🚀 StarCoder2-Instruct:用于代码生成的完全透明且许可宽松的自对齐模型
StarCoder2-Instruct是一款用于代码生成的模型,它采用了完全透明且许可宽松的自对齐训练方式,能在代码生成任务中提供高效准确的输出。

✨ 主要特性
我们推出了StarCoder2-15B-Instruct-v0.1,这是首个使用完全许可宽松且透明的管道进行训练的完全自对齐代码大语言模型(LLM)。我们的开源管道使用StarCoder2-15B生成数千个指令 - 响应对,然后用于微调StarCoder-15B本身,无需任何人工注释或来自大型专有LLM的蒸馏数据。

📚 详细文档
引用
@article{wei2024selfcodealign,
title={SelfCodeAlign: Self-Alignment for Code Generation},
author={Yuxiang Wei and Federico Cassano and Jiawei Liu and Yifeng Ding and Naman Jain and Zachary Mueller and Harm de Vries and Leandro von Werra and Arjun Guha and Lingming Zhang},
year={2024},
journal={arXiv preprint arXiv:2410.24198}
}
使用说明
预期用途
该模型旨在单轮响应与编码相关的指令。其他风格的指令可能会导致响应准确性降低。
以下是使用transformers库开始使用该模型的示例:
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
以下是预期输出:
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
偏差、风险和局限性
StarCoder2-15B-Instruct-v0.1主要针对可通过执行验证的Python代码生成任务进行微调,这可能会导致某些偏差和局限性。例如,模型可能不会严格遵循规定输出格式的指令。在这些情况下,提供响应前缀或单样本示例来引导模型输出是有益的。此外,该模型在其他编程语言和领域外的编码任务上可能存在局限性。
该模型还继承了其基础模型StarCoder2-15B的偏差、风险和局限性。更多信息,请参考StarCoder2-15B模型卡片。
评估结果
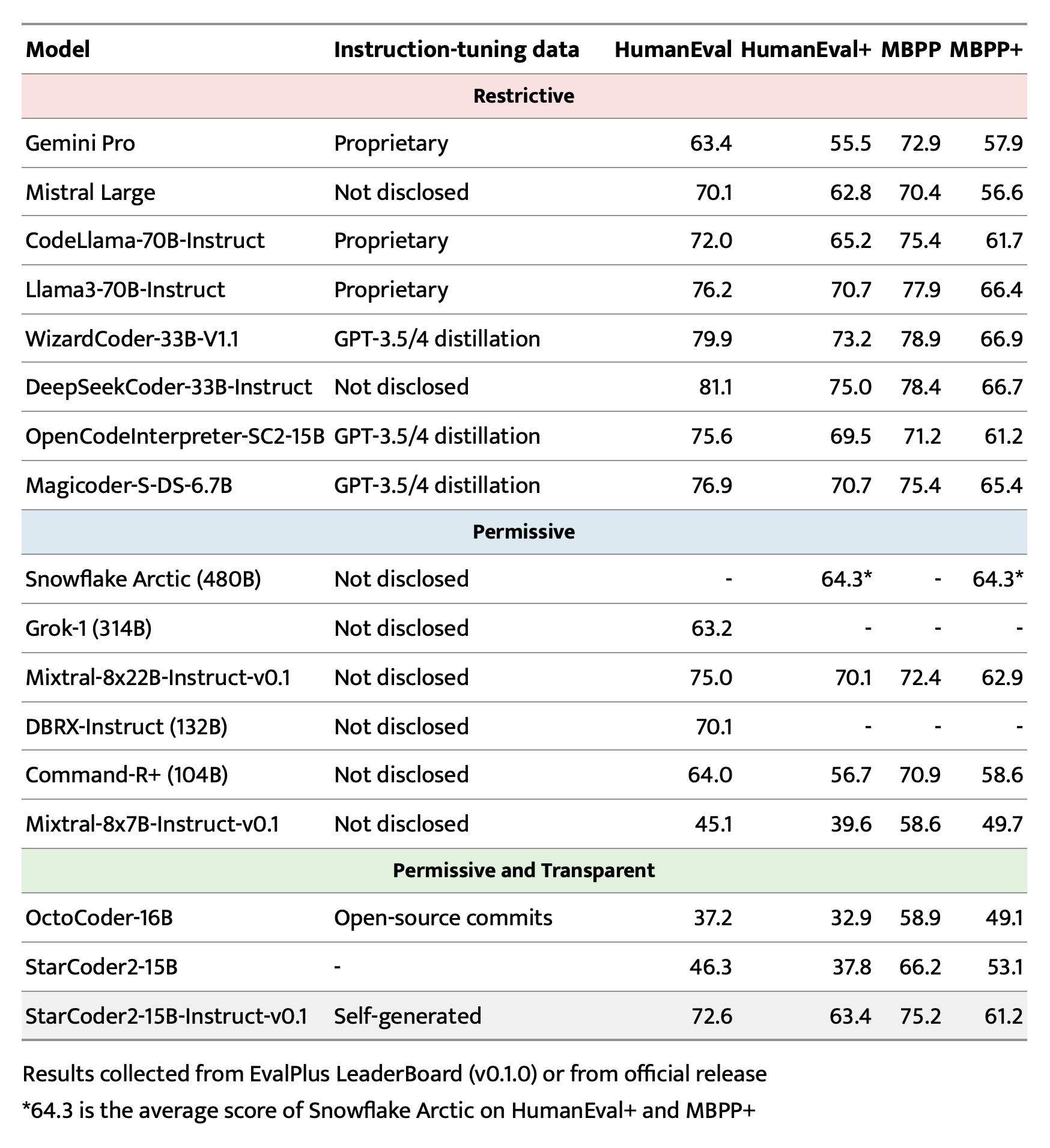
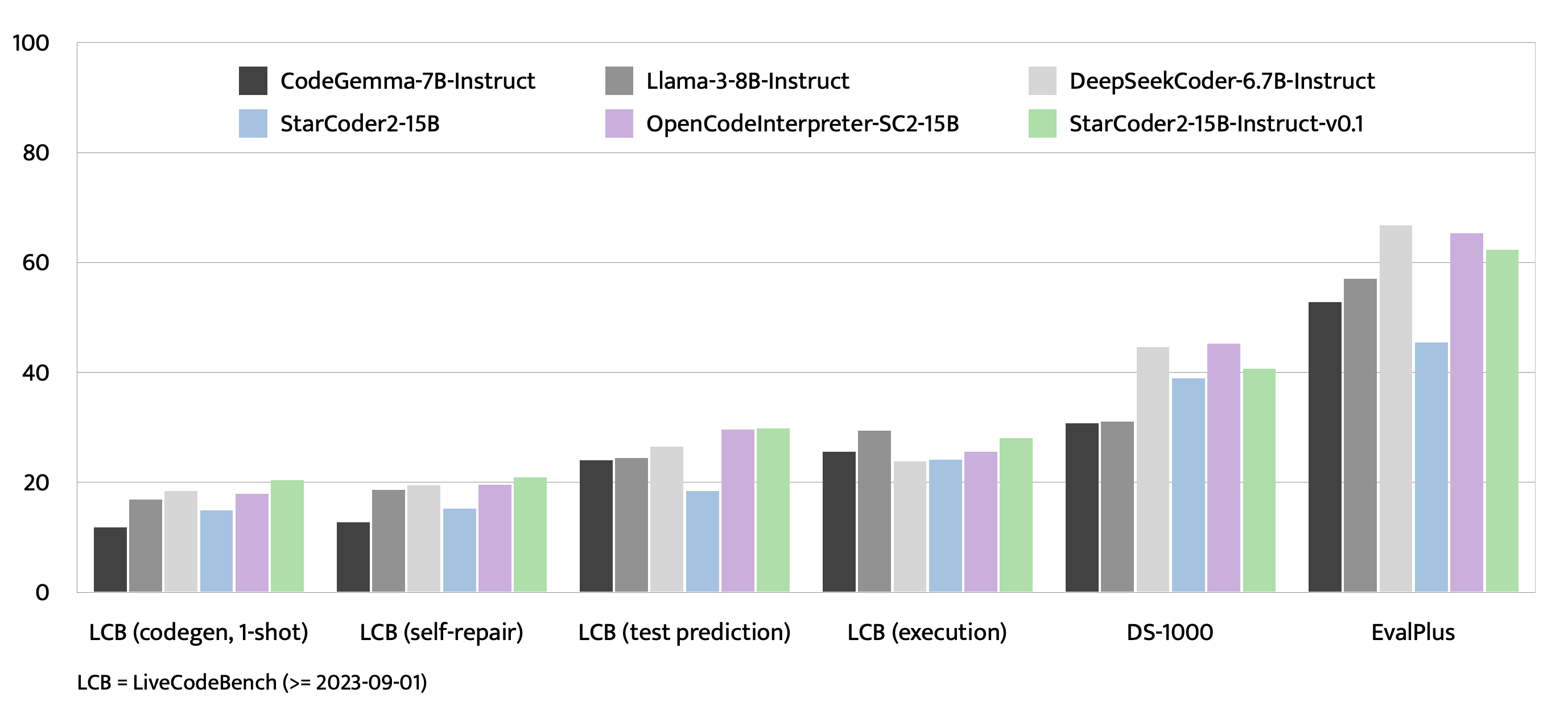
训练细节
超参数
| 属性 |
详情 |
| 优化器 |
Adafactor |
| 学习率 |
1e - 5 |
| 轮数 |
4 |
| 批量大小 |
64 |
| 热身比例 |
0.05 |
| 调度器 |
线性 |
| 序列长度 |
1280 |
| 丢弃率 |
未应用 |
硬件
1 x NVIDIA A100 80GB
资源
完整数据管道
我们的数据集生成管道有几个步骤。我们为管道的每个步骤提供中间数据集:
- 从The Stack v1过滤的原始种子数据集:https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered
- 使用StarCoder2-15B作为判断器过滤掉带有不良文档字符串的项目的种子数据集:https://huggingface.co/datasets/bigcode/python-stack-v1-functions-filtered-sc2
- 种子 -> 概念:https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-concepts
- 概念 -> 指令:https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-instructions
- 指令 -> 响应:https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-responses-unfiltered
- 通过执行过滤的响应:https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-500k-raw
- 通过去重过滤的执行响应(最终数据集):https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)