🚀 OpenHands Critic Model
OpenHands Critic Model是一个用于研究的模型,在软件工程基准测试中取得了优异成绩。它借助推理时间缩放和评估模型,在SWE - Bench Verified上达到了先进水平,为解决实际软件工程挑战提供了有力支持。
🚀 快速开始
本模型严格用于研究,目前还不兼容OpenHands应用程序。有关此模型的完整信息,包括其功能和限制,请参阅我们的详细博客文章。
你可以通过以下方式体验OpenHands:
- 使用OpenHands云服务:最简单的入门方式是使用我们的全托管云解决方案,它提供50美元的免费信用额度、无缝的GitHub集成、移动支持以及如上下文压缩等优化功能,随时可用。
- 参与开源贡献:给我们的GitHub仓库加星、提出问题或发送拉取请求,助力开源人工智能软件开发的发展。
- 加入我们的社区:在Slack上与我们交流,阅读我们的文档,并及时了解我们的最新动态。
✨ 主要特性
在SWE - Bench上取得先进成果
OpenHands在SWE - Bench Verified上达到了新的里程碑,取得了先进的成果。
推理时间缩放
对于具有挑战性的软件工程任务,多次尝试解决方案并选择最佳方案可以获得更好的结果。具体步骤如下:
- 对于每个SWE - Bench问题,使用Claude 3.7 Sonnet以采样温度1.0多次运行OpenHands代理,生成多个解决方案和代码补丁。
- 训练一个“评估模型”,评估每个解决方案并预测其是否为好的解决方案。
- 过滤掉未通过回归和重现测试的代码补丁。
- 从得分最高的轨迹中选择解决方案作为最终答案。
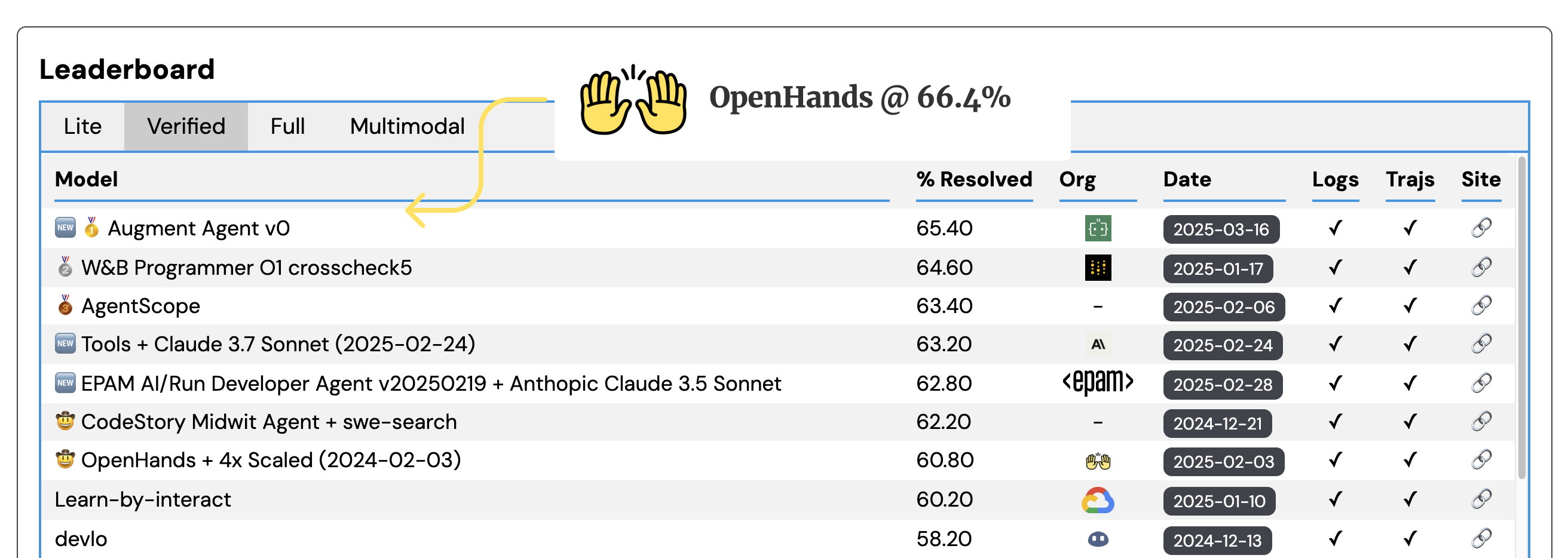
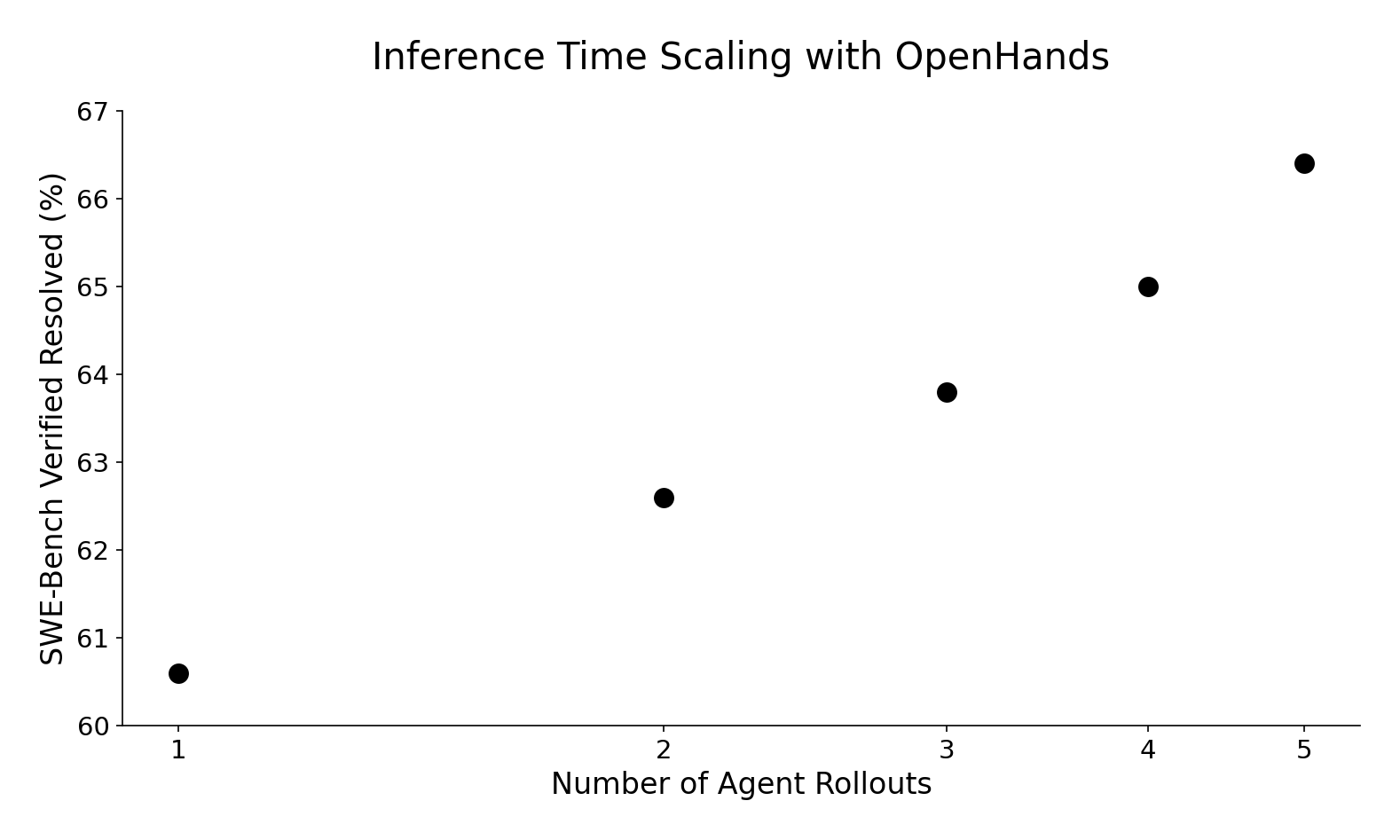
这种推理时间缩放方法使我们在不修改底层代理模型和框架的情况下取得了显著更好的结果。从单次轨迹推出的60.6%到五次尝试的66.4%,性能呈对数线性提升,这将使我们的提交在排行榜上名列前茅!
训练专用评估模型
与基于提示的重排序策略不同,我们训练了一个专用的评估模型,该模型提供了更有效的结果。训练过程如下:
- 从[SWE - Gym](https://github.com/SWE - Gym/SWE - Gym)中推出代理轨迹,以避免数据泄漏。
- 实施时间差分(TD)学习目标,将单元测试执行的轨迹级成功信号反向传播到每个轨迹。
- 在最后一层添加回归头以预测奖励值。
TD学习目标特别强大,因为它有助于模型理解哪些行动对最终结果有贡献:
$$
r_t = \gamma r_{t + 1}
$$
其中$r_t$是时间步$t$的奖励(即代理产生的第$t$个动作),$\gamma$是折扣因子。该过程从最终奖励$r_T$开始,$r_T$由对完整解决方案运行单元测试确定 - 通过所有测试为1,失败为0。然后将此终端奖励反向传播到轨迹中,每个先前步骤都乘以$\gamma$。我们使用$\gamma = 0.99$。
我们使用veRL对[Qwen 2.5 Coder Instruct 32B](https://huggingface.co/Qwen/Qwen2.5 - Coder - 32B - Instruct)进行微调作为评估模型。在推理过程中,我们使用[修改版的vLLM](https://github.com/xingyaoww/vllm/tree/add - token - classification - support)来服务此模型进行评估(有趣的是:OpenHands代理本身编写了那里的大部分功能[代码](https://github.com/vllm - project/vllm/compare/main...xingyaoww:vllm:add - token - classification - support))。
我们将评估模型[公开发布在Hugging Face上](https://huggingface.co/all - hands/openhands - critic - 32b - exp - 20250417),供希望探索其功能或在我们的工作基础上进行拓展的研究人员使用。
评估模型的优势和应用前景
- 泛化实用性:基于提示工程的重排序器可以提高基准测试分数,但难以保证在现实世界中的泛化能力。我们相信,有了足够的数据,训练有素的评估模型可以推广到SWE - Bench之外的各种软件工程场景,使其成为解决日常编码任务中实际问题的有价值工具。
- 利用中间奖励进行未来改进:虽然我们目前的实现侧重于从多个轨迹中选择最佳完整解决方案,但每个轨迹中预测的中间奖励为增强我们的代理能力开辟了令人兴奋的可能性。
- 一步前瞻采样:允许我们在每个步骤评估多个潜在动作,使用评估模型的分数选择最有前途的前进路径(实验性[PR](https://github.com/All - Hands - AI/OpenHands/pull/7770))。
- 实时错误恢复:是我们正在探索的另一个领域,评估模型可以识别奖励下降并帮助代理在解决方案过程中纠正方向([问题](https://github.com/All - Hands - AI/OpenHands/issues/2221))。
📦 安装指南
暂未提供相关安装步骤。
💻 使用示例
暂未提供相关代码示例。
📚 详细文档
SWE - Bench和OpenHands
SWE - bench是评估大语言模型(LLMs)解决实际软件工程挑战能力的最流行基准。它由GitHub上12个流行Python仓库的问题和相应的拉取请求组成,要求系统生成代码补丁以解决指定问题。我们评估的已验证子集由500个精心挑选的测试用例组成,这些测试用例已由[人类软件开发人员](https://openai.com/index/introducing - swe - bench - verified/)手动审核,以验证它们具有适当范围的单元测试和明确的问题描述。
由于其现实性以及能够自主解决实际软件开发挑战的AI代理可能带来的巨大好处,它在学术界和工业界被广泛用作衡量AI编码代理能力的黄金标准。
我们正在开发[OpenHands](https://github.com/All - Hands - AI/OpenHands)开源软件开发代理,它在该数据集上的性能目前为60.6%,相当不错!
🔧 技术细节
评估模型训练
- 数据来源:从[SWE - Gym](https://github.com/SWE - Gym/SWE - Gym)中推出代理轨迹,避免数据泄漏。
- 学习目标:实施时间差分(TD)学习目标,将单元测试执行的轨迹级成功信号反向传播到每个轨迹。
- 模型结构:在最后一层添加回归头以预测奖励值。
推理过程
使用[修改版的vLLM](https://github.com/xingyaoww/vllm/tree/add - token - classification - support)来服务评估模型进行评估。
📄 许可证
本模型采用MIT许可证。
📋 模型信息
| 属性 |
详情 |
| 模型类型 |
令牌分类 |
| 基础模型 |
Qwen/Qwen2.5 - Coder - 32B - Instruct |
| 标签 |
agent、coding |
⚠️ 重要提示
本模型严格用于研究,目前还不兼容OpenHands应用程序。
💡 使用建议
如果你对评估模型的能力感兴趣或想在我们的工作基础上进行拓展,可以访问[Hugging Face上的评估模型](https://huggingface.co/all - hands/openhands - critic - 32b - exp - 20250417)。同时,欢迎参与我们的开源项目,为解决实际软件工程问题贡献力量。

 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)