman相关性,超越GPT-4o等基线模型。
回归模型
直接输出1.0-4.0的评分,而非分类结果。
模型能力
视频质量评估
多维度评分
文本到视频对齐分析
事实一致性检查
使用案例
AI生成视频评估
视频生成模型评估
评估AI生成视频的质量,为视频生成模型提供反馈。
与人类评估高度一致,Spearman相关性达74.0
视频内容审核
检查生成视频是否符合事实和常识。
在事实一致性维度提供可靠评分
视频质量研究
视频质量基准测试
为视频质量研究提供标准化评估工具。
在GenAI-Bench和VBench上超越最佳基线
🚀 VideoScore-v1.1视频质量评估模型
VideoScore-v1.1是一个视频质量评估模型,以Mantis-8B-Idefics2为基础模型,在大规模视频评估数据集VideoFeedback上训练得到。该模型能从多个维度对视频质量进行评分,与人类评估高度一致,在多个基准测试中表现出色。
🚀 快速开始
你可以通过以下链接快速了解和使用VideoScore-v1.1:
✨ 主要特性
- 新版本优势:尝试使用新版本VideoScore-v1.1,它是VideoScore的变体,在“文本与视频对齐”子分数方面表现更好,并且现在推理时支持48帧。它以Mantis-8B-Idefics2为基础模型,在VideoFeedback数据集上进行训练。
- 模型系列:VideoScore系列是视频质量评估模型系列,以Mantis-8B-Idefics2或Qwen/Qwen2-VL为基础模型,并在VideoFeedback(一个具有多方面人类评分的大型视频评估数据集)上进行训练。
- 评估表现:与VideoScore一样,VideoScore-v1.1在VideoFeedback测试集上与人类评分的Spearman相关性约为75,超过了所有多模态大语言模型(MLLM)提示方法和基于特征的指标。VideoScore-v1.1在另外两个基准测试GenAI-Bench和VBench上也击败了最佳基线,显示出与人类评估的高度一致性。有关这些基准测试的数据详情,请参考VideoScore-Bench。
- 模型类型:VideoScore-v1.1是一个回归版本的模型。
📦 安装指南
你可以使用以下命令安装VideoScore:
pip install git+https://github.com/TIGER-AI-Lab/VideoScore.git
# 或者
# pip install mantis-vl
💻 使用示例
基础用法
以下是一个使用VideoScore-v1.1进行推理的示例代码:
import av
import numpy as np
from typing import List
from PIL import Image
import torch
from transformers import AutoProcessor
from mantis.models.idefics2 import Idefics2ForSequenceClassification
def _read_video_pyav(
frame_paths:List[str],
max_frames:int,
):
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
ROUND_DIGIT=3
REGRESSION_QUERY_PROMPT = """
Suppose you are an expert in judging and evaluating the quality of AI-generated videos,
please watch the following frames of a given video and see the text prompt for generating the video,
then give scores from 5 different dimensions:
(1) visual quality: the quality of the video in terms of clearness, resolution, brightness, and color
(2) temporal consistency, both the consistency of objects or humans and the smoothness of motion or movements
(3) dynamic degree, the degree of dynamic changes
(4) text-to-video alignment, the alignment between the text prompt and the video content
(5) factual consistency, the consistency of the video content with the common-sense and factual knowledge
for each dimension, output a float number from 1.0 to 4.0,
the higher the number is, the better the video performs in that sub-score,
the lowest 1.0 means Bad, the highest 4.0 means Perfect/Real (the video is like a real video)
Here is an output example:
visual quality: 3.2
temporal consistency: 2.7
dynamic degree: 4.0
text-to-video alignment: 2.3
factual consistency: 1.8
For this video, the text prompt is "{text_prompt}",
all the frames of video are as follows:
"""
# MAX_NUM_FRAMES=16
# model_name="TIGER-Lab/VideoScore"
# =======================================
# we support 48 frames in VideoScore-v1.1
# =======================================
MAX_NUM_FRAMES=48
model_name="TIGER-Lab/VideoScore-v1.1"
video_path="video1.mp4"
video_prompt="Near the Elephant Gate village, they approach the haunted house at night. Rajiv feels anxious, but Bhavesh encourages him. As they reach the house, a mysterious sound in the air adds to the suspense."
processor = AutoProcessor.from_pretrained(model_name,torch_dtype=torch.bfloat16)
model = Idefics2ForSequenceClassification.from_pretrained(model_name,torch_dtype=torch.bfloat16).eval()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# sample uniformly 8 frames from the video
container = av.open(video_path)
total_frames = container.streams.video[0].frames
if total_frames > MAX_NUM_FRAMES:
indices = np.arange(0, total_frames, total_frames / MAX_NUM_FRAMES).astype(int)
else:
indices = np.arange(total_frames)
frames = [Image.fromarray(x) for x in _read_video_pyav(container, indices)]
eval_prompt = REGRESSION_QUERY_PROMPT.format(text_prompt=video_prompt)
num_image_token = eval_prompt.count("<image>")
if num_image_token < len(frames):
eval_prompt += "<image> " * (len(frames) - num_image_token)
flatten_images = []
for x in [frames]:
if isinstance(x, list):
flatten_images.extend(x)
else:
flatten_images.append(x)
flatten_images = [Image.open(x) if isinstance(x, str) else x for x in flatten_images]
inputs = processor(text=eval_prompt, images=flatten_images, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
num_aspects = logits.shape[-1]
aspect_scores = []
for i in range(num_aspects):
aspect_scores.append(round(logits[0, i].item(),ROUND_DIGIT))
print(aspect_scores)
"""
model output on visual quality, temporal consistency, dynamic degree,
text-to-video alignment, factual consistency, respectively
VideoScore:
[2.297, 2.469, 2.906, 2.766, 2.516]
VideoScore-v1.1:
[2.328, 2.484, 2.562, 1.969, 2.594]
"""
训练
有关训练的详细信息,请参考VideoScore/training。
评估
有关评估的详细信息,请参考VideoScore/benchmark。
📚 详细文档
评估结果
我们在VideoFeedback测试集上对VideoScore-v1.1进行了测试,并将模型输出与人类评分在所有评估方面的Spearman相关性平均值作为指标。评估结果如下:
| 指标 | VideoFeedback测试集 |
|---|---|
| VideoScore-v1.1 | 74.0 |
| Gemini-1.5-Pro | 22.1 |
| Gemini-1.5-Flash | 20.8 |
| GPT-4o | 23.1 |
| CLIP-sim | 8.9 |
| DINO-sim | 7.5 |
| SSIM-sim | 13.4 |
| CLIP-Score | -7.2 |
| LLaVA-1.5-7B | 8.5 |
| LLaVA-1.6-7B | -3.1 |
| X-CLIP-Score | -1.9 |
| PIQE | -10.1 |
| BRISQUE | -20.3 |
| Idefics2 | 6.5 |
| MSE-dyn | -5.5 |
| SSIM-dyn | -12.9 |
VideoScore系列中的最佳结果用粗体表示,基线中的最佳结果用下划线表示。
📄 许可证
本项目采用MIT许可证。
📖 引用
如果你使用了该模型或相关代码,请引用以下论文:
@article{he2024videoscore,
title = {VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation},
author = {He, Xuan and Jiang, Dongfu and Zhang, Ge and Ku, Max and Soni, Achint and Siu, Sherman and Chen, Haonan and Chandra, Abhranil and Jiang, Ziyan and Arulraj, Aaran and Wang, Kai and Do, Quy Duc and Ni, Yuansheng and Lyu, Bohan and Narsupalli, Yaswanth and Fan, Rongqi and Lyu, Zhiheng and Lin, Yuchen and Chen, Wenhu},
journal = {ArXiv},
year = {2024},
volume={abs/2406.15252},
url = {https://arxiv.org/abs/2406.15252},
}
Xclip Base Patch32
MIT
X-CLIP是CLIP的扩展版本,用于通用视频语言理解,通过对比学习在(视频,文本)对上训练,适用于视频分类和视频-文本检索等任务。
文本生成视频 Transformers 英语
Transformers 英语
X
microsoft
309.80k
84
LTX Video
其他
首个基于DiT的视频生成模型,能够实时生成高质量视频,支持文本转视频和图像+文本转视频两种场景。
文本生成视频 英语
L
Lightricks
165.42k
1,174
Wan2.1 14B VACE GGUF
Apache-2.0
Wan2.1-VACE-14B模型的GGUF格式版本,主要用于文本到视频的生成任务。
文本生成视频
W
QuantStack
146.36k
139
Animatediff Lightning
Openrail
极速文本生成视频模型,生成速度比原版AnimateDiff快十倍以上
文本生成视频
A
ByteDance
144.00k
925
V Express
V-Express是一个基于音频和面部关键点条件生成的视频生成模型,能够将音频输入转换为动态视频输出。
文本生成视频 英语
V
tk93
118.36k
85
Cogvideox 5b
其他
CogVideoX是源自清影的视频生成模型的开源版本,提供高质量的视频生成能力。
文本生成视频 英语
C
THUDM
92.32k
611
Llava NeXT Video 7B Hf
LLaVA-NeXT-Video是一个开源多模态聊天机器人,通过视频和图像数据混合训练获得优秀的视频理解能力,在VideoMME基准上达到开源模型SOTA水平。
文本生成视频 Transformers 英语
L
llava-hf
65.95k
88
Wan2.1 T2V 14B Diffusers
Apache-2.0
万2.1是一套全面开放的视频基础模型,旨在突破视频生成的边界,支持中英文文本生成视频、图像生成视频等多种任务。
文本生成视频 支持多种语言
W
Wan-AI
48.65k
24
Wan2.1 T2V 1.3B Diffusers
Apache-2.0
万2.1是一套全面开放的视频基础模型,具备顶尖性能、支持消费级GPU、多任务支持、视觉文本生成和高效视频VAE等特点。
文本生成视频 支持多种语言
W
Wan-AI
45.29k
38
Wan2.1 T2V 14B
Apache-2.0
万2.1是一套综合性开源视频基础模型,具备文本生成视频、图像生成视频、视频编辑、文本生成图像及视频生成音频等多任务能力,支持中英双语文本生成。
文本生成视频 支持多种语言
W
Wan-AI
44.88k
1,238
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文