Llama3.1 Typhoon2 8b Instruct
L
Llama3.1 Typhoon2 8b Instruct
由 scb10x 开发
Llama3.1-Typhoon2-8B是一个基于Transformer架构的泰语大语言模型(指令型),能够处理多种语言任务,为用户提供高效准确的语言交互服务。

下载量 2,831
发布时间 : 12/15/2024
模型简介
该模型是一个80亿参数的指令型仅解码器模型,主要用于泰语和英语的语言交互任务,如问答、数学、编码、创意写作等。
模型特点
多语言支持
支持泰语和英语,能够处理多种语言任务。
长上下文处理
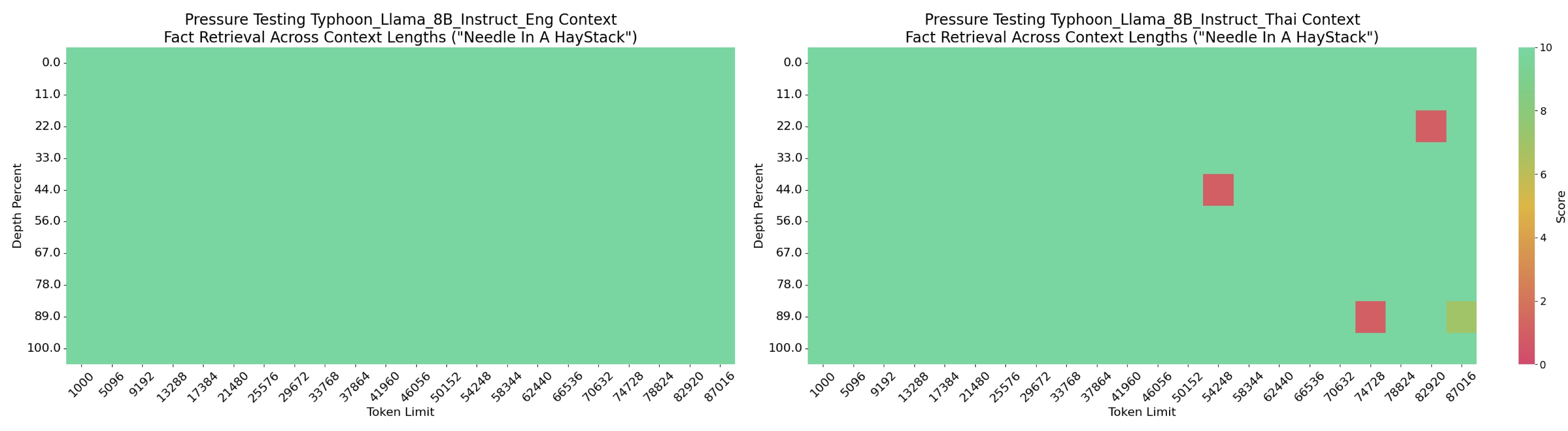
支持90k的上下文长度,能够处理较长的上下文输入。
高性能指令遵循
在指令遵循和函数调用任务上表现出色。
特定领域优化
在数学和编码等特定领域有良好的表现。
模型能力
文本生成
问答
数学计算
编码
创意写作
角色扮演
教学
函数调用
使用案例
教育
教学辅助
帮助学生解答问题或提供学习资源。
提高学习效率
商业
客户服务
用于自动化客户服务,回答客户问题。
提升客户满意度
开发
代码生成
帮助开发者生成代码片段或解决编程问题。
提高开发效率
🚀 Llama3.1-Typhoon2-8B
Llama3.1-Typhoon2-8B是一个泰语大语言模型(指令型),基于Transformer架构,能够处理多种语言任务,为用户提供高效准确的语言交互服务。
🚀 快速开始
本模型的使用需要transformers 4.45.0或更新的版本。以下是使用该模型的示例代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/llama3.1-typhoon2-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
✨ 主要特性
性能表现出色
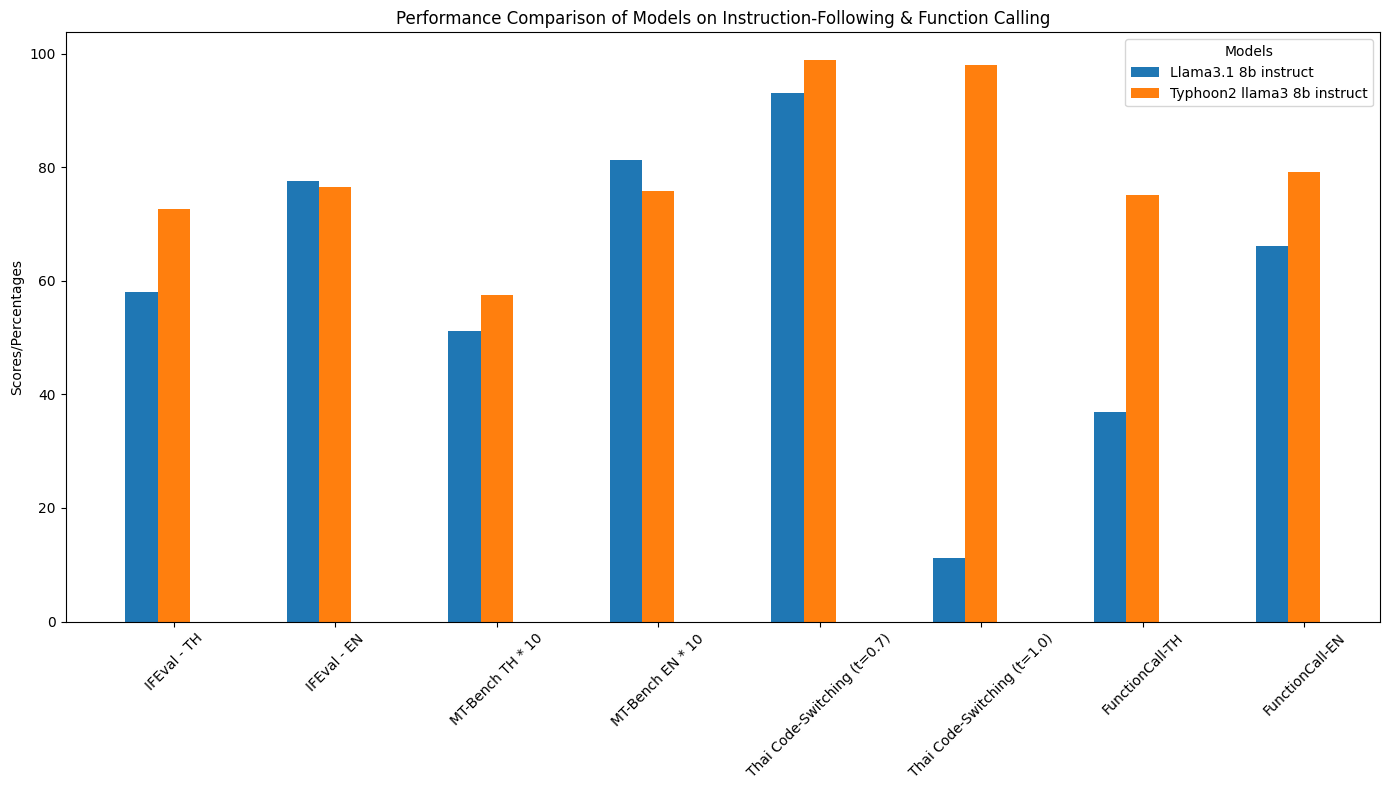
- 指令遵循和函数调用性能:通过可视化图表展示了在相关任务上的优秀表现。
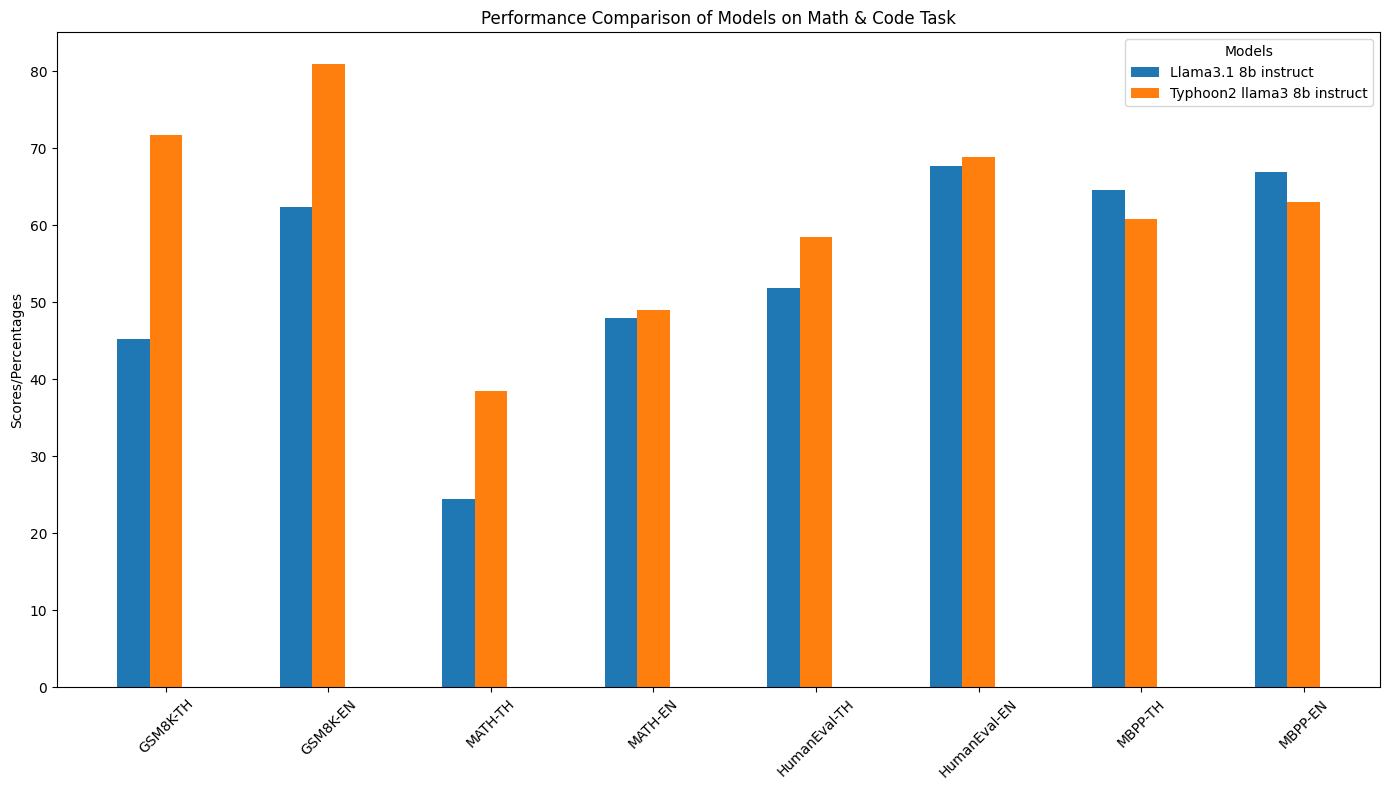
- 特定领域性能(数学和编码):在数学和编码等特定领域有良好的表现。
- 长上下文性能:能够处理较长的上下文输入。
- 详细性能指标:通过表格对比了不同模型在多个指标上的表现。 | 模型 | IFEval - TH | IFEval - EN | MT - Bench TH | MT - Bench EN | 泰语代码切换(t = 0.7) | 泰语代码切换(t = 1.0) | 函数调用 - TH | 函数调用 - EN | GSM8K - TH | GSM8K - EN | MATH - TH | MATH - EN | HumanEval - TH | HumanEval - EN | MBPP - TH | MBPP - EN | |-------------------------------|-------------|-------------|---------------|---------------|------------------------|------------------------|---------------|---------------|-------------|-------------|-------------|-------------|---------------|---------------|-------------|-------------| | Llama3.1 8B Instruct | 58.04% | 77.64% | 5.109 | 8.118 | 93% | 11.2% | 36.92% | 66.06% | 45.18% | 62.4% | 24.42% | 48% | 51.8% | 67.7% | 64.6% | 66.9% | | Typhoon2 Llama3 8B Instruct| 72.60% | 76.43% | 5.7417 | 7.584 | 98.8% | 98% | 75.12% | 79.08% | 71.72% | 81.0% | 38.48% | 49.04% | 58.5% | 68.9% | 60.8% | 63.0% |
模型特性丰富
- 模型类型:基于Llama架构的80亿参数指令型仅解码器模型。
- 环境要求:需要
transformers 4.45.0或更新版本。 - 上下文长度:支持90k的上下文长度。
- 主要语言:泰语和英语。
- 许可证:[Llama 3.1社区许可证](https://github.com/meta - llama/llama - models/blob/main/models/llama3_1/LICENSE)
📦 安装指南
如果你想使用推理服务器托管该模型,可以按照以下步骤进行安装:
pip install vllm
vllm serve scb10x/llama3.1-typhoon2-8b-instruct
# 更多信息请参考 https://docs.vllm.ai/
💻 使用示例
基础用法
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/llama3.1-typhoon2-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
高级用法(函数调用示例)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import ast
model_name = "scb10x/llama3.1-typhoon2-8b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch.bfloat16, device_map='auto'
)
get_weather_api = {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, New York",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return",
},
},
"required": ["location"],
},
}
search_api = {
"name": "search",
"description": "Search for information on the internet",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query, e.g. 'latest news on AI'",
}
},
"required": ["query"],
},
}
get_stock = {
"name": "get_stock_price",
"description": "Get the stock price",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "The stock symbol, e.g. AAPL, GOOG",
}
},
"required": ["symbol"],
},
}
# Tool input are same format with OpenAI tools
openai_format_tools = [get_weather_api, search_api, get_stock]
messages = [
{"role": "system", "content": "You are an expert in composing functions."},
{"role": "user", "content": "ขอราคาหุ้น Tasla (TLS) และ Amazon (AMZ) ?"},
]
inputs = tokenizer.apply_chat_template(
messages, tools=openai_format_tools, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
num_return_sequences=1,
eos_token_id=[tokenizer.eos_token_id, 128009],
)
response = outputs[0][inputs.shape[-1]:]
print("Here Output:", tokenizer.decode(response, skip_special_tokens=True))
# Decoding function utility
def resolve_ast_by_type(value):
if isinstance(value, ast.Constant):
if value.value is Ellipsis:
output = "..."
else:
output = value.value
elif isinstance(value, ast.UnaryOp):
output = -value.operand.value
elif isinstance(value, ast.List):
output = [resolve_ast_by_type(v) for v in value.elts]
elif isinstance(value, ast.Dict):
output = {
resolve_ast_by_type(k): resolve_ast_by_type(v)
for k, v in zip(value.keys, value.values)
}
elif isinstance(
value, ast.NameConstant
): # Added this condition to handle boolean values
output = value.value
elif isinstance(
value, ast.BinOp
): # Added this condition to handle function calls as arguments
output = eval(ast.unparse(value))
elif isinstance(value, ast.Name):
output = value.id
elif isinstance(value, ast.Call):
if len(value.keywords) == 0:
output = ast.unparse(value)
else:
output = resolve_ast_call(value)
elif isinstance(value, ast.Tuple):
output = tuple(resolve_ast_by_type(v) for v in value.elts)
elif isinstance(value, ast.Lambda):
output = eval(ast.unparse(value.body[0].value))
elif isinstance(value, ast.Ellipsis):
output = "..."
elif isinstance(value, ast.Subscript):
try:
output = ast.unparse(value.body[0].value)
except:
output = ast.unparse(value.value) + "[" + ast.unparse(value.slice) + "]"
else:
raise Exception(f"Unsupported AST type: {type(value)}")
return output
def resolve_ast_call(elem):
func_parts = []
func_part = elem.func
while isinstance(func_part, ast.Attribute):
func_parts.append(func_part.attr)
func_part = func_part.value
if isinstance(func_part, ast.Name):
func_parts.append(func_part.id)
func_name = ".".join(reversed(func_parts))
args_dict = {}
for arg in elem.keywords:
output = resolve_ast_by_type(arg.value)
args_dict[arg.arg] = output
return {func_name: args_dict}
def ast_parse(input_str, language="Python"):
if language == "Python":
cleaned_input = input_str.strip("[]'")
parsed = ast.parse(cleaned_input, mode="eval")
extracted = []
if isinstance(parsed.body, ast.Call):
extracted.append(resolve_ast_call(parsed.body))
else:
for elem in parsed.body.elts:
assert isinstance(elem, ast.Call)
extracted.append(resolve_ast_call(elem))
return extracted
else:
raise NotImplementedError(f"Unsupported language: {language}")
def parse_nested_value(value):
"""
Parse a potentially nested value from the AST output.
Args:
value: The value to parse, which could be a nested dictionary, which includes another function call, or a simple value.
Returns:
str: A string representation of the value, handling nested function calls and nested dictionary function arguments.
"""
if isinstance(value, dict):
# Check if the dictionary represents a function call (i.e., the value is another dictionary or complex structure)
if all(isinstance(v, dict) for v in value.values()):
func_name = list(value.keys())[0]
args = value[func_name]
args_str = ", ".join(
f"{k}={parse_nested_value(v)}" for k, v in args.items()
)
return f"{func_name}({args_str})"
else:
# If it's a simple dictionary, treat it as key-value pairs
return (
"{"
+ ", ".join(f"'{k}': {parse_nested_value(v)}" for k, v in value.items())
+ "}"
)
return repr(value)
def default_decode_ast_prompting(result, language="Python"):
result = result.strip("`\n ")
if not result.startswith("["):
result = "[" + result
if not result.endswith("]"):
result = result + "]"
decoded_output = ast_parse(result, language)
return decoded_output
fc_result = default_decode_ast_prompting(tokenizer.decode(response, skip_special_tokens=True))
print(fc_result) # [{'Function': {'arguments': '{"symbol": "TLS"}', 'name': 'get_stock_price'}}, {'Function': {'arguments': '{"symbol": "AMZ"}', 'name': 'get_stock_price'}}]
📚 详细文档
预期用途和限制
本模型是一个指令型模型,但仍在开发中。它包含了一定程度的防护机制,但在响应用户提示时,仍可能产生不准确、有偏见或其他令人反感的答案。我们建议开发者在其使用场景中评估这些风险。
关注我们
- Twitter:https://twitter.com/opentyphoon
支持社区
- Discord:https://discord.gg/us5gAYmrxw
引用方式
如果你发现Typhoon2对你的工作有帮助,请使用以下方式引用:
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
📄 许可证
本模型遵循[Llama 3.1社区许可证](https://github.com/meta - llama/llama - models/blob/main/models/llama3_1/LICENSE)。
Phi 2 GGUF
其他
Phi-2是微软开发的一个小型但强大的语言模型,具有27亿参数,专注于高效推理和高质量文本生成。
大型语言模型 支持多种语言
P
TheBloke
41.5M
205
Roberta Large
MIT
基于掩码语言建模目标预训练的大型英语语言模型,采用改进的BERT训练方法
大型语言模型 英语
R
FacebookAI
19.4M
212
Distilbert Base Uncased
Apache-2.0
DistilBERT是BERT基础模型的蒸馏版本,在保持相近性能的同时更轻量高效,适用于序列分类、标记分类等自然语言处理任务。
大型语言模型 英语
D
distilbert
11.1M
669
Llama 3.1 8B Instruct GGUF
Meta Llama 3.1 8B Instruct 是一个多语言大语言模型,针对多语言对话用例进行了优化,在常见的行业基准测试中表现优异。
大型语言模型 英语
L
modularai
9.7M
4
Xlm Roberta Base
MIT
XLM-RoBERTa是基于100种语言的2.5TB过滤CommonCrawl数据预训练的多语言模型,采用掩码语言建模目标进行训练。
大型语言模型 支持多种语言
X
FacebookAI
9.6M
664
Roberta Base
MIT
基于Transformer架构的英语预训练模型,通过掩码语言建模目标在海量文本上训练,支持文本特征提取和下游任务微调
大型语言模型 英语
R
FacebookAI
9.3M
488
Opt 125m
其他
OPT是由Meta AI发布的开放预训练Transformer语言模型套件,参数量从1.25亿到1750亿,旨在对标GPT-3系列性能,同时促进大规模语言模型的开放研究。
大型语言模型 英语
O
facebook
6.3M
198
1
基于transformers库的预训练模型,适用于多种NLP任务
大型语言模型 Transformers
Transformers
1
unslothai
6.2M
1
Llama 3.1 8B Instruct
Llama 3.1是Meta推出的多语言大语言模型系列,包含8B、70B和405B参数规模,支持8种语言和代码生成,优化了多语言对话场景。
大型语言模型 Transformers 支持多种语言
L
meta-llama
5.7M
3,898
T5 Base
Apache-2.0
T5基础版是由Google开发的文本到文本转换Transformer模型,参数规模2.2亿,支持多语言NLP任务。
大型语言模型 支持多种语言
T
google-t5
5.4M
702
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文