🚀 无参考对齐扩散模型的边际感知偏好优化
我们提出了 MaPO,这是一种无参考、样本高效且节省内存的文本到图像扩散模型对齐技术。有关该技术的更多详细信息,请参阅我们的论文 点击查看。
👥 开发者
- 洪智宇* (韩国科学技术院人工智能系)
- 赛亚克·保罗* (Hugging Face)
- 诺亚·李 (韩国科学技术院人工智能系)
- 卡希夫·拉苏尔 (Hugging Face)
- 詹姆斯·索恩 (韩国科学技术院人工智能系)
- 郑正宪 (韩国大学)
📊 数据集
该模型是在 yuvalkirstain/pickapic_v2 数据集上对 Stable Diffusion XL 进行微调得到的。
💻 训练代码
请参考我们的代码仓库 点击查看。
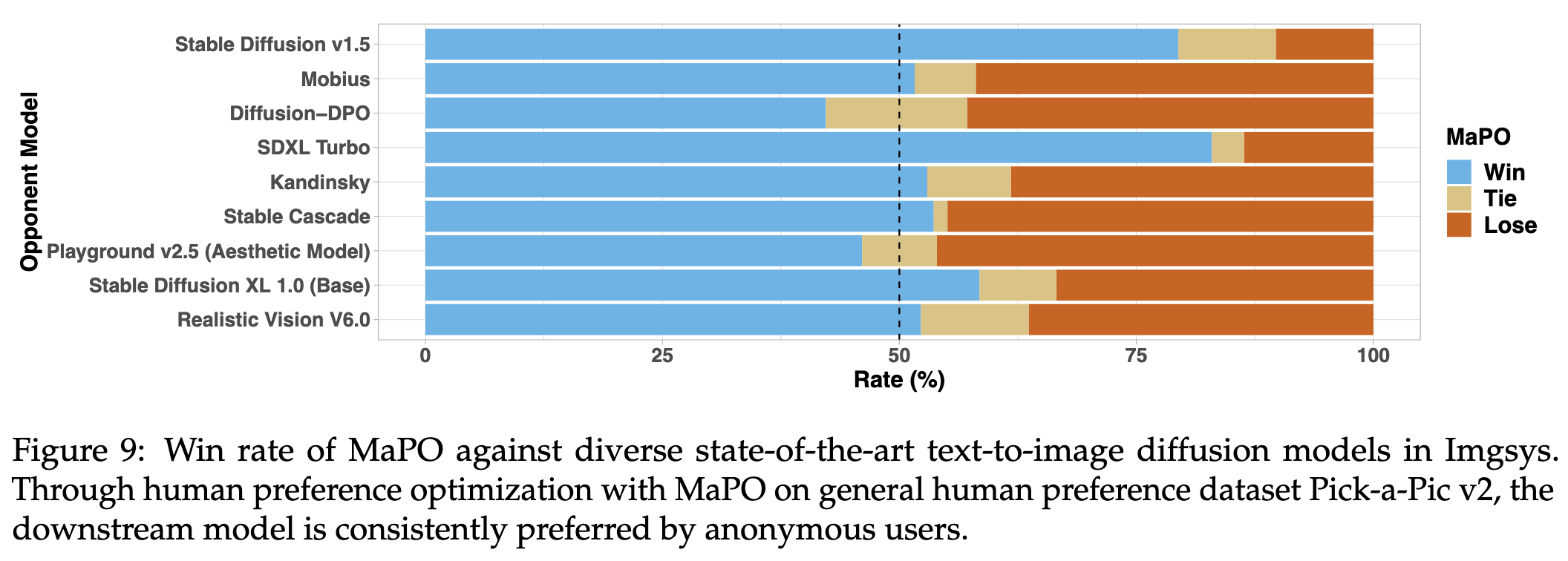
🖼️ 定性比较
📈 结果
下面我们报告一些定量指标,并使用这些指标将 MaPO 与现有模型进行比较:
| 模型 |
美学得分 |
HPS v2.1 得分 |
Pickscore 得分 |
| SDXL |
6.03 |
30.0 |
22.4 |
| SFTChosen |
5.95 |
29.6 |
22.0 |
| Diffusion-DPO |
6.03 |
31.1 |
22.7 |
| MaPO (我们的模型) |
6.17 |
31.2 |
22.5 |
我们在 Imgsys 公开基准测试中评估了该检查点。在撰写本文时,MaPO 在排行榜上排名第 7,能够在 25 个最先进的文本到图像扩散模型中超越或匹配其中 21 个,而 Diffusion-DPO 排名第 20。同时,在适配 Pick-a-Pic v2 时,MaPO 的实际训练时间减少了 14.5%。我们感谢 Imgsys 团队帮助我们获取人类偏好数据。
下表报告了 MaPO 的内存效率,使其成为扩散模型对齐微调的更好选择:
| 指标 |
Diffusion-DPO |
MaPO (我们的模型) |
| 时间 (越低越好) |
63.5 |
54.3 (-14.5%) |
| GPU 内存 (越低越好) |
55.9 |
46.1 (-17.5%) |
| 最大批次大小 (越高越好) |
4 |
16 (×4) |
💻 使用示例
基础用法
from diffusers import DiffusionPipeline, AutoencoderKL, UNet2DConditionModel
import torch
sdxl_id = "stabilityai/stable-diffusion-xl-base-1.0"
vae_id = "madebyollin/sdxl-vae-fp16-fix"
unet_id = "mapo-t2i/mapo-beta"
vae = AutoencoderKL.from_pretrained(vae_id, torch_dtype=torch.float16)
unet = UNet2DConditionModel.from_pretrained(unet_id, torch_dtype=torch.float16)
pipeline = DiffusionPipeline.from_pretrained(sdxl_id, vae=vae, unet=unet, torch_dtype=torch.float16).to("cuda")
prompt = "An abstract portrait consisting of bold, flowing brushstrokes against a neutral background."
image = pipeline(prompt=prompt, num_inference_steps=30).images[0]
如需查看定性结果,请访问我们的 项目网站。
📚 引用
@misc{hong2024marginaware,
title={Margin-aware Preference Optimization for Aligning Diffusion Models without Reference},
author={Jiwoo Hong and Sayak Paul and Noah Lee and Kashif Rasul and James Thorne and Jongheon Jeong},
year={2024},
eprint={2406.06424},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
📄 许可证
openrail++


 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)