模型简介
模型特点
模型能力
使用案例
🚀 MiniCPM-V-2_6-RK3588-1.1.4
MiniCPM-V-2_6的此版本已转换为可在RK3588 NPU上运行,采用了['w8a8', 'w8a8_g128', 'w8a8_g256', 'w8a8_g512']量化方式。该模型已使用以下LoRA进行优化:
兼容RKLLM版本:1.1.4
🔗 实用链接
- 官方RKLLM GitHub
- RockhipNPU Reddit
- EZRKNN-LLM
- 这些开发者的相关内容:marty1885 和 happyme531
- 转换工具:ez-er-rkllm-toolkit
📄 原始模型卡片
以下是基础模型MiniCPM-V-2_6的原始模型卡片:
MiniCPM-V 2.6:适用于手机的单图像、多图像和视频的GPT - 4V级多模态大语言模型
MiniCPM-V 2.6 是MiniCPM-V系列中最新且功能最强大的模型。该模型基于SigLip - 400M和Qwen2 - 7B构建,总参数达80亿。与MiniCPM-Llama3-V 2.5相比,其性能有显著提升,并引入了多图像和视频理解的新特性。MiniCPM-V 2.6的显著特性包括:
- 🔥 卓越性能:在最新版本的OpenCompass综合评估中,MiniCPM-V 2.6在8个流行基准测试中平均得分达到65.2。仅80亿参数的它,在单图像理解方面超越了广泛使用的专有模型,如GPT - 4o mini、GPT - 4V、Gemini 1.5 Pro和Claude 3.5 Sonnet。
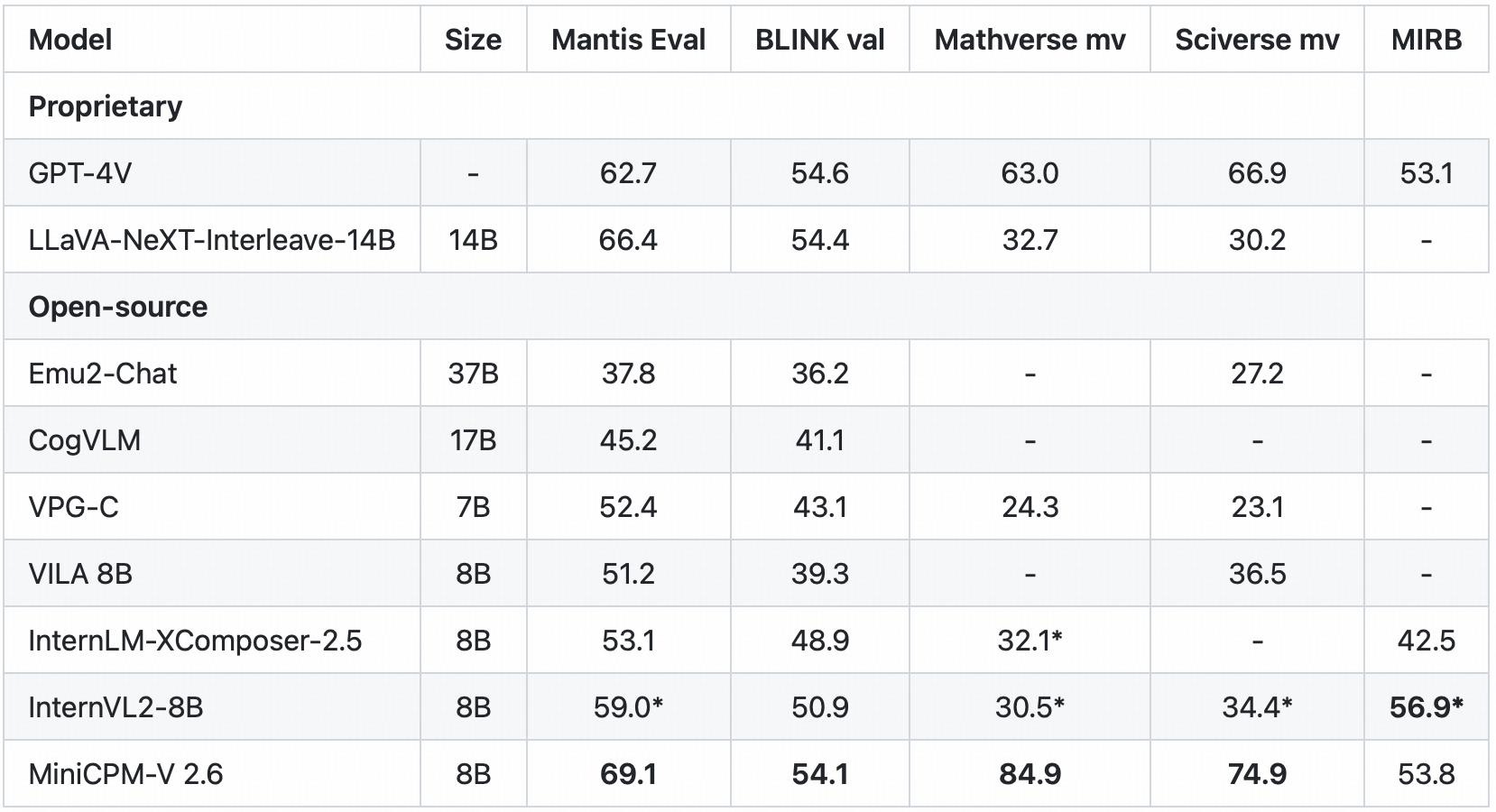
- 🖼️ 多图像理解和上下文学习:MiniCPM-V 2.6能够对多图像进行对话和推理。在Mantis - Eval、BLINK、Mathverse mv和Sciverse mv等流行的多图像基准测试中取得了领先的性能,并展现出了良好的上下文学习能力。
- 🎬 视频理解:MiniCPM-V 2.6可以接受视频输入,进行对话并为时空信息提供密集字幕。在有/无字幕的Video - MME测试中,它的表现优于GPT - 4V、Claude 3.5 Sonnet和LLaVA - NeXT - Video - 34B。
- 💪 强大的OCR能力及其他特性:MiniCPM-V 2.6可以处理任意宽高比、像素高达180万(如1344x1344)的图像。在OCRBench测试中取得了领先的性能,超越了GPT - 4o、GPT - 4V和Gemini 1.5 Pro等专有模型。基于最新的RLAIF-V和VisCPM技术,它具有可靠的行为,在Object HalBench上的幻觉率显著低于GPT - 4o和GPT - 4V,并支持英语、中文、德语、法语、意大利语、韩语等多语言能力。
- 🚀 高效性能:除了模型规模友好外,MiniCPM-V 2.6还展现出了领先的令牌密度(即每个视觉令牌编码的像素数)。处理180万像素图像时仅生成640个令牌,比大多数模型少75%。这直接提高了推理速度、首令牌延迟、内存使用效率和功耗。因此,MiniCPM-V 2.6可以在iPad等终端设备上高效支持实时视频理解。
- 💫 易于使用:MiniCPM-V 2.6可以通过多种方式轻松使用:
🔍 评估结果
单图像评估
在OpenCompass、MME、MMVet、OCRBench、MMMU、MathVista、MMB、AI2D、TextVQA、DocVQA、HallusionBench、Object HalBench等基准测试中的单图像评估结果如下:

多图像评估
在Mantis Eval、BLINK Val、Mathverse mv、Sciverse mv、MIRB等基准测试中的多图像评估结果如下:
视频评估
在Video - MME和Video - ChatGPT等基准测试中的视频评估结果如下:

点击查看TextVQA、VizWiz、VQAv2、OK - VQA的少样本评估结果。

📷 示例展示





点击查看更多示例。


我们在终端设备上部署了MiniCPM-V 2.6。演示视频是在iPad Pro上未经编辑的原始屏幕录制。




💻 演示体验
点击此处尝试MiniCPM-V 2.6的演示。
💻 使用示例
基础用法
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
## if you want to use streaming, please make sure sampling=True and stream=True
## the model.chat will return a generator
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')
高级用法
多图像对话
点击查看使用多图像输入运行MiniCPM-V 2.6的Python代码。
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
上下文少样本学习
点击查看使用少样本输入运行MiniCPM-V 2.6的Python代码。
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')
msgs = [
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
{'role': 'user', 'content': [image_test, question]}
]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
视频对话
点击查看使用视频输入运行MiniCPM-V 2.6的Python代码。
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path ="video_test.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params={}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)
更多使用细节请查看GitHub。
📦 llama.cpp推理
MiniCPM-V 2.6可以使用llama.cpp运行。更多细节请查看我们的llama.cpp分支。
📦 Int4量化版本
下载Int4量化版本以减少GPU内存(7GB)使用:MiniCPM-V-2_6-int4。
📄 许可证
模型许可证
- 本仓库中的代码遵循Apache - 2.0许可证发布。
- MiniCPM-V系列模型权重的使用必须严格遵循MiniCPM模型许可证。
- MiniCPM的模型和权重完全免费用于学术研究。填写“问卷”进行注册后,MiniCPM-V 2.6的权重也可免费用于商业用途。
声明
- 作为一个多模态大语言模型,MiniCPM-V 2.6通过学习大量的多模态语料生成内容,但它无法理解、表达个人观点或进行价值判断。MiniCPM-V 2.6生成的任何内容均不代表模型开发者的观点和立场。
- 我们不对使用MinCPM-V模型所产生的任何问题负责,包括但不限于数据安全问题、舆论风险,或因模型的误导、误用、传播或滥用而产生的任何风险和问题。
🔍 关键技术及其他多模态项目
👏 欢迎探索MiniCPM-V 2.6的关键技术以及我们团队的其他多模态项目: VisCPM | RLHF-V | LLaVA-UHD | RLAIF-V
📚 引用
如果您觉得我们的工作有帮助,请考虑引用我们的论文 📝 并给这个项目点赞 ❤️!
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)