🚀 Apollo2-7B-GGUF
Apollo2-7B-GGUF 是基于原始模型 Apollo2-7B 的量化版本,支持多种语言,可用于医疗问答等场景,由 FreedomIntelligence 团队制作。
🚀 快速开始
本模型基于原始的 Apollo2-7B 模型进行量化,由 FreedomIntelligence 制作。它适用于与 llama.cpp 兼容的应用程序,如 Text-Generation-WebUI、KoboldCpp、Jan、LM Studio 等。
✨ 主要特性
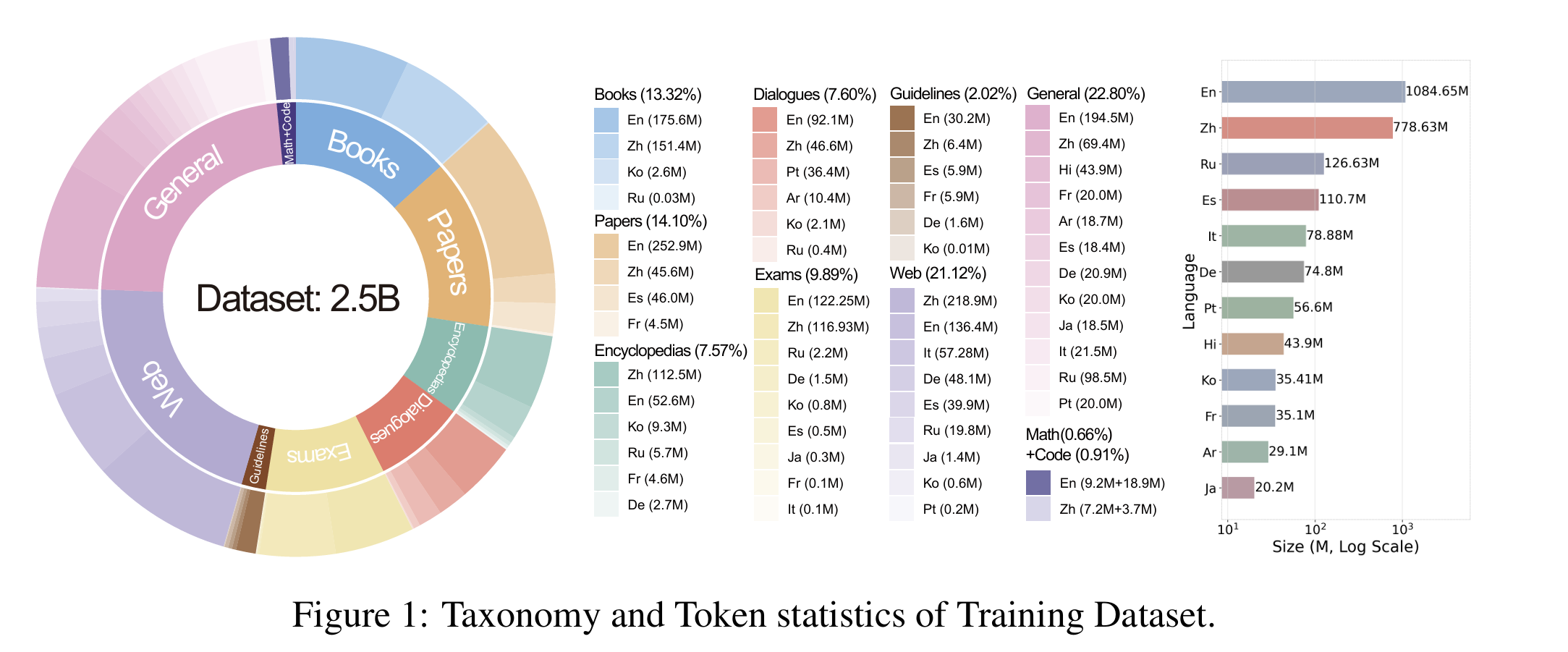
- 多语言支持:覆盖包括英语、中文、法语、印地语、西班牙语、阿拉伯语、俄语、日语、韩语、德语、意大利语、葡萄牙语等 12 种主要语言以及 38 种小语种。
- 医疗领域适用:专注于医疗领域,可用于生物、医学相关的问答任务。
- 多种量化版本:提供多种量化版本,以适应不同的设备和性能需求。
📦 安装指南
暂未提供具体安装步骤,你可以参考 llama.cpp 兼容应用程序的相关文档进行安装。
💻 使用示例
基础用法
不同规模的模型有不同的使用格式:
Apollo2
- 0.5B、1.5B、7B:
User:{query}\nAssistant:{response}<|endoftext|>
- 2B、9B:
User:{query}\nAssistant:{response}\<eos\>
- 3.8B:
<|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
Apollo-MoE
- 0.5B、1.5B、7B:
User:{query}\nAssistant:{response}<|endoftext|>
📚 详细文档
量化说明
使用 llama.cpp-b3938 基于 Exllamav2 校准数据集的 imatrix 文件进行量化。
- 2024 年 12 月 17 日:更新说明,近期 llama.cpp 移除了对 Q4_0_4_4、Q4_0_4_8 和 Q4_0_8_8 的支持,保留但可能不再有用。
- 2025 年 2 月 3 日:为支持较新 llama.cpp 版本的 ARM 设备,添加了 Q4_0 和 IQ4_NL 量化版本,替代 Q4_0_X_Y 量化版本。
原始模型介绍
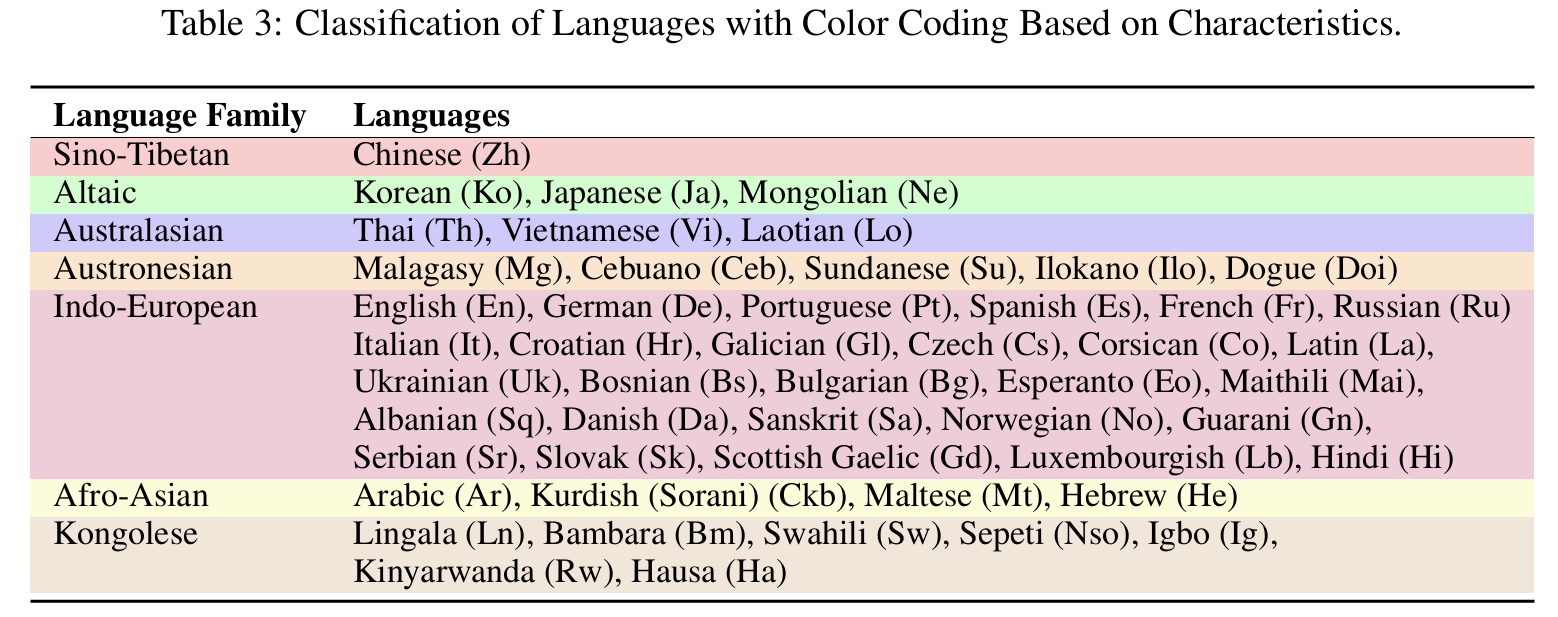
该模型旨在为更多语言的医疗大语言模型实现民主化,目前已覆盖 12 种主要语言和 38 种小语种。
语言覆盖情况
涵盖 12 种主要语言和 38 种小语种,具体语言列表如下:
- ar、en、zh、ko、ja、mn、th、vi、lo、mg、de、pt、es、fr、ru、it、hr、gl、cs、co、la、uk、bs、bg、eo、sq、da、sa、gn、sr、sk、gd、lb、hi、ku、mt、he、ln、bm、sw、ig、rw、ha
点击查看语言覆盖情况
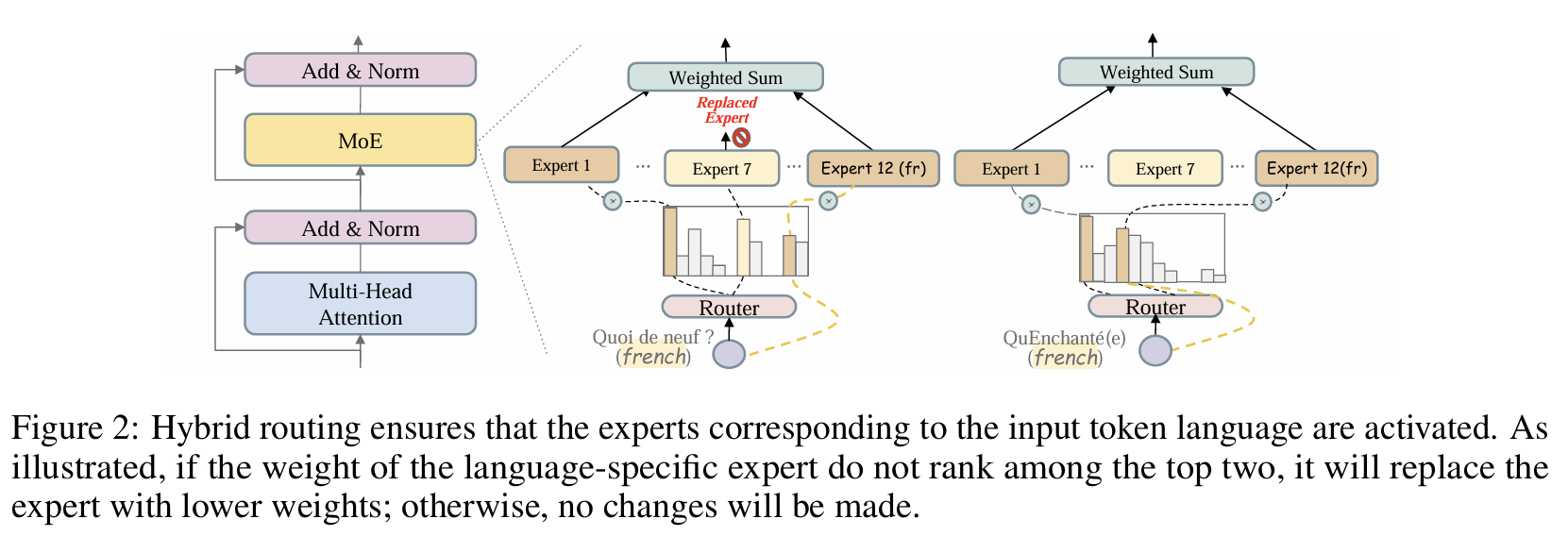
架构
点击查看 MoE 路由图
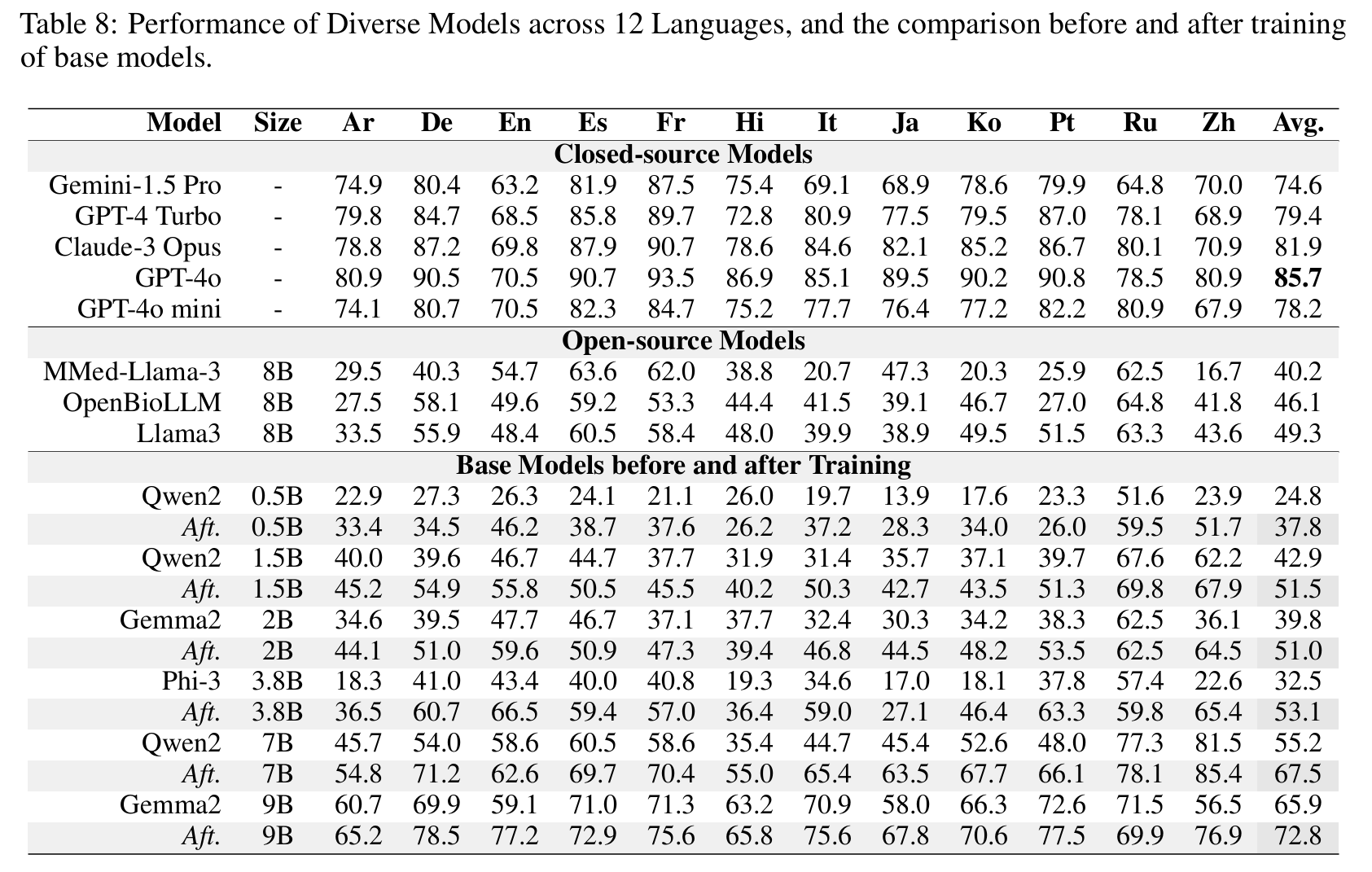
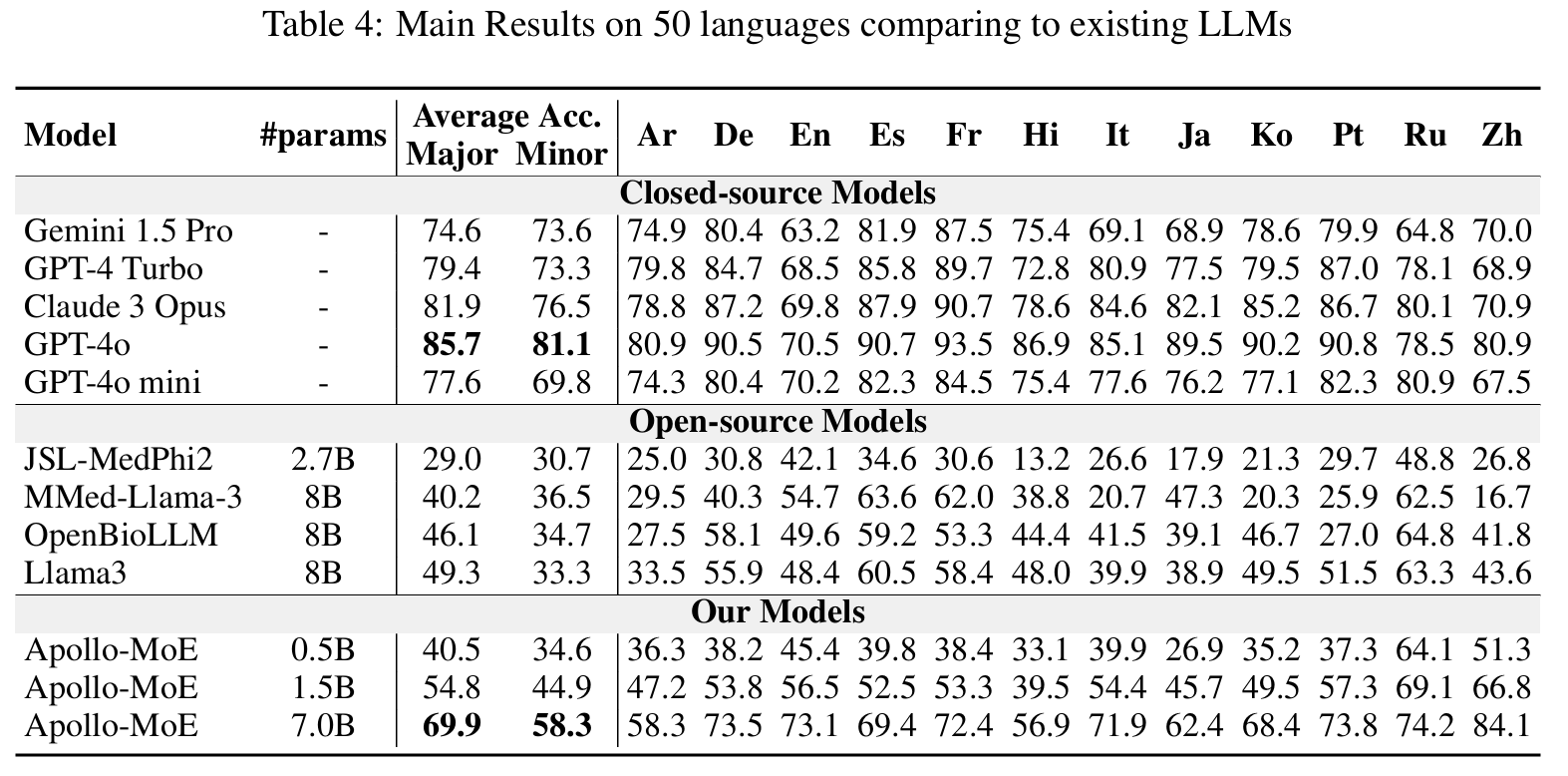
模型结果
密集模型
点击查看密集模型结果
后 MoE 模型
点击查看后 MoE 模型结果
数据集与评估
数据集
评估基准
结果复现
以 Apollo2-7B 或 Apollo-MoE-0.5B 为例:
- 下载项目数据集:
bash 0.download_data.sh
- 为特定模型准备测试和开发数据:
bash 1.data_process_test&dev.sh
- 为特定模型准备训练数据(提前创建分词数据):
bash 2.data_process_train.sh
你可以在这一步调整数据训练顺序和训练轮数。
4. 训练模型:
bash 3.single_node_train.sh
如果你想在多节点上训练,请参考 ./src/sft/training_config/zero_multi.yaml。
5. 评估模型:
bash 4.eval.sh
🔧 技术细节
本模型基于 llama.cpp 进行量化,使用 Exllamav2 校准数据集的 imatrix 文件。在量化过程中,对不同的量化版本进行了支持和调整,以适应不同的设备和性能需求。
📄 许可证
本项目采用 Apache-2.0 许可证。
📚 引用
如果你打算使用我们的数据集进行训练或评估,请使用以下引用:
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)