模型简介
模型特点
模型能力
使用案例
🚀 Controlnet - v1.1 - 深度版本
Controlnet v1.1是一种基于额外条件控制扩散模型的神经网络结构,可与Stable Diffusion结合使用,实现基于深度图像的文本到图像生成。
🚀 快速开始
Controlnet v1.1是Controlnet v1.0的后续模型,由Lvmin Zhang发布于lllyasviel/ControlNet-v1-1。
此检查点是将原始检查点转换为diffusers格式后的版本,可与Stable Diffusion结合使用,例如runwayml/stable-diffusion-v1-5。
更多详细信息,请查看🧨 Diffusers文档。
ControlNet是一种通过添加额外条件来控制扩散模型的神经网络结构。

此检查点对应于基于深度图像的ControlNet。
✨ 主要特性
- 可结合Stable Diffusion:能与Stable Diffusion模型结合,如runwayml/stable-diffusion-v1-5,实现文本到图像的生成。
- 基于深度图像条件:该检查点基于深度图像进行条件控制,可生成与深度信息相关的图像。
- 解决训练数据问题:新版本的深度模型解决了之前训练数据集中存在的问题,如重复图像、低质量图像和错误配对提示等。
- 相对无偏模型:新的深度模型是一个相对无偏的模型,不依赖特定的深度估计方法,能更好地适应不同的深度估计和预处理分辨率。
- 数据增强:在训练过程中应用了合理的数据增强方法,如随机左右翻转。
- 兼容性好:该模型在深度1.0表现良好的所有情况下都能正常工作,并且在深度1.0失败的许多情况下也能有较好的表现。
📦 安装指南
若要处理图像以创建辅助条件,需要安装以下外部依赖:
$ pip install diffusers transformers accelerate
💻 使用示例
基础用法
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from transformers import pipeline
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_depth"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11p_sd15_depth/resolve/main/images/input.png"
)
prompt = "Stormtrooper's lecture in beautiful lecture hall"
depth_estimator = pipeline('depth-estimation')
image = depth_estimator(image)['depth']
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
control_image = Image.fromarray(image)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')
高级用法
在上述基础用法的基础上,可以尝试不同的提示词、推理步数、随机种子等参数,以获得不同风格和效果的图像。例如,可以修改prompt和num_inference_steps参数:
# 修改提示词和推理步数
prompt = "A beautiful landscape with a waterfall"
num_inference_steps = 50
generator = torch.manual_seed(1)
image = pipe(prompt, num_inference_steps=num_inference_steps, generator=generator, image=control_image).images[0]
image.save('images/image_out_advanced.png')



📚 详细文档
模型详情
| 属性 | 详情 |
|---|---|
| 开发者 | Lvmin Zhang, Maneesh Agrawala |
| 模型类型 | 基于扩散的文本到图像生成模型 |
| 语言 | 英文 |
| 许可证 | CreativeML OpenRAIL M许可证是一种Open RAIL M许可证,改编自BigScience和RAIL Initiative在负责任AI许可领域的联合工作。另见关于BLOOM Open RAIL许可证的文章,本许可证基于该文章 |
| 更多信息资源 | GitHub仓库,论文 |
| 引用方式 | @misc{zhang2023adding, title={Adding Conditional Control to Text-to-Image Diffusion Models}, author={Lvmin Zhang and Maneesh Agrawala}, year={2023}, eprint={2302.05543}, archivePrefix={arXiv}, primaryClass={cs.CV} } |
模型介绍
Controlnet由Lvmin Zhang和Maneesh Agrawala在Adding Conditional Control to Text-to-Image Diffusion Models中提出。
论文摘要如下:
我们提出了一种神经网络结构ControlNet,用于控制预训练的大型扩散模型以支持额外的输入条件。ControlNet以端到端的方式学习特定任务的条件,并且即使在训练数据集较小(< 50k)的情况下,学习也很稳健。此外,训练ControlNet的速度与微调扩散模型的速度一样快,并且可以在个人设备上进行训练。或者,如果有强大的计算集群,该模型可以扩展到大量(数百万到数十亿)的数据。我们报告称,像Stable Diffusion这样的大型扩散模型可以通过ControlNets进行增强,以支持边缘图、深度图、关键点等条件输入。这可能会丰富控制大型扩散模型的方法,并进一步促进相关应用的发展。
其他已发布的检查点v1-1
作者发布了14种不同的检查点,每种检查点都在Stable Diffusion v1-5上基于不同类型的条件进行训练:
| 模型名称 | 控制图像概述 | 条件图像 | 控制图像示例 | 生成图像示例 |
|---|---|---|---|---|
| lllyasviel/control_v11p_sd15_canny |
使用Canny边缘检测进行训练 | 黑色背景上带有白色边缘的单色图像。 |  |
 |
| lllyasviel/control_v11e_sd15_ip2p |
使用像素到像素指令进行训练 | 无条件。 |  |
 |
| lllyasviel/control_v11p_sd15_inpaint |
使用图像修复进行训练 | 无条件。 |  |
 |
| lllyasviel/control_v11p_sd15_mlsd |
使用多级线段检测进行训练 | 带有注释线段的图像。 |  |
 |
| lllyasviel/control_v11f1p_sd15_depth |
使用深度估计进行训练 | 带有深度信息的图像,通常表示为灰度图像。 |  |
 |
| lllyasviel/control_v11p_sd15_normalbae |
使用表面法线估计进行训练 | 带有表面法线信息的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_seg |
使用图像分割进行训练 | 带有分割区域的图像,通常表示为彩色编码图像。 |  |
 |
| lllyasviel/control_v11p_sd15_lineart |
使用线稿生成进行训练 | 带有线稿的图像,通常是白色背景上的黑色线条。 |  |
 |
| lllyasviel/control_v11p_sd15s2_lineart_anime |
使用动漫线稿生成进行训练 | 带有动漫风格线稿的图像。 |  |
 |
| lllyasviel/control_v11p_sd15_openpose |
使用人体姿势估计进行训练 | 带有人体姿势的图像,通常表示为一组关键点或骨架。 | 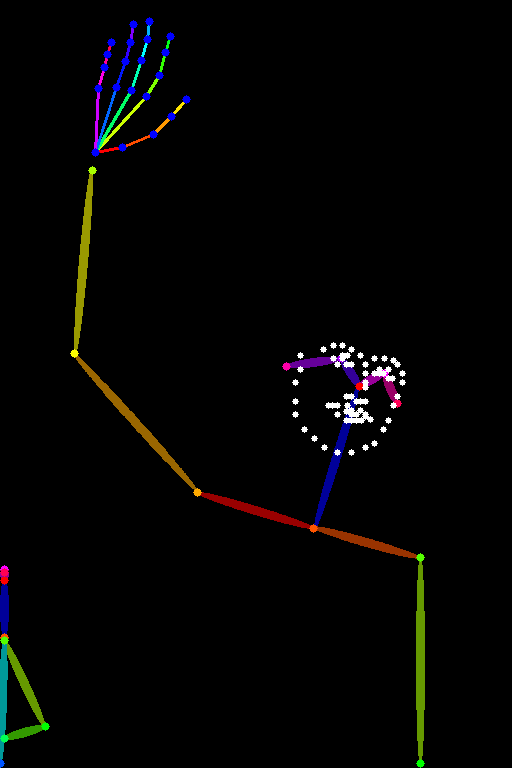 |
 |
| lllyasviel/control_v11p_sd15_scribble |
使用基于涂鸦的图像生成进行训练 | 带有涂鸦的图像,通常是随机或用户绘制的笔触。 |  |
 |
| lllyasviel/control_v11p_sd15_softedge |
使用软边缘图像生成进行训练 | 带有软边缘的图像,通常用于创建更具绘画风格或艺术效果的图像。 |  |
 |
| lllyasviel/control_v11e_sd15_shuffle |
使用图像打乱进行训练 | 带有打乱补丁或区域的图像。 |  |
 |
| lllyasviel/control_v11f1e_sd15_tile |
使用图像平铺进行训练 | 模糊图像或图像的一部分。 |  |
 |
深度1.1的改进
- 训练数据集问题修复:之前的cnet 1.0训练数据集存在一些问题,包括(1)一小部分灰度人体图像被重复数千次,导致之前的模型有些容易生成灰度人体图像;(2)一些图像质量低、非常模糊或有明显的JPEG伪影;(3)一小部分图像由于数据处理脚本的错误而存在错误配对的提示。新模型修复了训练数据集的所有问题,在许多情况下应该更加合理。
- 相对无偏模型:新的深度模型是一个相对无偏的模型。它不是通过某种特定的深度估计方法针对特定类型的深度进行训练的。它不会过度拟合于某一种预处理器。这意味着该模型在不同的深度估计、不同的预处理器分辨率甚至由3D引擎创建的真实深度情况下都能更好地工作。
- 数据增强:在训练中应用了一些合理的数据增强方法,如随机左右翻转。
- 兼容性和改进:该模型是在深度1.0的基础上继续训练的,在深度1.0表现良好的所有情况下都应该能正常工作。如果不能正常工作,请提供图像并提交一个问题,我们将查看具体情况。深度1.1在深度1.0失败的许多情况下都能有较好的表现。
- 性能对比:如果使用Midas深度(Web UI插件中的“深度”)和384的预处理器分辨率,深度1.0和1.1之间的差异应该很小。然而,如果尝试其他预处理器分辨率或其他预处理器(如leres和zoe),预计深度1.1会比1.0稍好一些。
更多信息
更多信息,请查看Diffusers ControlNet博客文章和官方文档。
📄 许可证
本模型使用CreativeML OpenRAIL M许可证。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)