模型简介
模型特点
模型能力
使用案例
🚀 OpenReasoning-Nemotron-1.5B 概述
OpenReasoning-Nemotron-1.5B 是一个大语言模型(LLM),它基于 Qwen2.5-1.5B-Instruct(即参考模型)衍生而来。这是一个推理模型,经过了针对数学、代码和科学解决方案生成的后训练。我们对该模型进行了高达 64K 输出令牌的评估。OpenReasoning 模型有 1.5B、7B、14B 和 32B 等不同规模可供选择。
此模型可用于商业/非商业研究。
许可证/使用条款
- 适用条款:上述模型的使用受 知识共享署名 4.0 国际许可协议(CC-BY-4.0) 约束。
- 附加信息:Apache 2.0 许可证
✨ 主要特性
推理基准测试成绩
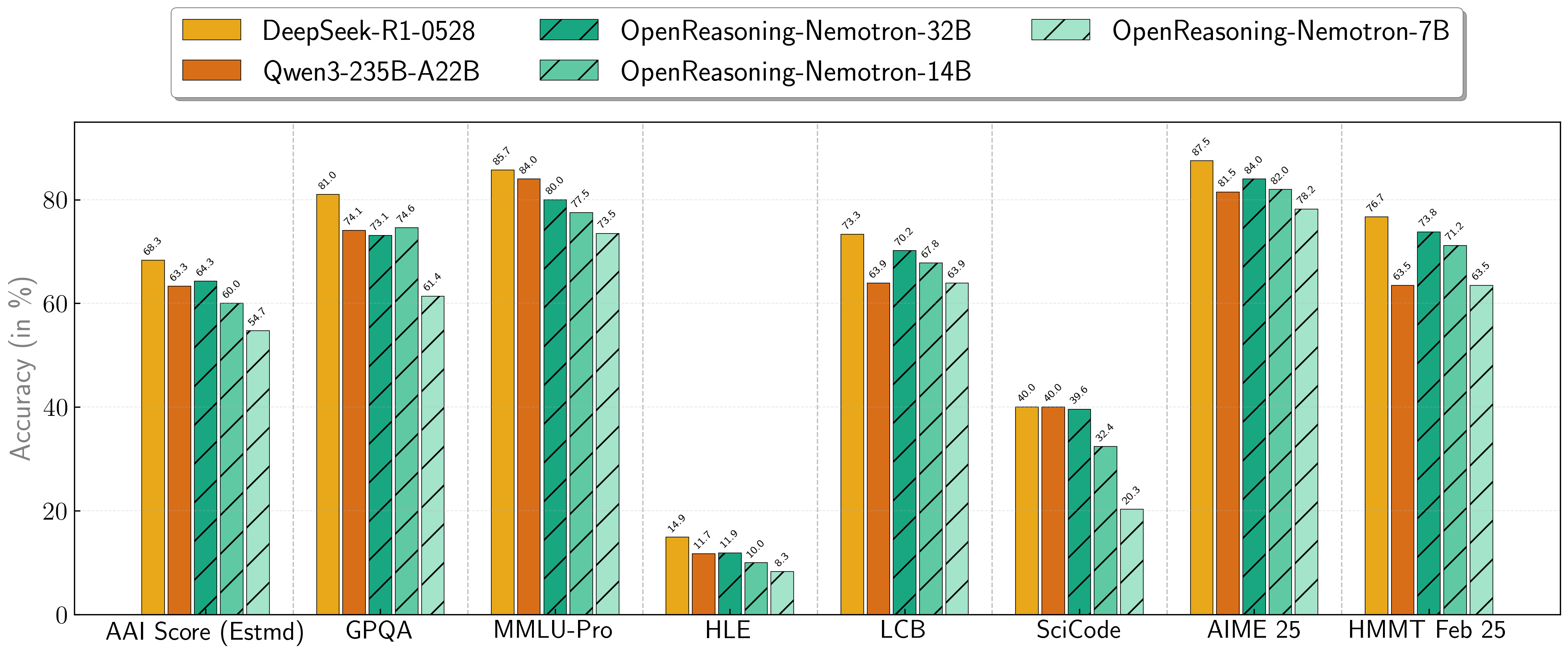
我们的模型在一系列具有挑战性的推理基准测试中表现出色。7B、14B 和 32B 模型在其规模类别中持续创造新的最优记录。
| 模型 | 人工分析指数* | GPQA | MMLU-PRO | HLE | 实时代码基准测试* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* 这是我们对人工分析智能指数的估计,并非官方分数。 * 实时代码基准测试版本 6,日期范围 2408 - 2505。
多智能体协作
OpenReasoning-Nemotron 模型可以通过启动多个并行生成并通过 生成式解决方案选择(GenSelect) 将它们组合在一起来以“重”模式使用。为了添加此“技能”,我们遵循原始的 GenSelect 训练流程,但不针对选择摘要进行训练,而是使用 DeepSeek R1 0528 671B 的完整推理轨迹。我们仅训练模型为数学问题选择最佳解决方案,但令人惊讶地发现,此能力可直接推广到代码和科学问题!在这种“重”GenSelect 推理模式下,OpenReasoning-Nemotron-32B 模型在数学和编码基准测试中超越了 O3(高)。
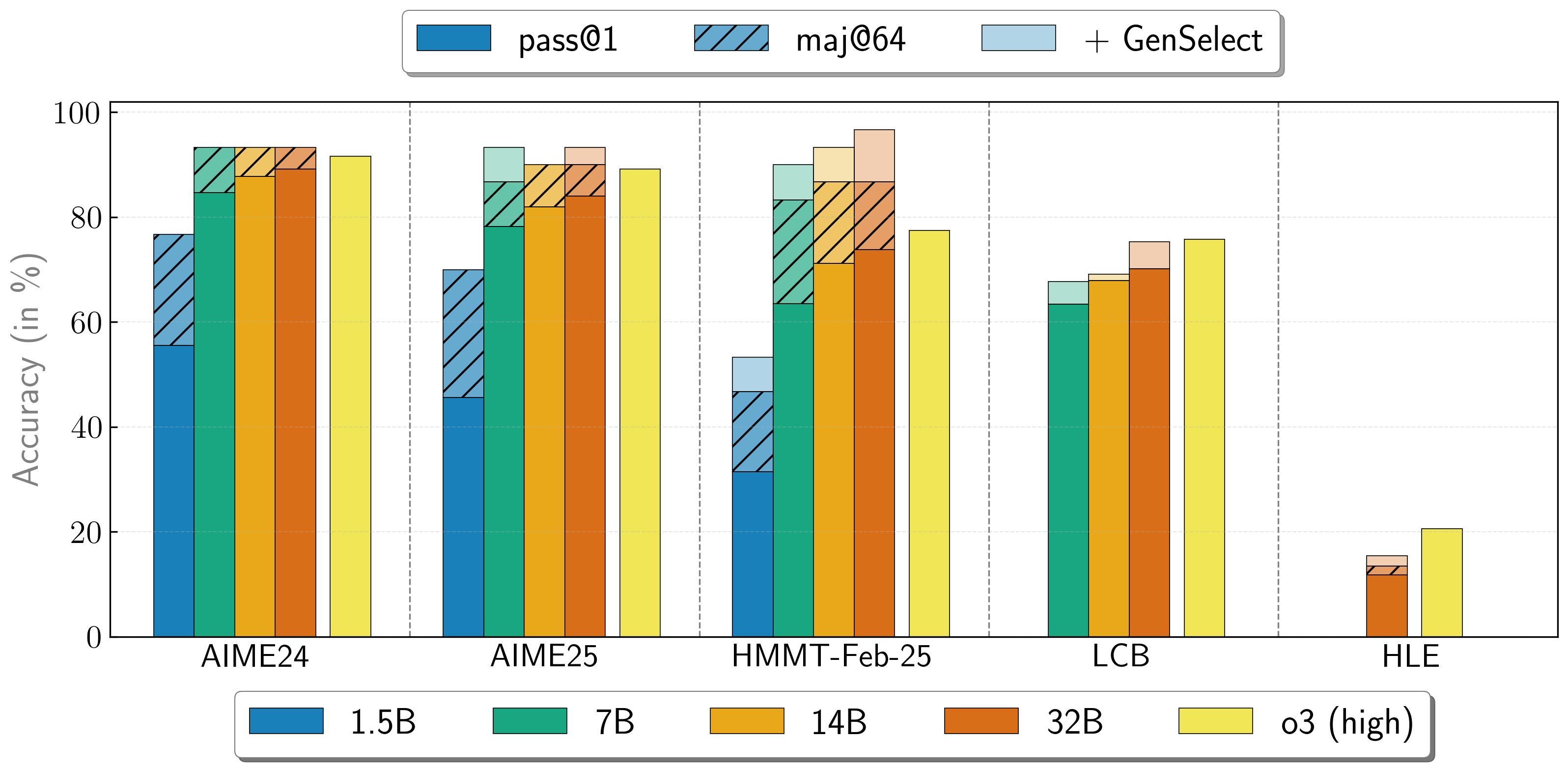
| 模型 | 单次尝试通过率(64 次平均) | 64 次多数投票 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408 - 2505 | 63.4 | 不适用 | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408 - 2505 | 67.9 | 不适用 | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408 - 2505 | 70.2 | 不适用 | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
📦 安装指南
文档未提供具体安装步骤,暂不展示。
💻 使用示例
基础用法
import transformers
import torch
model_id = "nvidia/OpenReasoning-Nemotron-1.5B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# 代码生成提示
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
Please use python programming language only.
You must use ```python for just the final solution code block with the following format:
```python
# Your code here
{user} """
数学生成提示
prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \boxed{}.
{user}
"""
科学生成提示
你可以参考以下提示 -
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (用于 GPQA)
https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
messages = [ { "role": "user", "content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers") }, ] outputs = pipeline( messages, max_new_tokens=64000, ) print(outputs[0]["generated_text"][-1]['content'])
若要了解如何在 GenSelect 模式下使用模型,请参阅我们的 [文档](https://nvidia.github.io/NeMo-Skills/releases/openreasoning/evaluation/)。
## 📚 详细文档
### 引用
如果你发现这些数据有用,请引用以下文献:
@article{ahmad2025opencodereasoning, title={OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}, author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg}, year={2025}, eprint={2504.01943}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2504.01943}, }
@misc{ahmad2025opencodereasoningiisimpletesttime, title={OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}, author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg}, year={2025}, eprint={2507.09075}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2507.09075}, }
@misc{moshkov2025aimo2winningsolutionbuilding, title={AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}, author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman}, year={2025}, eprint={2504.16891}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2504.16891}, }
### 附加信息
- **部署地域**:全球
- **用例**:此模型适用于从事竞赛数学、代码和科学问题研究的开发者和研究人员。它仅通过监督微调进行训练,以在基准测试中取得优异成绩。
- **发布日期**:2025 年 7 月 16 日通过 [Huggingface](https://huggingface.co/nvidia/OpenReasoning-Nemotron-1.5B/) 发布
### 参考资料
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
* [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
### 模型架构
- **架构类型**:密集型仅解码器 Transformer 模型
- **网络架构**:Qwen-1.5B-Instruct
此模型基于 Qwen2.5-1.5B-Instruct 开发,具有 1.5B 模型参数。
- OpenReasoning-Nemotron-1.5B 基于 Qwen2.5-1.5B-Instruct 开发,具有 1.5B 模型参数。
- OpenReasoning-Nemotron-7B 基于 Qwen2.5-7B-Instruct 开发,具有 7B 模型参数。
- OpenReasoning-Nemotron-14B 基于 Qwen2.5-14B-Instruct 开发,具有 14B 模型参数。
- OpenReasoning-Nemotron-32B 基于 Qwen2.5-32B-Instruct 开发,具有 32B 模型参数。
### 输入
- **输入类型**:文本
- **输入格式**:字符串
- **输入参数**:一维(1D)
- **其他与输入相关的属性**:经过高达 64,000 输出令牌的训练
### 输出
- **输出类型**:文本
- **输出格式**:字符串
- **输出参数**:一维(1D)
- **其他与输出相关的属性**:经过高达 64,000 输出令牌的训练
我们的 AI 模型设计和/或优化为在 NVIDIA GPU 加速系统上运行。通过利用 NVIDIA 的硬件(如 GPU 核心)和软件框架(如 CUDA 库),该模型与仅使用 CPU 的解决方案相比,可实现更快的训练和推理速度。
### 软件集成
- **运行时引擎**:NeMo 2.3.0
- **推荐的硬件微架构兼容性**:NVIDIA Ampere、NVIDIA Hopper
- **首选/支持的操作系统**:Linux
### 模型版本
- 1.0(2025 年 7 月 16 日)
- OpenReasoning-Nemotron-32B
- OpenReasoning-Nemotron-14B
- OpenReasoning-Nemotron-7B
- OpenReasoning-Nemotron-1.5B
### 训练和评估数据集
#### 训练数据集
OpenReasoning-Nemotron-1.5B 的训练语料库由以下数据集的问题组成:[OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning)、[OpenCodeReasoning-II](https://arxiv.org/abs/2507.09075)、[OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) 以及 [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset) 中的合成科学问题。所有响应均使用 DeepSeek-R1-0528 生成。我们还未修改地包含了 Llama-Nemotron-Post-Training-Dataset 中的指令跟随和工具调用数据。
- **数据收集方法**:混合:自动、人工、合成
- **标注方法**:混合:自动、人工、合成
- **属性**:来自 OpenCodeReasoning 问题(https://huggingface.co/datasets/nvidia/OpenCodeReasoning)、[OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) 和 [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset) 中合成科学问题的 500 万个 DeepSeek-R1-0528 生成响应。我们还未修改地包含了 Llama-Nemotron-Post-Training-Dataset 中的指令跟随和工具调用数据。
#### 评估数据集
我们使用以下基准测试对模型进行全面评估:
- **数学**:AIME 2024/2025、HMMT Feb 2025
- **代码**:LiveCodeBench、SciCode
- **科学**:GPQA、MMLU-PRO、HLE
- **数据收集方法**:混合:自动、人工、合成
- **标注方法**:混合:自动、人工、合成
### 推理
- **加速引擎**:vLLM、Tensor(RT)-LLM
- **测试硬件**:NVIDIA H100 - 80GB
### 伦理考量
NVIDIA 认为可信 AI 是一项共同责任,我们已制定政策和实践,以支持开发广泛的 AI 应用。当按照我们的服务条款下载或使用时,开发者应与其内部模型团队合作,确保该模型满足相关行业和用例的要求,并解决不可预见的产品滥用问题。
有关此模型伦理考量的更多详细信息,请参阅模型卡片++可解释性、偏差、安全性与隐私子卡片。
请 [在此](https://www.nvidia.com/en-us/support/submit-security-vulnerability/) 报告模型质量、风险、安全漏洞或 NVIDIA AI 相关问题。
## 📄 许可证
本项目采用 [知识共享署名 4.0 国际许可协议(CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/legalcode.en)。%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)