模型简介
模型特点
模型能力
使用案例
🚀 GLM-Z1-32B-0414 GGUF模型
GLM-Z1-32B-0414 GGUF模型是一款强大的文本生成模型,在低比特量化技术上有显著创新,能在不同硬件条件下高效运行,适用于多种自然语言处理场景。
🚀 快速开始
模型生成详情
本模型使用 llama.cpp 在提交版本 e291450 时生成。
✨ 主要特性
超低比特量化与IQ-DynamicGate(1 - 2比特)
- 精度自适应量化:最新量化方法为超低比特模型(1 - 2比特)引入了精度自适应量化,经基准测试证明在 Llama - 3 - 8B 上有显著改进。该方法采用特定层策略,在保持极高内存效率的同时保留准确性。
- 基准测试环境:所有测试均在 Llama - 3 - 8B - Instruct 上进行,使用标准困惑度评估管道、2048令牌上下文窗口,且所有量化使用相同的提示集。
- 方法:
- 动态精度分配:前/后25%的层采用IQ4_XS(选定层),中间50%采用IQ2_XXS/IQ3_S(提高效率)。
- 关键组件保护:嵌入层/输出层使用Q5_K,与标准1 - 2比特量化相比,误差传播降低38%。
- 量化性能对比(Llama - 3 - 8B):
| 量化方式 | 标准困惑度 | DynamicGate困惑度 | 困惑度变化 | 标准大小 | DG大小 | 大小变化 | 标准速度 | DG速度 |
|---|---|---|---|---|---|---|---|---|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
关键说明:
- PPL = 困惑度(越低越好)
- Δ PPL = 从标准量化到DynamicGate量化的困惑度百分比变化
- 速度 = 推理时间(CPU avx2,2048令牌上下文)
- 大小差异反映混合量化开销
主要改进:
- 🔥 IQ1_M 困惑度大幅降低43.9%(从27.46降至15.41)。
- 🚀 IQ2_S 困惑度降低36.9%,仅增加0.2GB大小。
- ⚡ IQ1_S 尽管是1比特量化,但准确性提高39.7%。
权衡:
- 所有变体大小略有增加(0.1 - 0.3GB)。
- 推理速度相近(差异<5%)。
何时使用这些模型
- 📌 将模型装入GPU显存
- ✔ 内存受限的部署场景
- ✔ 可容忍1 - 2比特误差的CPU和边缘设备
- ✔ 超低比特量化研究
选择合适的模型格式
选择正确的模型格式取决于你的 硬件能力 和 内存限制。
| 属性 | 详情 |
|---|---|
| 模型类型 | 文本生成 |
| 库名称 | transformers |
| 许可证 | MIT |
BF16(Brain Float 16) – 若支持BF16加速则使用
- 一种16位浮点格式,专为 更快计算 设计,同时保留良好精度。
- 提供与FP32 相似的动态范围,但 内存使用更低。
- 若硬件支持 BF16加速(检查设备规格),推荐使用。
- 与FP32相比,适用于 高性能推理 且 内存占用减少 的场景。
📌 使用BF16的情况:
- ✔ 硬件具有原生 BF16支持(如较新的GPU、TPU)。
- ✔ 希望在节省内存的同时获得 更高精度。
- ✔ 计划将模型 重新量化 为其他格式。
📌 避免使用BF16的情况:
- ❌ 硬件 不支持 BF16(可能会回退到FP32并运行更慢)。
- ❌ 需要与缺乏BF16优化的旧设备兼容。
F16(Float 16) – 比BF16更广泛支持
- 一种16位浮点格式,精度较高,但取值范围小于BF16。
- 适用于大多数支持 FP16加速 的设备(包括许多GPU和一些CPU)。
- 数值精度略低于BF16,但通常足以进行推理。
📌 使用F16的情况:
- ✔ 硬件支持 FP16 但 不支持BF16。
- ✔ 需要在 速度、内存使用和准确性之间取得平衡。
- ✔ 在 GPU 或其他针对FP16计算优化的设备上运行。
📌 避免使用F16的情况:
- ❌ 设备缺乏 原生FP16支持(可能运行比预期慢)。
- ❌ 存在内存限制。
量化模型(Q4_K、Q6_K、Q8等) – 用于CPU和低显存推理
量化可在尽可能保持准确性的同时减小模型大小和内存使用。
- 低比特模型(Q4_K):最适合 最小内存使用,可能精度较低。
- 高比特模型(Q6_K、Q8_0):准确性更好,但需要更多内存。
📌 使用量化模型的情况:
- ✔ 在 CPU 上运行推理并需要优化模型。
- ✔ 设备 显存较低,无法加载全精度模型。
- ✔ 希望在保持合理准确性的同时 减少内存占用。
📌 避免使用量化模型的情况:
- ❌ 需要 最高准确性(全精度模型更适合)。
- ❌ 硬件有足够的显存支持更高精度格式(BF16/F16)。
极低比特量化(IQ3_XS、IQ3_S、IQ3_M、Q4_K、Q4_0)
这些模型针对 极致内存效率 进行了优化,适用于 低功耗设备 或 大规模部署 中内存是关键限制的场景。
- IQ3_XS:超低比特量化(3比特),具有 极致内存效率。
- 使用场景:最适合 超低内存设备,即使Q4_K也太大的情况。
- 权衡:与高比特量化相比,准确性较低。
- IQ3_S:小块大小,实现 最大内存效率。
- 使用场景:最适合 低内存设备,当IQ3_XS过于激进时。
- IQ3_M:中等块大小,比 IQ3_S 准确性更好。
- 使用场景:适用于 低内存设备,当IQ3_S限制过多时。
- Q4_K:4比特量化,具有 逐块优化 以提高准确性。
- 使用场景:最适合 低内存设备,当Q6_K太大时。
- Q4_0:纯4比特量化,针对 ARM设备 优化。
- 使用场景:最适合 基于ARM的设备 或 低内存环境。
模型格式选择总结表
| 模型格式 | 精度 | 内存使用 | 设备要求 | 最佳使用场景 |
|---|---|---|---|---|
| BF16 | 最高 | 高 | 支持BF16的GPU/CPU | 减少内存的高速推理 |
| F16 | 高 | 高 | 支持FP16的设备 | BF16不可用时的GPU推理 |
| Q4_K | 中低 | 低 | CPU或低显存设备 | 内存受限环境 |
| Q6_K | 中等 | 适中 | 内存较多的CPU | 量化模型中准确性较好 |
| Q8_0 | 高 | 适中 | 有足够显存的CPU或GPU | 量化模型中最佳准确性 |
| IQ3_XS | 极低 | 极低 | 超低内存设备 | 极致内存效率和低准确性 |
| Q4_0 | 低 | 低 | ARM或低内存设备 | llama.cpp可针对ARM设备优化 |
📦 安装指南
文档未提及安装步骤,暂不提供相关内容。
💻 使用示例
基础用法
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
高级用法
文档未提及高级用法代码示例,暂不提供相关内容。
📚 详细文档
包含文件及详情
GLM-Z1-32B-0414-bf16.gguf
- 模型权重以 BF16 保存。
- 若要将模型 重新量化 为不同格式,使用此文件。
- 若设备支持 BF16加速,效果最佳。
GLM-Z1-32B-0414-f16.gguf
- 模型权重以 F16 存储。
- 若设备支持 FP16,尤其是BF16不可用时使用。
GLM-Z1-32B-0414-bf16-q8_0.gguf
- 输出和嵌入层 保持为 BF16。
- 所有其他层量化为 Q8_0。
- 若设备支持 BF16 且需要量化版本,使用此文件。
GLM-Z1-32B-0414-f16-q8_0.gguf
- 输出和嵌入层 保持为 F16。
- 所有其他层量化为 Q8_0。
GLM-Z1-32B-0414-q4_k.gguf
- 输出和嵌入层 量化为 Q8_0。
- 所有其他层量化为 Q4_K。
- 适用于 CPU推理 且内存有限的情况。
GLM-Z1-32B-0414-q4_k_s.gguf
- 最小的 Q4_K 变体,以牺牲准确性为代价减少内存使用。
- 最适合 极低内存设置。
GLM-Z1-32B-0414-q6_k.gguf
- 输出和嵌入层 量化为 Q8_0。
- 所有其他层量化为 Q6_K。
GLM-Z1-32B-0414-q8_0.gguf
- 完全 Q8 量化模型,以获得更好的准确性。
- 需要 更多内存,但提供更高精度。
GLM-Z1-32B-0414-iq3_xs.gguf
- IQ3_XS 量化,针对 极致内存效率 优化。
- 最适合 超低内存设备。
GLM-Z1-32B-0414-iq3_m.gguf
- IQ3_M 量化,提供 中等块大小 以提高准确性。
- 适用于 低内存设备。
GLM-Z1-32B-0414-q4_0.gguf
- 纯 Q4_0 量化,针对 ARM设备 优化。
- 最适合 低内存环境。
- 若追求更好的准确性,优先选择IQ4_NL。
测试模型
如果你觉得这些模型有用
❤ 如果觉得有用,请点击“点赞”! 帮助测试 支持量子安全检查的AI网络监控助手: 👉 免费网络监控器
💬 测试方法:
- 点击 聊天图标(任何页面右下角)。
- 选择 AI助手类型:
TurboLLM(GPT - 4 - mini)FreeLLM(开源)TestLLM(仅支持CPU的实验性模型)
测试内容
正在探索用于AI网络监控的小型开源模型的极限,具体包括:
- 针对实时网络服务的 函数调用。
- 模型可以多小 同时仍能处理:
- 自动化 Nmap扫描。
- 量子就绪检查。
- Metasploit集成。
🟡 TestLLM – 当前实验性模型(llama.cpp在6个CPU线程上):
- ✅ 零配置设置
- ⏳ 30秒加载时间(推理慢,但 无API成本)
- 🔧 寻求帮助! 如果你对边缘设备AI感兴趣,让我们合作!
其他助手
🟢 TurboLLM – 使用 gpt - 4 - mini 进行:
- 实时网络诊断
- 自动化渗透测试(Nmap/Metasploit)
- 🔑 通过 下载免费网络监控代理 获取更多令牌。
🔵 HugLLM – 开源模型(约80亿参数):
- 比TurboLLM多2倍令牌
- AI驱动的日志分析
- 🌐 在Hugging Face推理API上运行。
示例AI测试命令
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a quick Nmap vulnerability test"
GLM - 4 - Z1 - 32B - 0414介绍
GLM家族迎来了新一代开源模型 GLM - 4 - 32B - 0414 系列,拥有320亿参数。其性能可与OpenAI的GPT系列和DeepSeek的V3/R1系列相媲美,并支持非常友好的本地部署功能。GLM - 4 - 32B - Base - 0414在15T高质量数据上进行了预训练,包括大量推理类型的合成数据,为后续强化学习扩展奠定了基础。在后续训练阶段,除了针对对话场景进行人类偏好对齐外,还使用拒绝采样和强化学习等技术增强了模型在指令遵循、工程代码和函数调用方面的性能,强化了代理任务所需的原子能力。GLM - 4 - 32B - 0414在工程代码、工件生成、函数调用、基于搜索的问答和报告生成等领域取得了良好的效果。在一些基准测试中,甚至可以与GPT - 4o和DeepSeek - V3 - 0324(6710亿参数)等更大的模型相媲美。
GLM - Z1 - 32B - 0414 是一个具有 深度思考能力 的推理模型。它基于GLM - 4 - 32B - 0414通过冷启动和扩展强化学习开发,并在涉及数学、代码和逻辑的任务上进一步训练了模型。与基础模型相比,GLM - Z1 - 32B - 0414显著提高了数学能力和解决复杂任务的能力。在训练过程中,还引入了基于成对排名反馈的通用强化学习,进一步增强了模型的通用能力。
GLM - Z1 - Rumination - 32B - 0414 是一个具有 沉思能力 的深度推理模型(以OpenAI的深度研究为基准)。与典型的深度思考模型不同,沉思模型采用更长时间的深度思考来解决更开放和复杂的问题(例如,撰写两个城市AI发展的比较分析及其未来发展计划)。沉思模型在深度思考过程中集成了搜索工具以处理复杂任务,并通过利用多个基于规则的奖励来指导和扩展端到端强化学习进行训练。Z1 - Rumination在研究型写作和复杂检索任务中表现出显著的改进。
最后,GLM - Z1 - 9B - 0414 是一个惊喜。采用上述一系列技术训练了一个90亿参数的小型模型,保持了开源传统。尽管规模较小,但GLM - Z1 - 9B - 0414在数学推理和通用任务中仍表现出出色的能力。其整体性能在同规模的开源模型中已处于领先水平。特别是在资源受限的场景中,该模型在效率和效果之间取得了出色的平衡,为寻求轻量级部署的用户提供了强大的选择。
性能
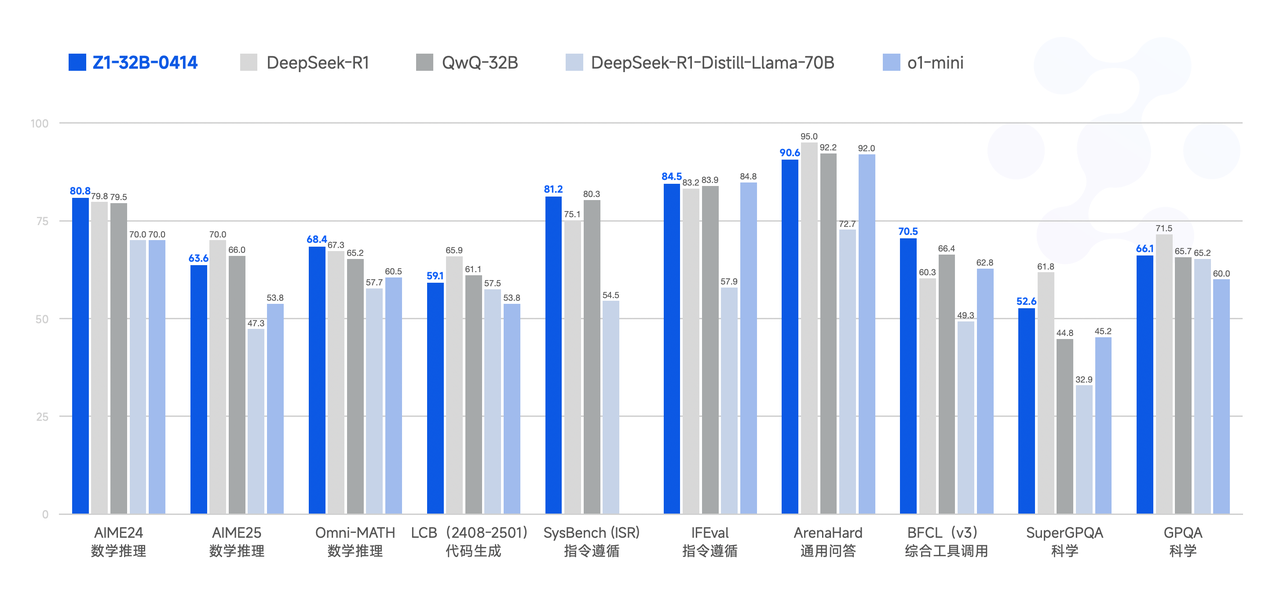
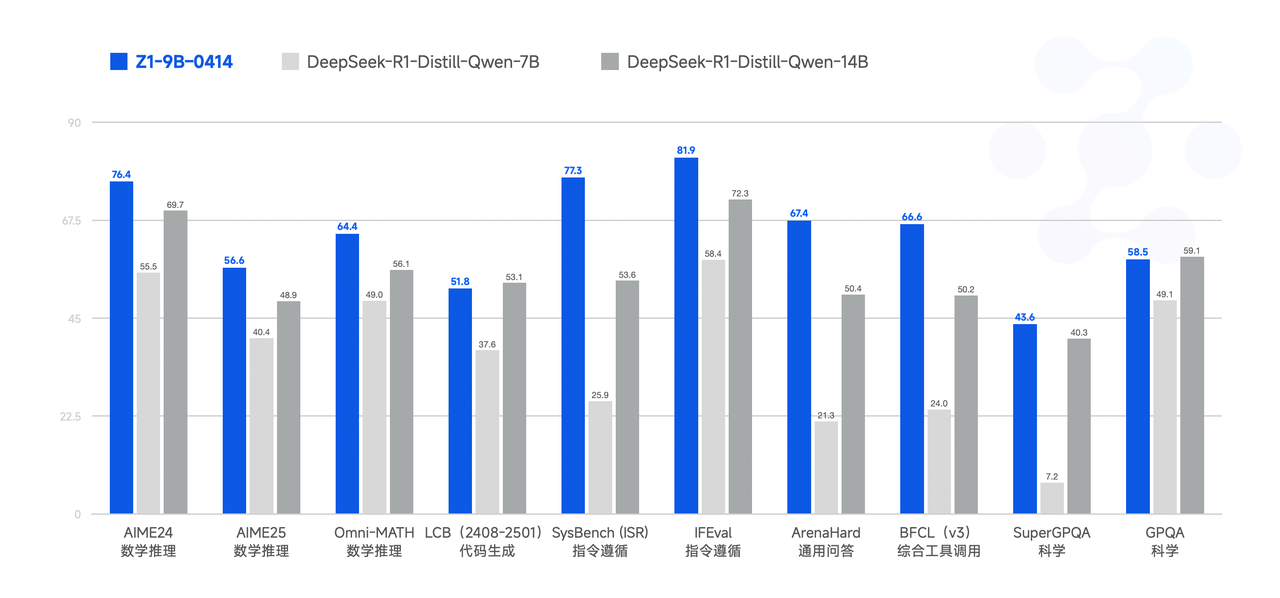
模型使用指南
I. 采样参数
| 参数 | 推荐值 | 描述 |
|---|---|---|
| temperature | 0.6 | 平衡创造性和稳定性 |
| top_p | 0.95 | 采样的累积概率阈值 |
| top_k | 40 | 过滤稀有令牌,同时保持多样性 |
| max_new_tokens | 30000 | 为思考留出足够的令牌 |
II. 强制思考
- 在 第一行 添加 <think>\n:确保模型在回复前进行思考。
- 使用
chat_template.jinja时,提示会自动注入以强制执行此行为。
III. 对话历史修剪
- 仅保留 最终用户可见的回复。
- 隐藏的思考内容 不应 保存到历史记录中以减少干扰 — 这已在
chat_template.jinja中实现。
IV. 处理长上下文(YaRN)
- 当输入长度超过 8192个令牌 时,考虑启用YaRN(Rope缩放)。
- 在支持的框架中,将以下代码段添加到
config.json中:
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
- 静态YaRN 适用于所有文本。它可能会略微降低短文本的性能,因此按需启用。
🔧 技术细节
文档未提及详细技术细节,暂不提供相关内容。
📄 许可证
本项目采用MIT许可证。
引用
如果你认为我们的工作有用,请考虑引用以下论文:
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)