Qwen2.5 Omni 3B GGUF
模型简介
这是一个支持多模态交互的AI模型,能够处理文本、图像、音频和视频输入,并生成相应的文本和语音输出。
模型特点
全模态支持
能够同时处理文本、图像、音频和视频输入
流式生成
支持实时流式生成文本和自然语音响应
新颖架构
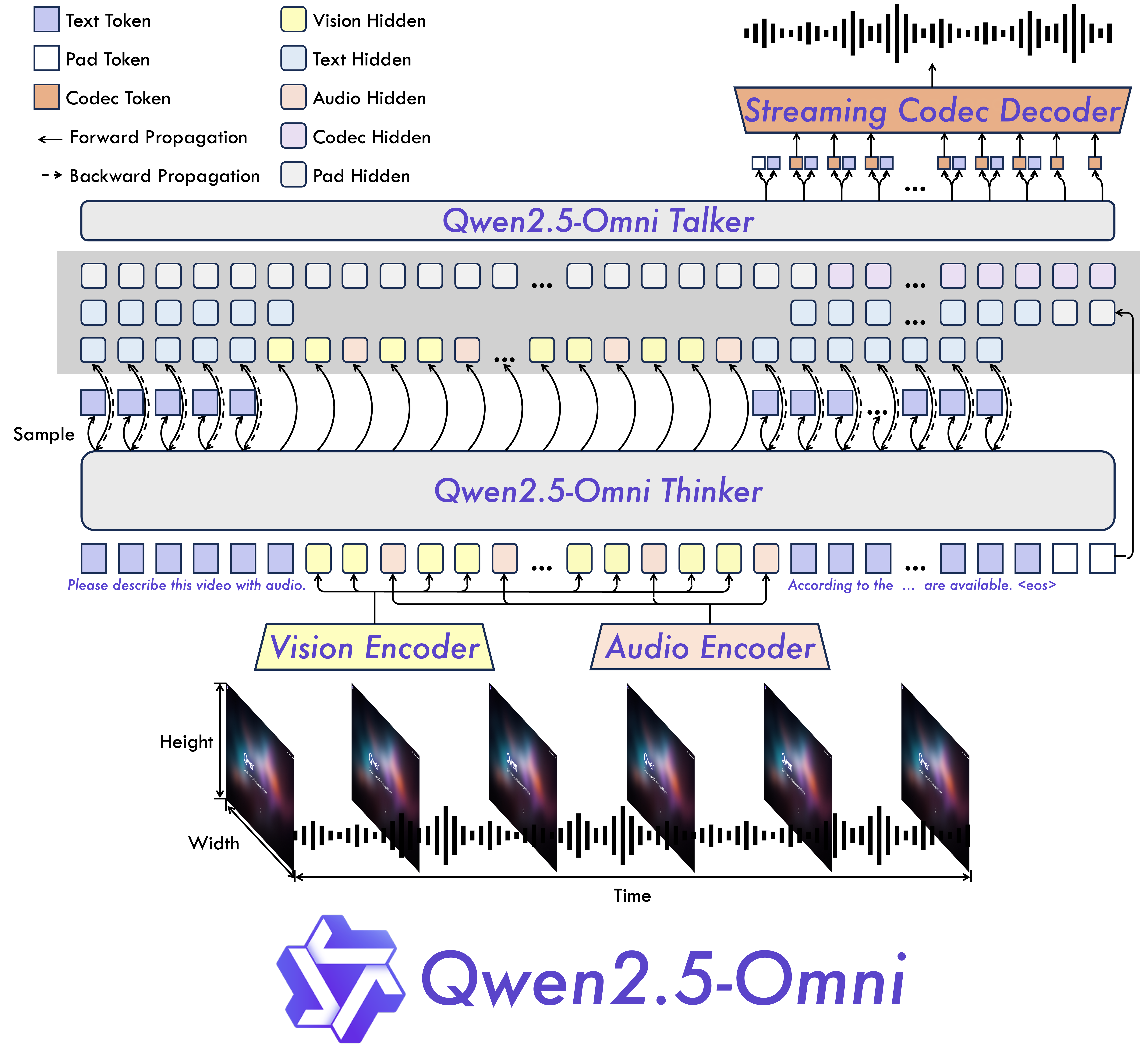
采用Thinker-Talker架构和TMRoPE位置编码
高性能语音生成
在语音生成方面超越许多现有方案,具有卓越的鲁棒性和自然度
模型能力
文本理解与生成
图像分析
语音识别
语音合成
视频理解
多模态推理
实时交互
使用案例
智能助手
实时语音对话
支持自然流畅的语音对话交互
在VoiceBench测试中表现优异
内容理解
多模态内容分析
同时分析图像、视频和音频内容
在MMAU音频理解测试中达到63.3%准确率
翻译服务
语音翻译
实现多种语言间的语音翻译
在CoVoST2测试中英语-德语翻译达到30.2 BLEU分数
🚀 NexaAI/Qwen2.5-Omni-3B-GGUF
Qwen2.5-Omni-3B-GGUF 是一个端到端的多模态模型,能够感知文本、图像、音频和视频等多种模态信息,同时以流式方式生成文本和自然语音响应,为多模态交互提供了强大的支持。
🚀 快速开始
安装 nexa-sdk 后即可直接运行。在 nexa-sdk 命令行界面中执行以下命令:
NexaAI/Qwen2.5-Omni-3B-GGUF
可用的量化版本
| 文件名 | 量化类型 | 文件大小 | 拆分 | 描述 |
|---|---|---|---|---|
| Qwen2.5-Omni-3B-4bit.gguf | 4bit | 2.1 GB | false | 轻量级 4 位量化,用于快速推理。 |
| Qwen2.5-Omni-3B-Q8_0.gguf | Q8_0 | 3.62 GB | false | 高质量 8 位量化。 |
| Qwen2.5-Omni-3Bq2_k.gguf | Q2_K | 4 Bytes | false | 2 位量化,最适合极低资源使用场景。 |
| mmproj-Qwen2.5-Omni-3B-Q8_0.gguf | Q8_0 | 1.54 GB | false | Q8_0 模型所需的视觉适配器。 |
✨ 主要特性
- 全模态与新颖架构:提出了 Thinker - Talker 架构,这是一种端到端的多模态模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式方式同步生成文本和自然语音响应。此外,还提出了一种新颖的位置嵌入,名为 TMRoPE(时间对齐多模态旋转位置编码),用于同步视频输入与音频的时间戳。
- 实时语音和视频聊天:架构专为全实时交互而设计,支持分块输入和即时输出。
- 自然且强大的语音生成:在语音生成方面超越了许多现有的流式和非流式替代方案,展现出卓越的鲁棒性和自然度。
- 跨模态的强大性能:与同等规模的单模态模型相比,在所有模态上均表现出色。Qwen2.5 - Omni 在音频能力上优于同等规模的 Qwen2 - Audio,并且在性能上与 Qwen2.5 - VL - 7B 相当。
- 出色的端到端语音指令遵循能力:Qwen2.5 - Omni 在端到端语音指令遵循方面的表现与其在文本输入时的有效性相媲美,这在 MMLU 和 GSM8K 等基准测试中得到了证明。
📚 详细文档
模型架构
性能评估
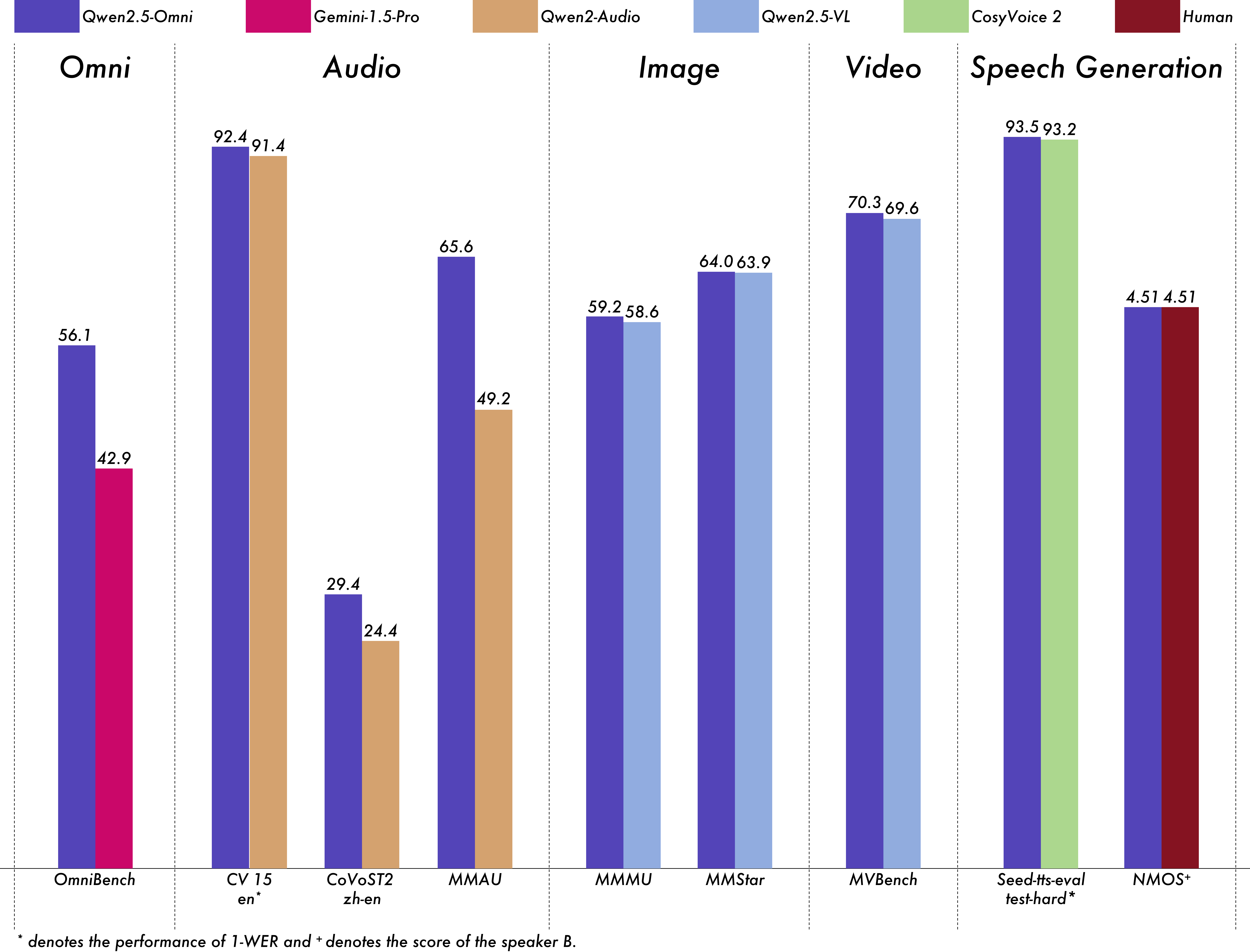
我们对 Qwen2.5 - Omni 进行了全面评估,与同等规模的单模态模型和闭源模型(如 Qwen2.5 - VL - 7B、Qwen2 - Audio 和 Gemini - 1.5 - pro)相比,它在所有模态上均表现出强大的性能。在需要整合多种模态的任务中,如 OmniBench,Qwen2.5 - Omni 达到了最先进的性能水平。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)和语音生成(Seed - tts - eval 和主观自然度)等领域表现出色。
多模态 -> 文本
| 数据集 | 模型 | 性能 |
|---|---|---|
语音 | 声音事件 | 音乐 | 平均 |
Gemini - 1.5 - Pro | 42.67%|42.26%|46.23%|42.91% |
| MIO - Instruct | 36.96%|33.58%|11.32%|33.80% | |
| AnyGPT (7B) | 17.77%|20.75%|13.21%|18.04% | |
| video - SALMONN | 34.11%|31.70%|56.60%|35.64% | |
| UnifiedIO2 - xlarge | 39.56%|36.98%|29.25%|38.00% | |
| UnifiedIO2 - xxlarge | 34.24%|36.98%|24.53%|33.98% | |
| MiniCPM - o | -|-|-|40.50% | |
| Baichuan - Omni - 1.5 | -|-|-|42.90% | |
| Qwen2.5 - Omni - 3B | 52.14%|52.08%|52.83%|52.19% | |
| Qwen2.5 - Omni - 7B | 55.25%|60.00%|52.83%|56.13% |
音频 -> 文本
自动语音识别(ASR)
| 数据集 | 模型 | 性能 |
|---|---|---|
Librispeech 开发集 - 干净 | 开发集 - 其他 | 测试集 - 干净 | 测试集 - 其他 |
SALMONN | -|-|2.1|4.9 |
| SpeechVerse | -|-|2.1|4.4 | |
| Whisper - large - v3 | -|-|1.8|3.6 | |
| Llama - 3 - 8B | -|-|-|3.4 | |
| Llama - 3 - 70B | -|-|-|3.1 | |
| Seed - ASR - Multilingual | -|-|1.6|2.8 | |
| MiniCPM - o | -|-|1.7| - | |
| MinMo | -|-|1.7|3.9 | |
| Qwen - Audio | 1.8|4.0|2.0|4.2 | |
| Qwen2 - Audio | 1.3|3.4|1.6|3.6 | |
| Qwen2.5 - Omni - 3B | 2.0|4.1|2.2|4.5 | |
| Qwen2.5 - Omni - 7B | 1.6|3.5|1.8|3.4 | |
Common Voice 15 英语 | 中文 | 粤语 | 法语 |
Whisper - large - v3 | 9.3|12.8|10.9|10.8 |
| MinMo | 7.9|6.3|6.4|8.5 | |
| Qwen2 - Audio | 8.6|6.9|5.9|9.6 | |
| Qwen2.5 - Omni - 3B | 9.1|6.0|11.6|9.6 | |
| Qwen2.5 - Omni - 7B | 7.6|5.2|7.3|7.5 | |
Fleurs 中文 | 英语 |
Whisper - large - v3 | 7.7|4.1 |
| Seed - ASR - Multilingual | -|3.4 | |
| Megrez - 3B - Omni | 10.8| - | |
| MiniCPM - o | 4.4| - | |
| MinMo | 3.0|3.8 | |
| Qwen2 - Audio | 7.5| - | |
| Qwen2.5 - Omni - 3B | 3.2|5.4 | |
| Qwen2.5 - Omni - 7B | 3.0|4.1 | |
Wenetspeech 测试集 - 网络 | 测试集 - 会议 |
Seed - ASR - Chinese | 4.7|5.7 |
| Megrez - 3B - Omni | -|16.4 | |
| MiniCPM - o | 6.9| - | |
| MinMo | 6.8|7.4 | |
| Qwen2.5 - Omni - 3B | 6.3|8.1 | |
| Qwen2.5 - Omni - 7B | 5.9|7.7 | |
Voxpopuli - V1.0 - en |
Llama - 3 - 8B | 6.2 |
| Llama - 3 - 70B | 5.7 | |
| Qwen2.5 - Omni - 3B | 6.6 | |
| Qwen2.5 - Omni - 7B | 5.8 |
语音到文本翻译(S2TT)
| 数据集 | 模型 | 性能 |
|---|---|---|
CoVoST2 英语 - 德语 | 德语 - 英语 | 英语 - 中文 | 中文 - 英语 |
SALMONN | 18.6| -|33.1| - |
| SpeechLLaMA | -|27.1| -|12.3 | |
| BLSP | 14.1| -| -| - | |
| MiniCPM - o | -| -|48.2|27.2 | |
| MinMo | -|39.9|46.7|26.0 | |
| Qwen - Audio | 25.1|33.9|41.5|15.7 | |
| Qwen2 - Audio | 29.9|35.2|45.2|24.4 | |
| Qwen2.5 - Omni - 3B | 28.3|38.1|41.4|26.6 | |
| Qwen2.5 - Omni - 7B | 30.2|37.7|41.4|29.4 |
语音情感识别(SER)
| 数据集 | 模型 | 性能 |
|---|---|---|
Meld |
WavLM - large | 0.542 |
| MiniCPM - o | 0.524 | |
| Qwen - Audio | 0.557 | |
| Qwen2 - Audio | 0.553 | |
| Qwen2.5 - Omni - 3B | 0.558 | |
| Qwen2.5 - Omni - 7B | 0.570 |
语音声音分类(VSC)
| 数据集 | 模型 | 性能 |
|---|---|---|
VocalSound |
CLAP | 0.495 |
| Pengi | 0.604 | |
| Qwen - Audio | 0.929 | |
| Qwen2 - Audio | 0.939 | |
| Qwen2.5 - Omni - 3B | 0.936 | |
| Qwen2.5 - Omni - 7B | 0.939 |
音乐相关任务
| 数据集 | 模型 | 性能 |
|---|---|---|
GiantSteps Tempo |
Llark - 7B | 0.86 |
| Qwen2.5 - Omni - 3B | 0.88 | |
| Qwen2.5 - Omni - 7B | 0.88 | |
MusicCaps |
LP - MusicCaps | 0.291|0.149|0.089|0.061|0.129|0.130 |
| Qwen2.5 - Omni - 3B | 0.325|0.163|0.093|0.057|0.132|0.229 | |
| Qwen2.5 - Omni - 7B | 0.328|0.162|0.090|0.055|0.127|0.225 |
音频推理
| 数据集 | 模型 | 性能 |
|---|---|---|
MMAU 声音 | 音乐 | 语音 | 平均 |
Gemini - Pro - V1.5 | 56.75|49.40|58.55|54.90 |
| Qwen2 - Audio | 54.95|50.98|42.04|49.20 | |
| Qwen2.5 - Omni - 3B | 70.27|60.48|59.16|63.30 | |
| Qwen2.5 - Omni - 7B | 67.87|69.16|59.76|65.60 |
语音聊天
| 数据集 | 模型 | 性能 |
|---|---|---|
VoiceBench AlpacaEval | CommonEval | SD - QA | MMSU |
Ultravox - v0.4.1 - LLaMA - 3.1 - 8B | 4.55|3.90|53.35|47.17 |
| MERaLiON | 4.50|3.77|55.06|34.95 | |
| Megrez - 3B - Omni | 3.50|2.95|25.95|27.03 | |
| Lyra - Base | 3.85|3.50|38.25|49.74 | |
| MiniCPM - o | 4.42|4.15|50.72|54.78 | |
| Baichuan - Omni - 1.5 | 4.50|4.05|43.40|57.25 | |
| Qwen2 - Audio | 3.74|3.43|35.71|35.72 | |
| Qwen2.5 - Omni - 3B | 4.32|4.00|49.37|50.23 | |
| Qwen2.5 - Omni - 7B | 4.49|3.93|55.71|61.32 | |
VoiceBench OpenBookQA | IFEval | AdvBench | 平均 |
Ultravox - v0.4.1 - LLaMA - 3.1 - 8B | 65.27|66.88|98.46|71.45 |
| MERaLiON | 27.23|62.93|94.81|62.91 | |
| Megrez - 3B - Omni | 28.35|25.71|87.69|46.25 | |
| Lyra - Base | 72.75|36.28|59.62|57.66 | |
| MiniCPM - o | 78.02|49.25|97.69|71.69 | |
| Baichuan - Omni - 1.5 | 74.51|54.54|97.31|71.14 | |
| Qwen2 - Audio | 49.45|26.33|96.73|55.35 | |
| Qwen2.5 - Omni - 3B | 74.73|42.10|98.85|68.81 | |
| Qwen2.5 - Omni - 7B | 81.10|52.87|99.42|74.12 |
图像 -> 文本
| 数据集 | Qwen2.5 - Omni - 7B | Qwen2.5 - Omni - 3B | 其他最佳 | Qwen2.5 - VL - 7B | GPT - 4o - mini |
|---|---|---|---|---|---|
| MMMU验证集 | 59.2 | 53.1 | 53.9 | 58.6 | 60.0 |
| MMMU - Pro总体 | 36.6 | 29.7 | - | 38.3 | 37.6 |
| MathVista测试集 - 迷你 | 67.9 | 59.4 | 71.9 | 68.2 | 52.5 |
| MathVision完整集 | 25.0 | 20.8 | 23.1 | 25.1 | - |
| MMBench - V1.1 - EN测试集 | 81.8 | 77.8 | 80.5 | 82.6 | 76.0 |
| MMVet加速版 | 66.8 | 62.1 | 67.5 | 67.1 | 66.9 |
| MMStar | 64.0 | 55.7 | 64.0 | 63.9 | 54.8 |
| MME总和 | 2340 | 2117 | 2372 | 2347 | 2003 |
| MuirBench | 59.2 | 48.0 | - | 59.2 | - |
| CRPE关系 | 76.5 | 73.7 | - | 76.4 | - |
| RealWorldQA平均 | 70.3 | 62.6 | 71.9 | 68.5 | - |
| MME - RealWorld英语 | 61.6 | 55.6 | - | 57.4 | - |
| MM - MT - Bench | 6.0 | 5.0 | - | 6.3 | - |
| AI2D | 83.2 | 79.5 | 85.8 | 83.9 | - |
| TextVQA验证集 | 84.4 | 79.8 | 83.2 | 84.9 | - |
| DocVQA测试集 | 95.2 | 93.3 | 93.5 | 95.7 | - |
| ChartQA测试集 - 平均 | 85.3 | 82.8 | 84.9 | 87.3 | - |
| OCRBench_V2英语 | 57.8 | 51.7 | - | 56.3 | - |
| 数据集 | Qwen2.5 - Omni - 7B | Qwen2.5 - Omni - 3B | Qwen2.5 - VL - 7B | Grounding DINO | Gemini 1.5 Pro |
|---|---|---|---|---|---|
| Refcoco验证集 | 90.5 | 88.7 | 90.0 | 90.6 | 73.2 |
| Refcoco文本A | 93.5 | 91.8 | 92.5 | 93.2 | 72.9 |
| Refcoco文本B | 86.6 | 84.0 | 85.4 | 88.2 | 74.6 |
| Refcoco +验证集 | 85.4 | 81.1 | 84.2 | 88.2 | 62.5 |
| Refcoco +文本A | 91.0 | 87.5 | 89.1 | 89.0 | 63.9 |
| Refcoco +文本B | 79.3 | 73.2 | 76.9 | 75.9 | 65.0 |
| Refcocog +验证集 | 87.4 | 85.0 | 87.2 | 86.1 | 75.2 |
| Refcocog +测试集 | 87.9 | 85.1 | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 39.2 | 37.3 | 55.0 | 36.7 |
| PointGrounding | 66.5 | 46.2 | 67.3 | - | - |
视频(无音频) -> 文本
| 数据集 | Qwen2.5 - Omni - 7B | Qwen2.5 - Omni - 3B | 其他最佳 | Qwen2.5 - VL - 7B | GPT - 4o - mini |
|---|---|---|---|---|---|
| Video - MME[具体部分缺失,原文未完整] | [具体性能未知] | [具体性能未知] | [具体性能未知] | [具体性能未知] | [具体性能未知] |
📄 许可证
本项目采用 qwen - research 许可证。
Codebert Base
CodeBERT是一个面向编程语言与自然语言的预训练模型,基于RoBERTa架构,支持代码搜索和代码生成文档等功能。
多模态融合
C
microsoft
1.6M
248
Llama 4 Scout 17B 16E Instruct
其他
Llama 4 Scout是Meta开发的多模态AI模型,采用混合专家架构,支持12种语言的文本和图像交互,具有17B激活参数和109B总参数。
多模态融合 Transformers 支持多种语言
Transformers 支持多种语言
L
meta-llama
817.62k
844
Unixcoder Base
Apache-2.0
UniXcoder是一个统一的多模态预训练模型,利用代码注释和抽象语法树等多模态数据预训练代码表示。
多模态融合 Transformers 英语
U
microsoft
347.45k
51
TITAN
TITAN是一个多模态全切片基础模型,通过视觉自监督学习和视觉-语言对齐进行预训练,用于病理学图像分析。
多模态融合 Safetensors 英语
Safetensors 英语
Safetensors 英语T
MahmoodLab
213.39k
37
Qwen2.5 Omni 7B
其他
Qwen2.5-Omni 是一个端到端的多模态模型,能够感知文本、图像、音频和视频等多种模态,并以流式方式生成文本和自然语音响应。
多模态融合 Transformers 英语
Q
Qwen
206.20k
1,522
Minicpm O 2 6
MiniCPM-o 2.6是一款手机端运行的GPT-4o级多模态大模型,支持视觉、语音与直播流处理
多模态融合 Transformers 其他
M
openbmb
178.38k
1,117
Llama 4 Scout 17B 16E Instruct
其他
Llama 4 Scout是Meta推出的17B参数/16专家混合的多模态AI模型,支持12种语言和图像理解,具有行业领先性能。
多模态融合 Transformers 支持多种语言
L
chutesai
173.52k
2
Qwen2.5 Omni 3B
其他
Qwen2.5-Omni是一款端到端多模态模型,能够感知文本、图像、音频和视频等多种模态信息,并以流式方式同步生成文本和自然语音响应。
多模态融合 Transformers 英语
Q
Qwen
48.07k
219
One Align
MIT
Q-Align是一个多任务视觉评估模型,专注于图像质量评估(IQA)、美学评估(IAA)和视频质量评估(VQA),在ICML2024上发表。
多模态融合 Transformers
O
q-future
39.48k
25
Biomedvlp BioViL T
MIT
BioViL-T是一个专注于分析胸部X光片和放射学报告的视觉语言模型,通过时序多模态预训练提升性能。
多模态融合 Transformers 英语
B
microsoft
26.39k
35
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文