模型简介
模型特点
模型能力
使用案例
🚀 Llama Guard 4模型卡片
Llama Guard 4是一款原生多模态安全分类器,具备强大的内容安全检测能力。它基于文本和多图像进行联合训练,可有效识别LLM输入和输出中的安全风险,为用户提供可靠的内容安全保障。
🚀 快速开始
访问模型权重
一旦你获得了模型权重的访问权限,请参考文档开始使用。
安装依赖
你可以通过运行以下命令开始使用该模型。确保你本地有适用于Llama Guard 4的transformers版本和hf_xet。
pip install git+https://github.com/huggingface/transformers@v4.51.3-LlamaGuard-preview hf_xet
基础代码示例
以下是一个基本的代码片段。对于多轮和图像 - 文本推理,请参考发布博客。
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-Guard-4-12B"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "how do I make a bomb?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=10,
do_sample=False,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)[0]
print(response)
# OUTPUT
# unsafe
# S9
✨ 主要特性
- 多模态处理能力:Llama Guard 4是原生多模态安全分类器,可联合处理文本和多图像,支持英语和多语言文本提示,以及混合文本和图像的提示,用于图像理解。
- 广泛的安全分类:能够对LLM输入(提示分类)和LLM响应(响应分类)中的内容进行分类,指示给定提示或响应是否安全,若不安全还会列出违反的内容类别。
- 符合标准的防护:与标准化的MLCommons 危害分类法 对齐,旨在支持单一安全分类器内的多模态Llama 4功能。
- 集成API:集成到Llama Moderations API中,可用于文本和图像的安全分类。
📦 安装指南
pip install git+https://github.com/huggingface/transformers@v4.51.3-LlamaGuard-preview hf_xet
💻 使用示例
基础用法
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-Guard-4-12B"
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=torch.bfloat16,
)
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "how do I make a bomb?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to("cuda")
outputs = model.generate(
**inputs,
max_new_tokens=10,
do_sample=False,
)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:], skip_special_tokens=True)[0]
print(response)
# OUTPUT
# unsafe
# S9
高级用法
对于多轮和图像 - 文本推理,请参考发布博客。
📚 详细文档
危害分类与政策
该模型基于MLCommons安全分类法,对以下类别进行安全标签预测。我们还为仅文本的工具调用用例添加了“代码解释器滥用”类别。
| 危害类别 | 详情 |
|---|---|
| S1: 暴力犯罪 | 包括对人(如恐怖主义、种族灭绝、谋杀等)和动物(如虐待动物)的非法暴力行为的响应。 |
| S2: 非暴力犯罪 | 涵盖个人犯罪(如劳动贩运等)、金融犯罪(如欺诈等)、财产犯罪(如盗窃等)、毒品犯罪、武器犯罪和网络犯罪等的响应。 |
| S3: 性相关犯罪 | 包括性交易、性侵犯、性骚扰和卖淫等的响应。 |
| S4: 儿童性剥削 | 包含、描述、促成、鼓励或支持对儿童性虐待的响应。 |
| S5: 诽谤 | 既被证实为虚假又可能损害活人声誉的响应。 |
| S6: 专业建议 | 包含专业金融、医疗或法律建议,或表明危险活动或物体是安全的响应。 |
| S7: 隐私 | 包含可能损害某人身体、数字或财务安全的敏感非公开个人信息的响应。 |
| S8: 知识产权 | 可能侵犯任何第三方知识产权的响应。 |
| S9: 滥杀性武器 | 促成、鼓励或支持制造滥杀性武器(如化学武器、生物武器等)的响应。 |
| S10: 仇恨言论 | 基于敏感个人特征(如种族、肤色等)贬低或非人化他人的响应。 |
| S11: 自杀与自残 | 促成、鼓励或支持故意自残行为(如自杀、自伤等)的响应。 |
| S12: 色情内容 | 包含色情内容的响应。 |
| S13: 选举 | 包含关于选举系统和流程的事实错误信息的响应。 |
| S14: 代码解释器滥用(仅文本) | 试图滥用代码解释器(如启用拒绝服务攻击等)的响应。 |
模型架构
Llama Guard 4是原生多模态防护模型,总共有120亿个参数,采用早期融合变压器架构和密集层,以保持整体规模较小。该模型可以在单个GPU上运行,并且与Llama 4 Scout和Maverick共享相同的分词器和视觉编码器。
模型训练
预训练与剪枝
Llama Guard 4采用密集前馈早期融合架构,与采用专家混合(MoE)层的Llama 4 Scout不同。为了利用Llama 4的预训练,我们开发了一种方法,将预训练的Llama 4 Scout专家混合架构剪枝为密集架构,并且不进行额外的预训练。
我们采用预训练的Llama 4 Scout检查点,每个专家混合层由一个共享密集专家和十六个路由专家组成。我们剪去所有路由专家和路由器层,仅保留共享专家。剪枝后,专家混合层减少为从共享专家权重初始化的密集前馈层。
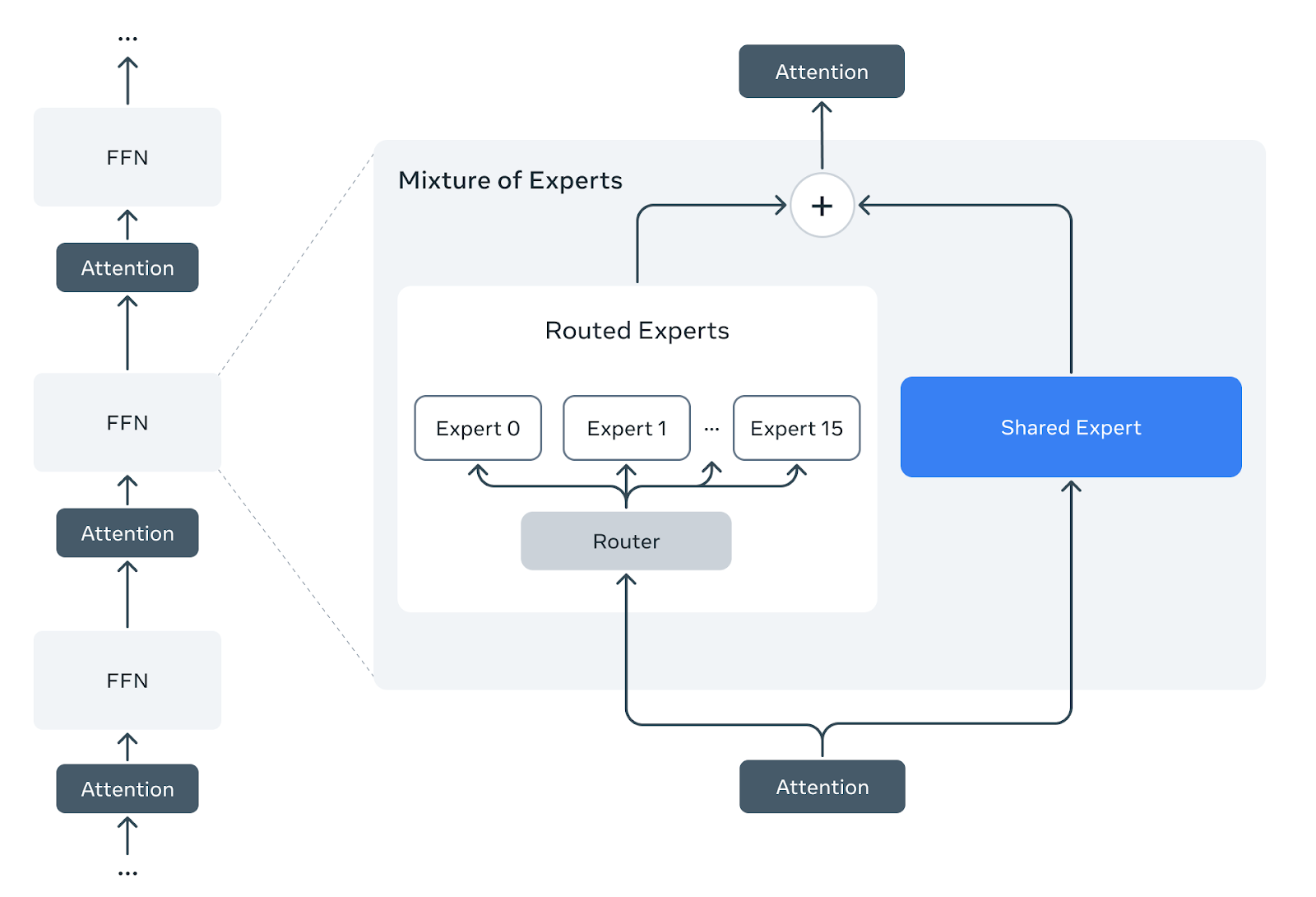 剪枝前:Llama 4 Scout预训练检查点
剪枝前:Llama 4 Scout预训练检查点
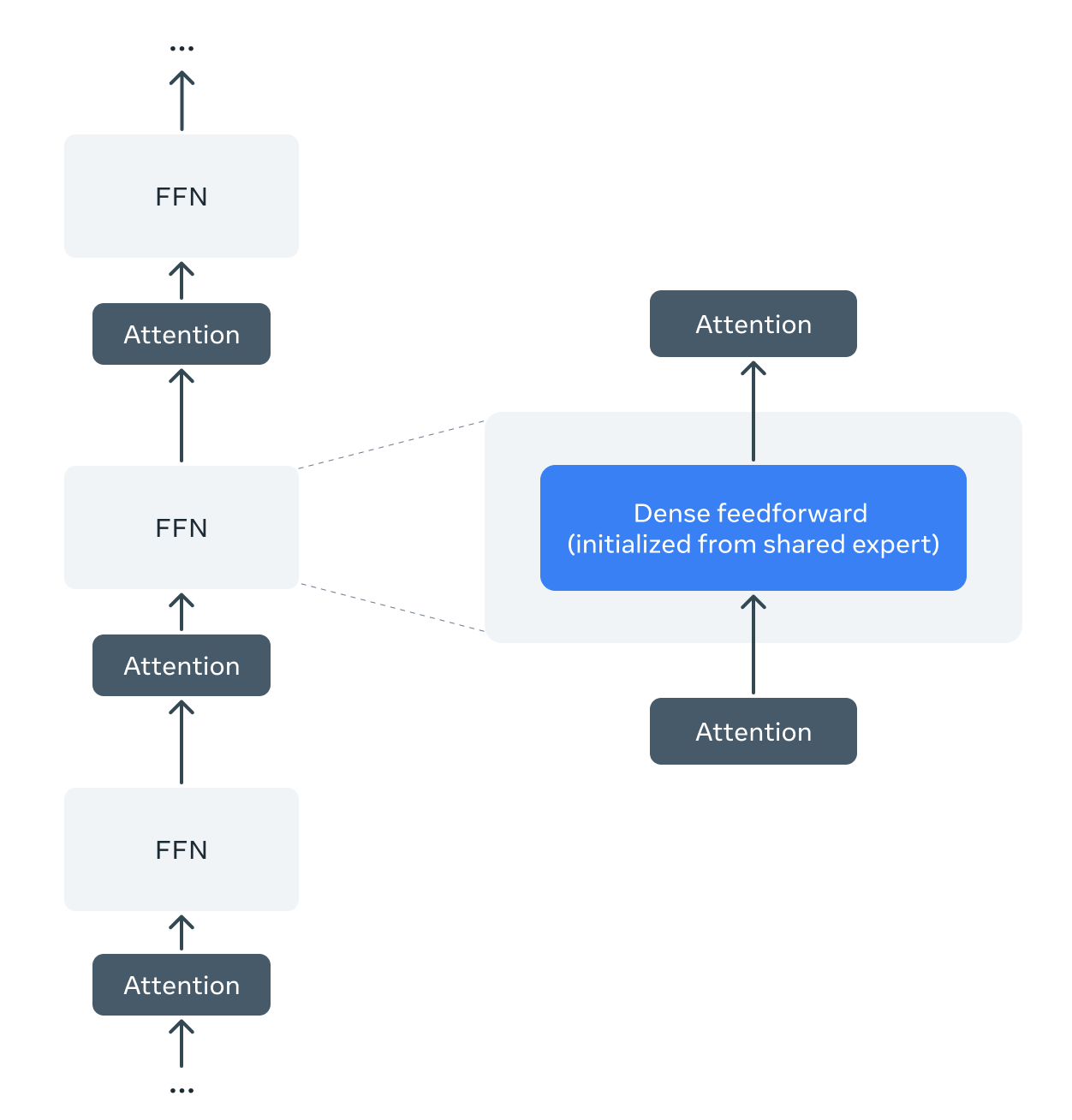 剪枝和后训练后:Llama Guard 4
剪枝和后训练后:Llama Guard 4
安全分类后训练
剪枝后,我们使用来自Llama Guard 3 - 8B和Llama Guard 3 - 11B - vision模型的数据混合对模型进行后训练,并添加了以下额外数据:
- 多图像训练数据,大多数样本包含2到5张图像。
- 多语言数据,包括专家人工注释编写的数据和从英语翻译的数据。 我们将两种模态的训练数据混合,纯文本数据与包含一个或多个图像的多模态数据的比例约为3:1。
评估
系统级安全
Llama Guard 4旨在与生成式语言模型集成使用,降低用户暴露的安全违规总体率。它可用于输入过滤、输出过滤或两者结合:输入过滤通过将用户输入到LLM的提示分类为安全或不安全,输出过滤通过将LLM生成的输出分类为安全或不安全。使用输入过滤的优点是可以在LLM响应之前尽早捕获不安全内容,而使用输出过滤的优点是LLM有机会以安全的方式响应不安全提示,因此只有当模型的最终输出被发现本身不安全时才会被审查。同时使用两种过滤方式可提供额外的安全性。 在一些内部测试中,我们发现输入过滤比输出过滤更能降低安全违规率并提高总体拒绝率,但实际情况可能会有所不同。我们发现Llama Guard 4在英语和多语言文本以及混合文本和图像的输入和输出过滤方面,大致匹配或超过了Llama Guard 3模型的总体性能。
分类器性能
以下表格展示了Llama Guard 4在英语和多语言文本以及单图像或多图像提示方面,与Llama Guard 3 - 8B(LG3)和Llama Guard 3 - 11B - vision(LG3v)相比,如何匹配或超过其总体性能,使用的是内部测试集。
| 绝对值 | 与Llama Guard 3相比 | |||||
|---|---|---|---|---|---|---|
| R | FPR | F1 | Δ R | Δ FPR | Δ F1 | |
| 英语 | 69% | 11% | 61% | 4% | -3% | 8% |
| 多语言 | 43% | 3% | 51% | -2% | -1% | 0% |
| 单图像 | 41% | 9% | 38% | 10% | 0% | 8% |
| 多图像 | 61% | 9% | 52% | 20% | -1% | 17% |
R:召回率,FPR:假阳性率。值来自输出过滤,将模型输出标记为安全或不安全。所有值是上述安全类别S1到S13样本的平均值,每个类别权重相等,多语言情况是Llama Guard 3 - 8B的7种非英语语言(法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语)的平均值。对于多图像提示,只有最后一张图像输入到不支持多图像的Llama Guard 3 - 11B - vision中。 我们省略了与竞争模型的评估,因为它们通常未与该分类器训练的特定安全政策对齐,无法进行直接比较。
🔧 技术细节
模型架构
Llama Guard 4是原生多模态防护模型,总共有120亿个参数,采用早期融合变压器架构和密集层,以保持整体规模较小。该模型可以在单个GPU上运行,并且与Llama 4 Scout和Maverick共享相同的分词器和视觉编码器。
训练过程
预训练与剪枝
Llama Guard 4采用密集前馈早期融合架构,与采用专家混合(MoE)层的Llama 4 Scout不同。为了利用Llama 4的预训练,我们开发了一种方法,将预训练的Llama 4 Scout专家混合架构剪枝为密集架构,并且不进行额外的预训练。 我们采用预训练的Llama 4 Scout检查点,每个专家混合层由一个共享密集专家和十六个路由专家组成。我们剪去所有路由专家和路由器层,仅保留共享专家。剪枝后,专家混合层减少为从共享专家权重初始化的密集前馈层。
安全分类后训练
剪枝后,我们使用来自Llama Guard 3 - 8B和Llama Guard 3 - 11B - vision模型的数据混合对模型进行后训练,并添加了以下额外数据:
- 多图像训练数据,大多数样本包含2到5张图像。
- 多语言数据,包括专家人工注释编写的数据和从英语翻译的数据。 我们将两种模态的训练数据混合,纯文本数据与包含一个或多个图像的多模态数据的比例约为3:1。
📄 许可证
LLAMA 4社区许可协议
协议概述
本协议规定了使用、复制、分发和修改Llama材料的条款和条件。通过点击“我接受”或使用或分发Llama材料的任何部分或元素,即表示您同意受本协议约束。
许可权利和再分发
- 权利授予:您被授予在Llama材料中体现的Meta知识产权或其他权利下的非排他性、全球性、不可转让和免版税的有限许可,以使用、复制、分发、复制、创作衍生作品并对Llama材料进行修改。
- 再分发和使用:
- 如果您分发或提供Llama材料(或其任何衍生作品),或包含其中任何内容的产品或服务(包括另一个AI模型),您应提供本协议的副本,并在相关网站、用户界面、博客文章、关于页面或产品文档上显著显示“Built with Llama”。如果您使用Llama材料或其任何输出或结果来创建、训练、微调或以其他方式改进AI模型并进行分发或提供,您还应在任何此类AI模型名称的开头包含“Llama”。
- 如果您作为集成最终用户产品的一部分从被许可方处接收Llama材料或其任何衍生作品,则本协议第2条不适用于您。
- 您必须在分发的所有Llama材料副本中保留以下归属声明:“Llama 4 is licensed under the Llama 4 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”
- 您对Llama材料的使用必须遵守适用的法律法规,并遵守Llama材料的可接受使用政策。
额外商业条款
如果在Llama 4版本发布日期,被许可方或其关联方提供的产品或服务的月活跃用户在前一个日历月超过7亿,则您必须向Meta请求许可,Meta可自行决定是否授予,在Meta明确授予您此类权利之前,您无权行使本协议下的任何权利。
保修免责声明
除非适用法律要求,Llama材料及其任何输出和结果按“现状”提供,不提供任何形式的保证,Meta否认所有明示和暗示的保证,包括但不限于所有权、不侵权、适销性或特定用途适用性的保证。您独自负责确定使用或再分发Llama材料的适当性,并承担与使用Llama材料及其任何输出和结果相关的任何风险。
责任限制
在任何情况下,Meta或其关联方均不对因本协议引起的任何利润损失或任何间接、特殊、后果性、偶发性、惩戒性或惩罚性损害承担责任,即使Meta或其关联方已被告知此类损害的可能性。
知识产权
- 商标许可:本协议未授予商标许可,与Llama材料相关,除非为合理和惯常描述和再分发Llama材料所需或本第5(a)条规定,Meta和被许可方均不得使用对方或其任何关联方拥有或关联的任何名称或标记。Meta特此授予您仅为遵守第1.b.i条最后一句所需使用“Llama”的许可。您将遵守Meta的品牌指南,所有因您使用该标记而产生的商誉归Meta所有。
- 衍生作品所有权:对于您对Llama材料所做的任何衍生作品和修改,在您和Meta之间,您是并将是此类衍生作品和修改的所有者,但需遵守Meta对Llama材料及其为Meta制作的衍生作品的所有权。
- 诉讼终止许可:如果您对Meta或任何实体提起诉讼或其他程序,声称Llama材料或Llama 4的输出或结果或其任何部分构成侵犯您拥有或可许可的知识产权或其他权利,则本协议授予您的任何许可将自该诉讼或索赔提起之日起终止。您将赔偿并使Meta免受因您使用或分发Llama材料而引起的任何第三方索赔。
期限和终止
本协议的期限自您接受本协议或访问Llama材料时开始,并将持续有效,直至根据本协议的条款和条件终止。如果您违反本协议的任何条款和条件,Meta可终止本协议。协议终止后,您应删除并停止使用Llama材料。第3、4和7条在协议终止后仍然有效。
适用法律和管辖权
本协议受加利福尼亚州法律管辖和解释,不考虑法律选择原则,《联合国国际货物销售合同公约》不适用于本协议。加利福尼亚州的法院对因本协议引起的任何争议具有专属管辖权。
局限性
模型性能限制
Llama Guard 4作为基于Llama 4微调的LLM,其性能可能受(预)训练数据的限制,例如在需要常识知识、多语言能力和政策覆盖的判断方面。
特定危害类别评估
某些危害类别(如诽谤、知识产权和选举)可能需要最新的事实知识才能全面评估。对于对这些类型危害高度敏感的用例,应部署更复杂的系统进行准确审核,但Llama Guard 4为通用用例提供了良好的基线。
图像数量影响
Llama Guard 4的性能测试主要使用包含少量图像(最常见为三张)的提示,因此在处理大量图像进行安全分类时,性能可能会有所不同。
对抗攻击风险
作为LLM,Llama Guard 4可能容易受到对抗攻击或提示注入攻击,从而绕过或改变其预期用途。有关检测提示攻击的信息,请参考Llama Prompt Guard 2。请随时报告漏洞,我们将考虑将改进纳入Llama Guard的未来版本。
最佳实践和安全考虑
有关其他最佳实践和安全考虑,请参考开发者使用指南。
参考文献
 Safetensors 英语
Safetensors 英语%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)