🚀 Karlo v1 alpha
Karlo是一个基于文本条件的图像生成模型,它基于OpenAI的unCLIP架构构建。该模型对标准超分辨率模型进行了改进,能在少量去噪步骤内将图像从64px提升至256px,并恢复高频细节。
🚀 快速开始
Karlo可通过diffusers库使用!
📦 安装指南
pip install diffusers transformers accelerate safetensors
💻 使用示例
基础用法
文本转图像
from diffusers import UnCLIPPipeline
import torch
pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
prompt = "a high-resolution photograph of a big red frog on a green leaf."
image = pipe([prompt]).images[0]
image.save("./frog.png")

图像变体生成
from diffusers import UnCLIPImageVariationPipeline
import torch
from PIL import Image
pipe = UnCLIPImageVariationPipeline.from_pretrained("kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16)
pipe = pipe.to('cuda')
image = Image.open("./frog.png")
image = pipe(image).images[0]
image.save("./frog-variation.png")

📚 详细文档
模型架构概述
Karlo是一个基于unCLIP的文本条件扩散模型,由先验模块(Prior)、解码器(Decoder)和超分辨率模块(SR)组成。在本仓库中,我们包含了标准超分辨率模块的改进版本,它仅需7个反向步骤就能将64px的图像提升至256px,如下图所示:
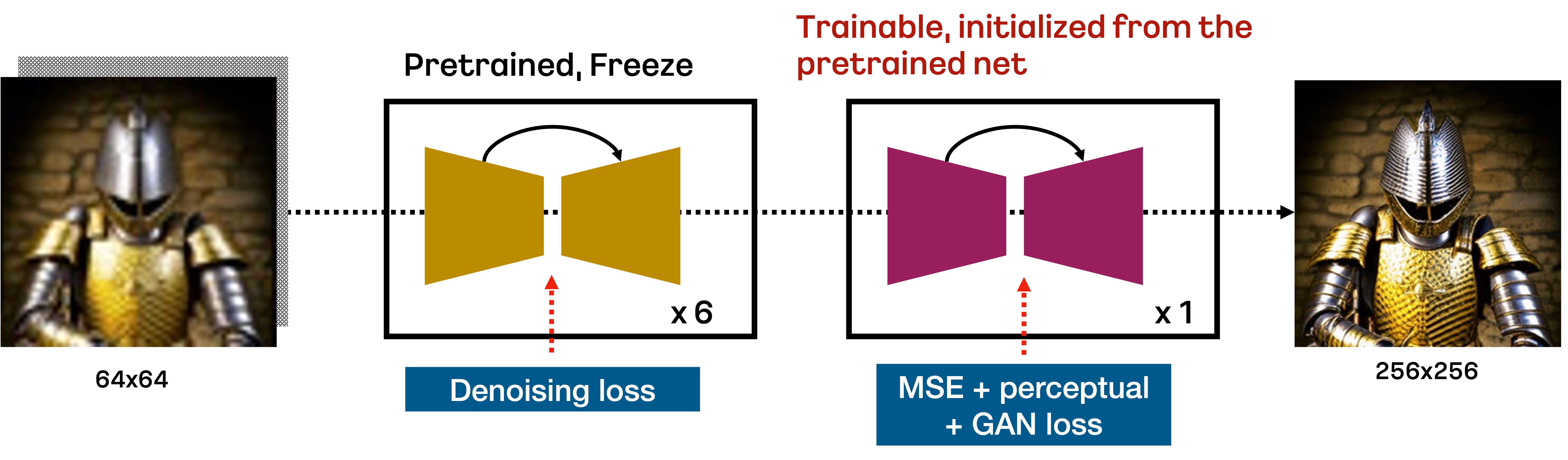
具体来说,基于DDPM目标训练的标准SR模块,根据重采样技术在前6个去噪步骤中将64px的图像提升至256px。然后,由VQ - GAN风格损失训练的额外微调SR模块执行最后一个反向步骤,以恢复高频细节。我们发现这种方法在少量反向步骤内提升低分辨率图像非常有效。
模型架构细节
我们在包含COYO - 100M、CC3M和CC12M的1.15亿个图像 - 文本对上从头开始训练所有组件。对于先验模块和解码器,我们使用OpenAI的CLIP仓库提供的ViT - L/14。与unCLIP的原始实现不同,为了提高效率,我们将解码器中的可训练变压器替换为ViT - L/14中的文本编码器。对于SR模块,我们首先使用DDPM目标在100万步内训练模型,然后再进行额外的23.4万步来微调额外的组件。下表总结了我们各组件的重要统计信息:
| 组件 |
先验模块(Prior) |
解码器(Decoder) |
超分辨率模块(SR) |
| CLIP |
ViT - L/14 |
ViT - L/14 |
- |
| 参数数量 |
10亿 |
9亿 |
7亿 + 7亿 |
| 优化步数 |
100万 |
100万 |
100万 + 20万 |
| 采样步数 |
25 |
50(默认), 25(快速) |
7 |
| 检查点链接 |
[ViT - L - 14](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/096db1af569b284eb76b3881534822d9/ViT - L - 14.pt), [ViT - L - 14统计信息](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT - L - 14_stats.th), [模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior - ckpt - step%3D01000000 - of - 01000000.ckpt) |
[模型](https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved - sr - ckpt - step%3D1.2M.ckpt) |
在检查点链接中,ViT - L - 14与原始版本等效,但为了方便我们将其包含在内。我们还需注意,ViT - L - 14 - stats是归一化先验模块输出所必需的。
模型评估
我们在CC3M和MS - COCO的验证集上定量评估了Karlo - v1.0.alpha的性能。下表展示了CLIP分数和FID。为了测量FID,我们将较短边的图像调整为256px,然后在中心进行裁剪。在所有情况下,我们将先验模块和解码器的无分类器引导尺度分别设置为4和8。我们发现,即使解码器仅进行25个采样步骤,我们的模型也能取得合理的性能。
CC3M
| 采样步骤 |
CLIP分数(ViT - B/16) |
FID(验证集13k张图像) |
| 先验模块(25) + 解码器(25) + 超分辨率模块(7) |
0.3081 |
14.37 |
| 先验模块(25) + 解码器(50) + 超分辨率模块(7) |
0.3086 |
13.95 |
MS - COCO
| 采样步骤 |
CLIP分数(ViT - B/16) |
FID(验证集30k张图像) |
| 先验模块(25) + 解码器(25) + 超分辨率模块(7) |
0.3192 |
15.24 |
| 先验模块(25) + 解码器(50) + 超分辨率模块(7) |
0.3192 |
14.43 |
更多信息,请参考即将发布的技术报告。
训练细节
此Karlo的alpha版本在1.15亿个图像 - 文本对上进行训练,包括[COYO](https://github.com/kakaobrain/coyo - dataset) - 100M高质量子集、CC3M和CC12M。对于那些对在更大规模高质量数据集上训练的更好版本的Karlo感兴趣的人,请访问我们的应用B^DISCOVER的主页。
📄 许可证
本项目采用CreativeML OpenRAIL - M许可证。
BibTex
如果您在研究中发现本仓库有用,请引用:
@misc{kakaobrain2022karlo-v1-alpha,
title = {Karlo-v1.0.alpha on COYO-100M and CC15M},
author = {Donghoon Lee, Jiseob Kim, Jisu Choi, Jongmin Kim, Minwoo Byeon, Woonhyuk Baek and Saehoon Kim},
year = {2022},
howpublished = {\url{https://github.com/kakaobrain/karlo}},
}
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)