Typhoon2.1 Gemma3 4b
泰语大语言模型(指令调优版),拥有40亿参数、128K上下文长度且具备函数调用能力

下载量 2,083
发布时间 : 5/1/2025
模型简介
基于Gemma3 4B架构开发的泰语指令大语言模型,支持泰语与英语,具备文本生成和函数调用能力
模型特点
泰语优化
专为泰语优化的40亿参数大语言模型,支持泰语与英语混合输入输出
长上下文支持
支持128K tokens的上下文长度,适合处理长文档和复杂对话
函数调用能力
内置工具调用功能,可执行外部API调用和数据处理
双模式推理
支持快速响应和深度思考两种推理模式,适应不同场景需求
模型能力
泰语文本生成
英语文本生成
函数调用
长文本处理
多轮对话
代码生成
数学计算
创意写作
使用案例
客户服务
泰语客服机器人
部署为在线客服系统,处理泰国用户的咨询请求
可提供24/7泰语自然语言交互服务
内容创作
泰语文章生成
根据关键词自动生成泰语营销文案或新闻稿
快速产出符合泰国语言习惯的优质内容
教育
语言学习助手
作为泰语-英语双语学习辅助工具
提供语法解释、例句生成和对话练习功能
🚀 Typhoon2.1-Gemma3-4B
Typhoon2.1-Gemma3-4B 是一个具备 40 亿参数、128K 上下文长度和函数调用能力的泰语指令大语言模型。它基于 Gemma3 4B 构建。
注意:这是一个仅处理文本的模型。由于复杂性原因,此版本移除了视觉编码器。请持续关注后续带有视觉编码器的版本。
🚀 快速开始
本模型可用于泰语或英语的文本生成任务。以下是使用 transformers 库调用该模型的示例代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "scb10x/typhoon2.1-gemma3-4b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a male AI assistant named Typhoon created by SCB 10X to be helpful, harmless, and honest. Typhoon is happy to help with analysis, question answering, math, coding, creative writing, teaching, role-play, general discussion, and all sorts of other tasks. Typhoon responds directly to all human messages without unnecessary affirmations or filler phrases like “Certainly!”, “Of course!”, “Absolutely!”, “Great!”, “Sure!”, etc. Specifically, Typhoon avoids starting responses with the word “Certainly” in any way. Typhoon follows this information in all languages, and always responds to the user in the language they use or request. Typhoon is now being connected with a human. Write in fluid, conversational prose, Show genuine interest in understanding requests, Express appropriate emotions and empathy. Also showing information in term that is easy to understand and visualized."},
{"role": "user", "content": "ขอสูตรไก่ย่าง"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=False # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
✨ 主要特性
- 具备 40 亿参数,拥有 128K 上下文长度和函数调用能力。
- 支持泰语和英语两种语言。
- 提供思考和非思考两种模式,可根据需求灵活切换。
- 支持使用工具,可通过 vLLM 部署为兼容 OpenAI 的 API 服务器。
📦 安装指南
部署为服务器
可以使用 vllm 将 Typhoon2.1 作为兼容 OpenAI 的 API 服务器运行:
pip install vllm
vllm serve scb10x/typhoon2.1-gemma3-4b --max-model-len 16000 --dtype bfloat16 --tool-call-parser pythonic --enable-auto-tool-choice
# adjust --max-model-len based on your avaliable memory
# you can use --quantization bitsandbytes to reduce the memory use while trade-off inference speed
💻 使用示例
基础用法
上述快速开始部分的代码展示了如何使用 transformers 库调用 Typhoon2.1-Gemma3-4B 模型进行泰语或英语文本生成。
高级用法
使用工具
可以为基于 vLLM 的兼容 OpenAI 的 API 提供工具以实现更多功能:
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
def get_weather(location: str, unit: str):
return f"Getting the weather for {location} in {unit}..."
tool_functions = {"get_weather": get_weather}
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City and state, e.g., 'San Francisco, CA'"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location", "unit"]
}
}
}]
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[{"role": "user", "content": "What's the weather like in San Francisco?"}],
tools=tools,
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_calls[0].function
print(f"Function called: {tool_call.name}")
print(f"Arguments: {tool_call.arguments}")
print(f"Result: {get_weather(**json.loads(tool_call.arguments))}")
切换思考和非思考模式
Typhoon 支持两种模式:
- 非思考模式(默认):快速生成响应,无需额外推理步骤。
- 思考模式:模型先进行内部推理,然后提供更清晰、可能更准确的最终答案。
可以通过以下方式启用思考模式:
- 在
apply_chat_template中设置enable_thinking=True:
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True # Switches between thinking and non-thinking modes. Default is False.
).to(model.device)
- 手动提供思考模式的系统提示:
You are a helpful assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state a response that addresses the user's request and aligns with their preferences, not just providing a direct answer.
- 在基于 vllm 的兼容 OpenAI 的客户端中,可以在 POST 有效负载中添加
chat_template_kwargs:
{
"model": "scb10x/typhoon2.1-gemma3-4b",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"chat_template_kwargs": {"enable_thinking": true}
}
预算强制
预算强制是一种高级技术,可让模型在生成最终答案之前花费更多时间和令牌进行推理,有助于提高复杂问题的性能:
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
class BudgetForcingHandler:
def __init__(self, model_name: str, max_think_token: int, max_ignore=5, temperature=0.6, seed=32):
self.temperature = temperature
self.seed = seed
self.max_think_token = max_think_token
self.max_ignore = max_ignore
self.model = LLM(model_name, dtype='bfloat16', enforce_eager=True)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.alternative_str = '\nAlternatively'
self.system = """You are a reasoning assistant. First, think through the reasoning internally, then present the reasoning within <think>...</think>. After thinking, clearly state the final answer."""
def __call__(self, prompts: List[str]):
count_prompt = len(prompts)
prompts = [self.tokenizer.apply_chat_template([{'role': 'system', 'content': self.system}, {'role': 'user', 'content': f'Please solve this math question, and put your final answer within \\boxed{{}}.\n{p}'}], add_generation_prompt=True, tokenize=False) for p in prompts]
sampling_params = SamplingParams(
max_tokens=self.max_think_token,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params
)
outputs = [output.outputs[0].text for output in o]
token_count = [len(output.outputs[0].token_ids) for output in o]
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
for _ in range(self.max_ignore): # Num of times to skip stop token
inference_loop_prompts = []
inference_idx = []
max_inference_token = 0
print('current token count: ', token_count)
for i in range(len(prompts)):
left_budget = self.max_think_token - token_count[i]
if left_budget > 0:
prompts[i] = prompts[i] + self.alternative_str
inference_loop_prompts.append(prompts[i])
inference_idx.append(i)
if left_budget > max_inference_token:
max_inference_token = left_budget
outputs = ['' for _ in range(len(prompts))]
if max_inference_token == 0 or len(inference_loop_prompts) == 0:
break
sampling_params = SamplingParams(
max_tokens=max_inference_token,
min_tokens=1,
seed=self.seed,
stop=["</think>"],
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
inference_loop_prompts,
sampling_params=sampling_params
)
assert len(inference_idx) == len(inference_loop_prompts)
assert len(inference_idx) == len(o)
for i, output in zip(inference_idx, o):
outputs[i] = output.outputs[0].text
for i, idx in enumerate(inference_idx):
token_count[idx] = token_count[idx] + len(o[i].outputs[0].token_ids)
for i in range(len(prompts)):
prompts[i] = prompts[i] + outputs[i]
print('generating answer...')
prompts = [p + '\nTime\'s up. End of thinking process. Will answer immediately.\n</think>' for i, p in enumerate(prompts)]
sampling_params = SamplingParams(
max_tokens=2048,
min_tokens=0,
seed=self.seed,
skip_special_tokens=False,
temperature=self.temperature,
)
o = self.model.generate(
prompts,
sampling_params=sampling_params,
)
for i in range(len(prompts)):
prompts[i] = prompts[i] + o[i].outputs[0].text
assert len(prompts) == count_prompt
return prompts
handler = BudgetForcingHandler("scb10x/typhoon2.1-gemma3-4b", max_think_token=2048)
handler(["How many r in raspberry?"])
📚 详细文档
模型描述
| 属性 | 详情 |
|---|---|
| 模型类型 | 基于 Gemma3 架构的 4B 指令仅解码器模型 |
| 要求 | transformers 4.50.0 或更高版本 |
| 主要语言 | 泰语和英语 |
| 许可证 | Gemma License |
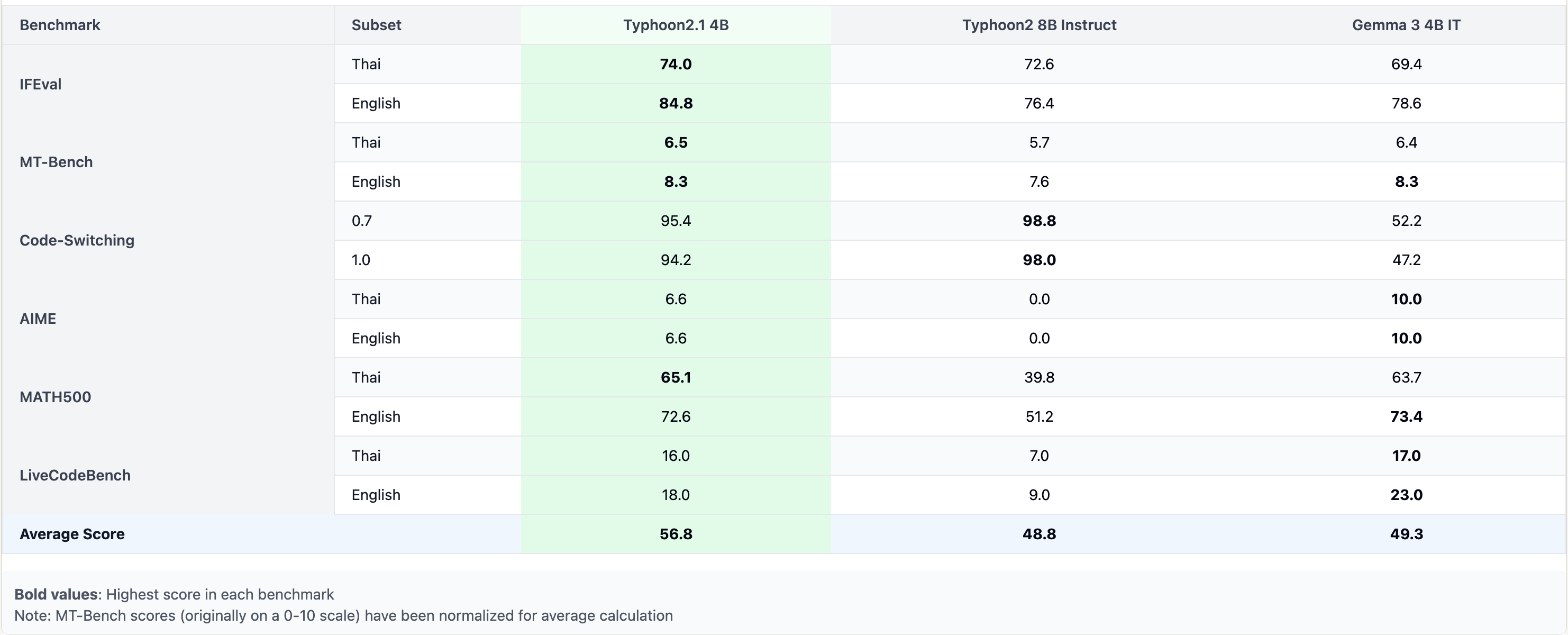
性能
预期用途与限制
本模型是一个指令模型,但仍在开发中。它包含了一定程度的防护机制,但在响应用户提示时仍可能产生不准确、有偏差或其他令人反感的答案。建议开发者在其使用场景中评估这些风险。
📄 许可证
本模型使用 Gemma License。
🔗 其他链接
关注我们
https://twitter.com/opentyphoon
支持
引用
如果您发现 Typhoon2 对您的工作有用,请使用以下方式引用:
@misc{typhoon2,
title={Typhoon 2: A Family of Open Text and Multimodal Thai Large Language Models},
author={Kunat Pipatanakul and Potsawee Manakul and Natapong Nitarach and Warit Sirichotedumrong and Surapon Nonesung and Teetouch Jaknamon and Parinthapat Pengpun and Pittawat Taveekitworachai and Adisai Na-Thalang and Sittipong Sripaisarnmongkol and Krisanapong Jirayoot and Kasima Tharnpipitchai},
year={2024},
eprint={2412.13702},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13702},
}
Phi 2 GGUF
其他
Phi-2是微软开发的一个小型但强大的语言模型,具有27亿参数,专注于高效推理和高质量文本生成。
大型语言模型 支持多种语言
P
TheBloke
41.5M
205
Roberta Large
MIT
基于掩码语言建模目标预训练的大型英语语言模型,采用改进的BERT训练方法
大型语言模型 英语
R
FacebookAI
19.4M
212
Distilbert Base Uncased
Apache-2.0
DistilBERT是BERT基础模型的蒸馏版本,在保持相近性能的同时更轻量高效,适用于序列分类、标记分类等自然语言处理任务。
大型语言模型 英语
D
distilbert
11.1M
669
Llama 3.1 8B Instruct GGUF
Meta Llama 3.1 8B Instruct 是一个多语言大语言模型,针对多语言对话用例进行了优化,在常见的行业基准测试中表现优异。
大型语言模型 英语
L
modularai
9.7M
4
Xlm Roberta Base
MIT
XLM-RoBERTa是基于100种语言的2.5TB过滤CommonCrawl数据预训练的多语言模型,采用掩码语言建模目标进行训练。
大型语言模型 支持多种语言
X
FacebookAI
9.6M
664
Roberta Base
MIT
基于Transformer架构的英语预训练模型,通过掩码语言建模目标在海量文本上训练,支持文本特征提取和下游任务微调
大型语言模型 英语
R
FacebookAI
9.3M
488
Opt 125m
其他
OPT是由Meta AI发布的开放预训练Transformer语言模型套件,参数量从1.25亿到1750亿,旨在对标GPT-3系列性能,同时促进大规模语言模型的开放研究。
大型语言模型 英语
O
facebook
6.3M
198
1
基于transformers库的预训练模型,适用于多种NLP任务
大型语言模型 Transformers
Transformers
1
unslothai
6.2M
1
Llama 3.1 8B Instruct
Llama 3.1是Meta推出的多语言大语言模型系列,包含8B、70B和405B参数规模,支持8种语言和代码生成,优化了多语言对话场景。
大型语言模型 Transformers 支持多种语言
L
meta-llama
5.7M
3,898
T5 Base
Apache-2.0
T5基础版是由Google开发的文本到文本转换Transformer模型,参数规模2.2亿,支持多语言NLP任务。
大型语言模型 支持多种语言
T
google-t5
5.4M
702
精选推荐AI模型
Llama 3 Typhoon V1.5x 8b Instruct
专为泰语设计的80亿参数指令模型,性能媲美GPT-3.5-turbo,优化了应用场景、检索增强生成、受限生成和推理任务
大型语言模型 Transformers 支持多种语言
L
scb10x
3,269
16
Cadet Tiny
Openrail
Cadet-Tiny是一个基于SODA数据集训练的超小型对话模型,专为边缘设备推理设计,体积仅为Cosmo-3B模型的2%左右。
对话系统 Transformers 英语
C
ToddGoldfarb
2,691
6
Roberta Base Chinese Extractive Qa
基于RoBERTa架构的中文抽取式问答模型,适用于从给定文本中提取答案的任务。
问答系统 中文
R
uer
2,694
98
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
智启未来,您的人工智能解决方案智库
简体中文