🚀 Poseless-3B
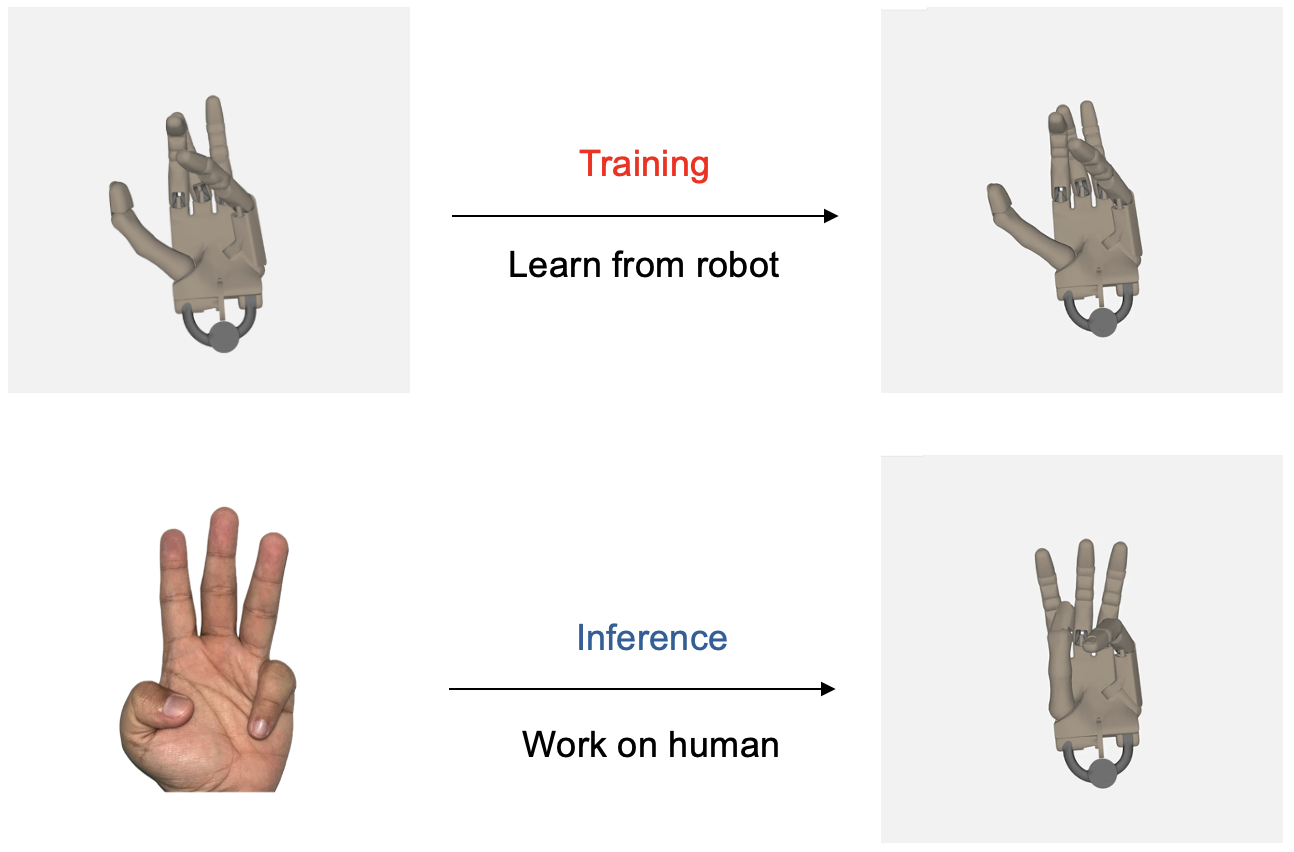
Poseless-3B 是一个用于机器人手部控制的模型,它通过直接将 2D 图像映射到关节角度,避免了显式的姿态估计。该模型利用合成训练数据,实现了对现实场景的零样本泛化以及从机器人手到人类手的跨形态迁移。
🚀 快速开始
以下是使用 Poseless-3B 模型进行手部姿态估计的示例代码:
import torch
from PIL import Image
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
from qwen_vl_utils import process_vision_info
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = "homebrewltd/Poseless-3B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.bfloat16
).eval().to(device)
processor = AutoProcessor.from_pretrained(
model_path,
min_pixels=256*28*28,
max_pixels=1280*28*28,
trust_remote_code=True
)
image = Image.open("your_hand_image.png").convert("RGB")
SYSTEM_PROMPT = """You are a specialized Vision Language Model designed to accurately estimate joint angles from hand pose images. Your task is to analyze images of a human or robotic hand and output precise angle measurements for each joint. Output joint angles in radians.
Output Format:
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4><lh_FFJ3>angle</lh_FFJ3><lh_FFJ2>angle</lh_FFJ2><lh_FFJ1>angle</lh_FFJ1><lh_MFJ4>angle</lh_MFJ4><lh_MFJ3>angle</lh_MFJ3><lh_MFJ2>angle</lh_MFJ2><lh_MFJ1>angle</lh_MFJ1><lh_RFJ4>angle</lh_RFJ4><lh_RFJ3>angle</lh_RFJ3><lh_RFJ2>angle</lh_RFJ2><lh_RFJ1>angle</lh_RFJ1><lh_LFJ5>angle</lh_LFJ5><lh_LFJ4>angle</lh_LFJ4><lh_LFJ3>angle</lh_LFJ3><lh_LFJ2>angle</lh_LFJ2><lh_LFJ1>angle</lh_LFJ1><lh_THJ5>angle</lh_THJ5><lh_THJ4>angle</lh_THJ4><lh_THJ3>angle</lh_THJ3><lh_THJ2>angle</lh_THJ2><lh_THJ1>angle</lh_THJ1>
"""
messages = [
{"role": "system", "content": f"{SYSTEM_PROMPT}"},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
"min_pixels": 1003520,
"max_pixels": 1003520,
},
{"type": "text", "text": "<Pose>"},
],
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors="pt").to(device)
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(output_text)
输出将是以 XML 格式表示的弧度制关节角度:
<lh_WRJ2>angle</lh_WRJ2><lh_WRJ1>angle</lh_WRJ1><lh_FFJ4>angle</lh_FFJ4>...
✨ 主要特性
- 创新框架:利用 VLM(如 Qwen 2.5 3B Instruct)直接将单目图像映射到机器人关节角度,完全绕过姿态估计。VLM 能够“观察”和投影图像,实现了强大的、与形态无关的特征提取,减少了两阶段管道中固有的误差传播。
- 合成数据管道:通过随机化关节角度和对视觉特征(如光照、纹理)进行域随机化,生成无限的训练示例。这消除了对昂贵的标记数据集的依赖,同时确保了对现实世界变化的鲁棒性。
- 跨形态泛化:模型展示了跨形态泛化能力,尽管仅在机器人手部数据上进行训练,但仍能模仿人类手部动作。这些发现为更广泛的应用理解和利用这种泛化能力迈出了重要一步。
- 无深度控制:证明了无深度控制是可行的,为后续采用不支持深度估计能力的相机铺平了道路,而这种相机在机器人研究中经常使用。
📚 详细文档
模型详情
论文引用
更多信息
如需进一步了解,请通过以下邮箱联系作者:alan@menlo.ai, bach@menlo.ai, charles@menlo.ai, yuuki@menlo.ai。
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)