Pathumma Llm Text 1.0.0

模型简介
PathummaLLM-text-1.0.0-7B 是一个多语言大语言模型,支持泰语、中文和英语,适用于多种语言场景,特别优化了检索增强生成(RAG)、约束生成和推理任务。
模型特点
多语言支持
支持泰语、中文和英语,适用于多种语言场景。
强大性能
与Openthaigpt1.5-7b-instruct相比展现出有竞争力的性能。
应用优化
针对检索增强生成(RAG)、约束生成和推理任务进行了优化。
模型能力
多语言文本生成
检索增强生成(RAG)
约束生成
推理任务
使用案例
商业分析
盈亏平衡点计算
计算公司需要销售多少产品才能达到盈亏平衡点。
模型能够准确计算并解释盈亏平衡点。
多语言应用
多语言问答
支持泰语、中文和英语的问答系统。
模型能够流畅地在三种语言之间切换并回答问题。
🚀 PathummaLLM-text-1.0.0-7B:泰语、中文和英语大语言模型指令
PathummaLLM-text-1.0.0-7B 是一个拥有 70 亿参数的大语言模型,支持泰语 🇹🇭、中文 🇨🇳 和英语 🇬🇧。它基于 OpenThaiLLM-Prebuilt 进行指令微调。该模型与 Openthaigpt1.5-7b-instruct 相比展现出了有竞争力的性能,并且针对应用场景、检索增强生成(RAG)、约束生成和推理任务进行了优化。

🚀 快速开始
本部分将为你介绍如何快速使用 PathummaLLM-text-1.0.0-7B 模型。
环境要求
Qwen2.5 的代码已集成在最新的 Hugging face transformers 库中,建议你使用最新版本的 transformers。
若使用 transformers<4.37.0,你将遇到以下错误:
KeyError: 'qwen2'
代码示例
以下是使用 apply_chat_template 加载分词器和模型并生成内容的代码片段:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # 加载模型的设备
model = AutoModelForCausalLM.from_pretrained(
"nectec/Pathumma-llm-text-1.0.0",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
prompt = "บริษัท A มีต้นทุนคงที่ 100,000 บาท และต้นทุนผันแปรต่อหน่วย 50 บาท ขายสินค้าได้ในราคา 150 บาทต่อหน่วย ต้องขายสินค้าอย่างน้อยกี่หน่วยเพื่อให้ถึงจุดคุ้มทุน?"
messages = [
{"role": "system", "content": "You are Pathumma LLM, created by NECTEC. Your are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=4096,
repetition_penalty=1.1,
temperature = 0.4
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
GGUF 实现示例
%pip install --quiet https://github.com/abetlen/llama-cpp-python/releases/download/v0.2.90-cu124/llama_cpp_python-0.2.90-cp310-cp310-linux_x86_64.whl
import transformers
import torch
from llama_cpp import Llama
import os
import requests
local_dir = "your local dir"
directory_path = r'{local_dir}/Pathumma-llm-text-1.0.0'
if not os.path.exists(directory_path):
os.mkdir(directory_path)
if not os.path.exists(f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf'):
!wget -O f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf' "https://huggingface.co/nectec/Pathumma-llm-text-1.0.0/resolve/main/Pathumma-llm-it-7b-Q4_K_M.gguf?download=true"
# Initialize the Llama model
llm = Llama(model_path=f'{local_dir}/Pathumma-llm-text-1.0.0/Pathumma-llm-it-7b-Q4_K_M.gguf', n_gpu_layers=-1, n_ctx=8192,verbose=False)
tokenizer = transformers.AutoTokenizer.from_pretrained("nectec/Pathumma-llm-text-1.0.0")
memory = [{'content': 'You are Pathumma LLM, created by NECTEC (National Electronics and Computer Technology Center). Your are a helpful assistant.', 'role': 'system'},]
def generate(instuction,memory=memory):
memory.append({'content': instuction, 'role': 'user'})
p = tokenizer.apply_chat_template(
memory,
tokenize=False,
add_generation_prompt=True
)
response = llm(
p,
max_tokens=2048,
temperature=0.2,
top_p=0.95,
repeat_penalty=1.1,
top_k=40,
min_p=0.05,
stop=["<|im_end|>"]
)
output = response['choices'][0]['text']
memory.append({'content': output, 'role': 'assistant'})
return output
print(generate("คุณคือใคร"))
✨ 主要特性
- 多语言支持:支持泰语、中文和英语,适用于多种语言场景。
- 强大性能:与 Openthaigpt1.5-7b-instruct 相比,展现出有竞争力的性能。
- 应用优化:针对检索增强生成(RAG)、约束生成和推理任务进行了优化。
📚 详细文档
模型详情
有关发布说明,请查看我们的 博客。 关于文本大语言模型部分的详细信息,请查看 此博客。
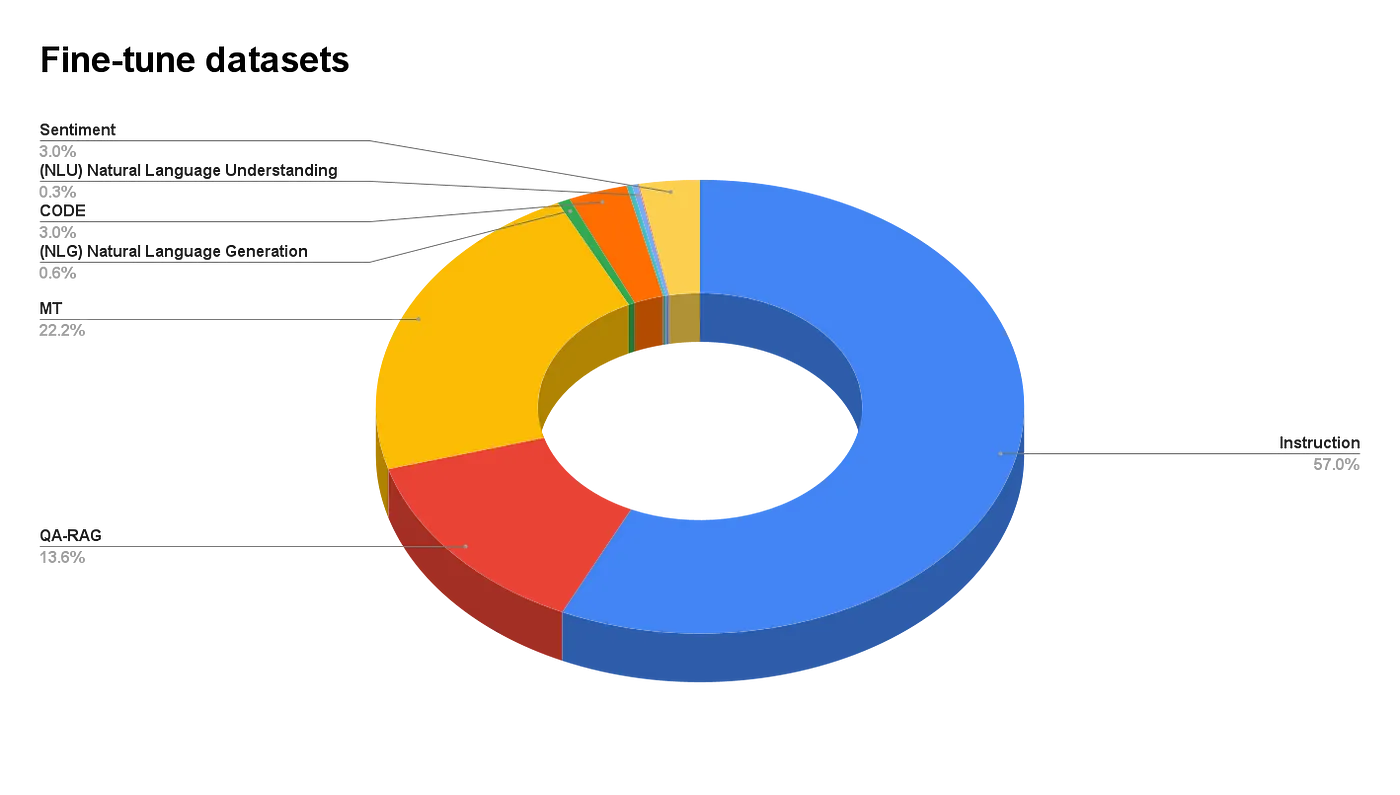
数据集比例
评估性能
| 模型 | m3exam | thaiexam | xcopa | belebele | xnli | thaisentiment | XL sum | flores200 英语 > 泰语 | flores200 泰语 > 英语 | iapp | AVG(NLU) | AVG(MC) | AVG(NLG) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pathumma-llm-text-1.0.0 | 55.02 | 51.32 | 83 | 77.77 | 40.11 | 41.29 | 16.9286253 | 26.54 | 51.88 | 41.28 | 60.54 | 53.17 | 34.16 |
| Openthaigpt1.5-7b-instruct | 54.01 | 52.04 | 85.4 | 79.44 | 39.7 | 50.24 | 18.11 | 29.09 | 29.58 | 32.49 | 63.70 | 53.03 | 27.32 |
| SeaLLMs-v3-7B-Chat | 51.43 | 51.33 | 83.4 | 78.22 | 34.05 | 39.57 | 20.27 | 32.91 | 28.8 | 48.12 | 58.81 | 51.38 | 32.53 |
| llama-3-typhoon-v1.5-8B | 43.82 | 41.95 | 81.6 | 71.89 | 33.35 | 38.45 | 16.66 | 31.94 | 28.86 | 54.78 | 56.32 | 42.89 | 33.06 |
| Meta-Llama-3.1-8B-Instruct | 45.11 | 43.89 | 73.4 | 74.89 | 33.49 | 45.45 | 21.61 | 30.45 | 32.28 | 68.57 | 56.81 | 44.50 | 38.23 |
🔧 技术细节
基础模型
- 基础模型:nectec/OpenThaiLLM-Prebuilt-7B
- 基础模型关系:微调
指标
- 准确率
任务类型
- 文本生成
标签
- 化学
- 生物学
- 金融
- 法律
- 代码
- 医学
- 文本生成推理
📄 许可证
本项目采用 Apache-2.0 许可证。
👥 贡献者
LLM 团队
- Pakawat Phasook (pakawat.phas@kmutt.ac.th)
- Jessada Pranee (jessada.pran@kmutt.ac.th)
- Arnon Saeoung (anon.saeoueng@gmail.com)
- Kun Kerdthaisong (kun.ker@dome.tu.ac.th)
- Kittisak Sukhantharat (kittisak.suk@stu.nida.ac.th)
- Piyawat Chuangkrud (piyawat@it.kmitl.ac.th)
- Chaianun Damrongrat (chaianun.damrongrat@nectec.or.th)
- Sarawoot Kongyoung (sarawoot.kongyoung@nectec.or.th)
音频团队
- Pattara Tipaksorn (pattara.tip@ncr.nstda.or.th)
- Wayupuk Sommuang (wayupuk.som@dome.tu.ac.th)
- Oatsada Chatthong (atsada.cha@dome.tu.ac.th)
- Kwanchiva Thangthai (kwanchiva.thangthai@nectec.or.th)
视觉团队
- Thirawarit Pitiphiphat (60010474@kmitl.ac.th)
- Peerapas Ngokpon (jamesselmon78169@gmail.com)
- Theerasit Issaranon (theerasit.issaranon@nectec.or.th)
📖 引用
如果你觉得我们的工作有帮助,请引用以下内容:
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
💬 支持社区
你可以加入我们的 Discord 社区 与我们交流。
Phi 2 GGUF
其他
Phi-2是微软开发的一个小型但强大的语言模型,具有27亿参数,专注于高效推理和高质量文本生成。
大型语言模型 支持多种语言
P
TheBloke
41.5M
205
Roberta Large
MIT
基于掩码语言建模目标预训练的大型英语语言模型,采用改进的BERT训练方法
大型语言模型 英语
R
FacebookAI
19.4M
212
Distilbert Base Uncased
Apache-2.0
DistilBERT是BERT基础模型的蒸馏版本,在保持相近性能的同时更轻量高效,适用于序列分类、标记分类等自然语言处理任务。
大型语言模型 英语
D
distilbert
11.1M
669
Llama 3.1 8B Instruct GGUF
Meta Llama 3.1 8B Instruct 是一个多语言大语言模型,针对多语言对话用例进行了优化,在常见的行业基准测试中表现优异。
大型语言模型 英语
L
modularai
9.7M
4
Xlm Roberta Base
MIT
XLM-RoBERTa是基于100种语言的2.5TB过滤CommonCrawl数据预训练的多语言模型,采用掩码语言建模目标进行训练。
大型语言模型 支持多种语言
X
FacebookAI
9.6M
664
Roberta Base
MIT
基于Transformer架构的英语预训练模型,通过掩码语言建模目标在海量文本上训练,支持文本特征提取和下游任务微调
大型语言模型 英语
R
FacebookAI
9.3M
488
Opt 125m
其他
OPT是由Meta AI发布的开放预训练Transformer语言模型套件,参数量从1.25亿到1750亿,旨在对标GPT-3系列性能,同时促进大规模语言模型的开放研究。
大型语言模型 英语
O
facebook
6.3M
198
1
基于transformers库的预训练模型,适用于多种NLP任务
大型语言模型 Transformers
Transformers
1
unslothai
6.2M
1
Llama 3.1 8B Instruct
Llama 3.1是Meta推出的多语言大语言模型系列,包含8B、70B和405B参数规模,支持8种语言和代码生成,优化了多语言对话场景。
大型语言模型 Transformers 支持多种语言
L
meta-llama
5.7M
3,898
T5 Base
Apache-2.0
T5基础版是由Google开发的文本到文本转换Transformer模型,参数规模2.2亿,支持多语言NLP任务。
大型语言模型 支持多种语言
T
google-t5
5.4M
702
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文