🚀 鑫源多模态大模型Xinyuan-VL-2B
鑫源多模态大模型Xinyuan-VL-2B是Cylingo集团推出的一款端侧高性能多模态大模型。它基于Qwen/Qwen2-VL-2B-Instruct进行微调,使用了超500万的多模态数据以及少量纯文本数据进行训练。该模型在多个权威基准测试中表现出色。
🚀 快速开始
为了借助开源社区蓬勃发展的生态,我们选择在Qwen/Qwen2-VL-2B-Instruct的基础上进行微调,从而形成了我们的Cylingo/Xinyuan-VL-2B。因此,使用Cylingo/Xinyuan-VL-2B的方式与使用Qwen/Qwen2-VL-2B-Instruct一致。
💻 使用示例
基础用法
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Cylingo/Xinyuan-VL-2B", torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Cylingo/Xinyuan-VL-2B")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
🔧 评估
我们使用VLMEvalKit工具包对**鑫源多模态大模型XinYuan-VL-2B** 在以下基准测试中进行了评估,发现鑫源多模态大模型XinYuan-VL-2B 表现优于阿里云发布的Qwen/Qwen2-VL-2B-Instruct,以及在开源社区有重大影响力的其他参数规模相当的模型。
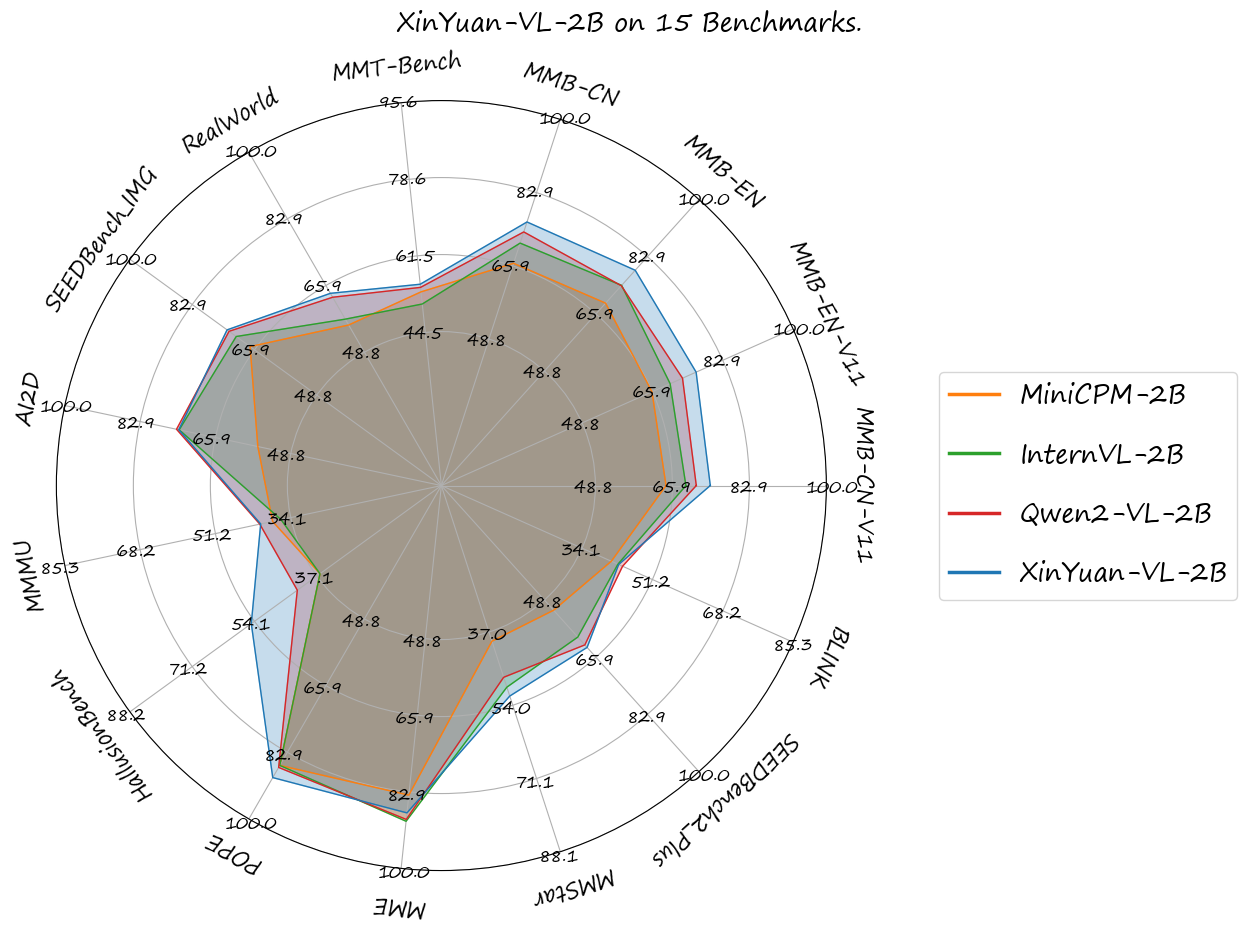
你可以在opencompass/open_vlm_leaderboard中查看具体结果:
| 基准测试 |
MiniCPM - 2B |
InternVL - 2B |
Qwen2 - VL - 2B |
鑫源多模态大模型XinYuan-VL-2B |
| MMB - CN - V11 - Test |
64.5 |
68.9 |
71.2 |
74.3 |
| MMB - EN - V11 - Test |
65.8 |
70.2 |
73.2 |
76.5 |
| MMB - EN |
69.1 |
74.4 |
74.3 |
78.9 |
| MMB - CN |
66.5 |
71.2 |
73.8 |
76.12 |
| CCBench |
45.3 |
74.7 |
53.7 |
55.5 |
| MMT - Bench |
53.5 |
50.8 |
54.5 |
55.2 |
| RealWorld |
55.8 |
57.3 |
62.9 |
63.9 |
| SEEDBench_IMG |
67.1 |
70.9 |
72.86 |
73.4 |
| AI2D |
56.3 |
74.1 |
74.7 |
74.2 |
| MMMU |
38.2 |
36.3 |
41.1 |
40.9 |
| HallusionBench |
36.2 |
36.2 |
42.4 |
55.00 |
| POPE |
86.3 |
86.3 |
86.82 |
89.42 |
| MME |
1808.6 |
1876.8 |
1872.0 |
1854.9 |
| MMStar |
39.1 |
49.8 |
47.5 |
51.87 |
| SEEDBench2_Plus |
51.9 |
59.9 |
62.23 |
62.98 |
| BLINK |
41.2 |
42.8 |
43.92 |
42.98 |
| OCRBench |
605 |
781 |
794 |
782 |
| TextVQA |
74.1 |
73.4 |
79.7 |
77.6 |
📄 许可证
本项目采用Apache-2.0许可证。
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)