🚀 EMOVA-Qwen-2.5-3B
EMOVA-Qwen-2.5-3B 是一款创新的端到端全模态大语言模型,无需依赖外部模型,即可实现视觉、听觉和语言交互。它能够处理文本、视觉和语音等多模态输入,并通过语音解码器和风格编码器生成带有生动情感控制的文本和语音响应。该模型具备通用的全模态理解和生成能力,在高级视觉语言理解、情感语音对话以及带有结构数据理解的语音对话方面表现出色。
✨ 主要特性
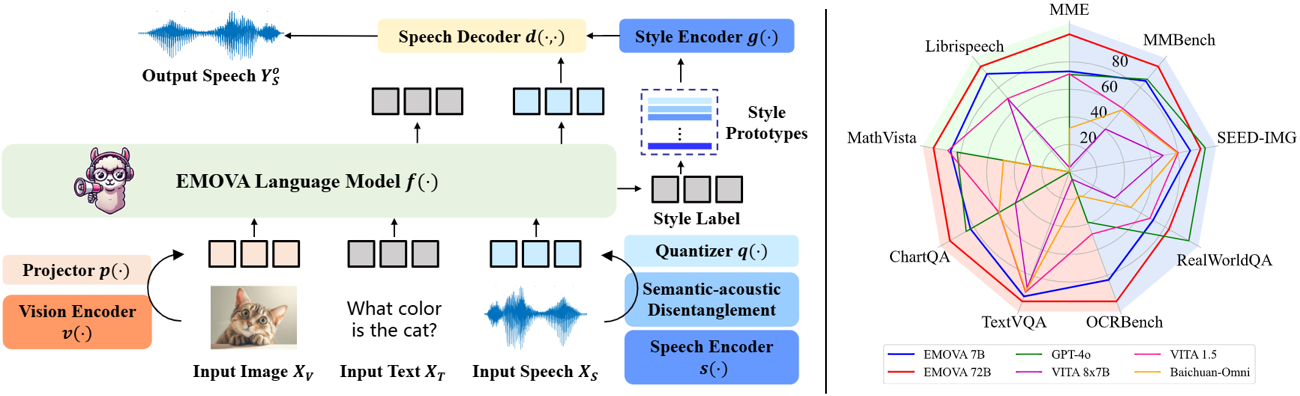
- 最先进的全模态性能:EMOVA在视觉语言和语音基准测试中同时取得了最先进的可比结果。表现最佳的模型 EMOVA-72B 甚至超越了包括GPT - 4o和Gemini Pro 1.5在内的商业模型。
- 情感语音对话:采用了语义 - 声学解耦的语音分词器和轻量级的风格控制模块,实现了无缝的全模态对齐和多样化的语音风格可控性。EMOVA支持双语(中文和英文) 语音对话,并具备24种语音风格控制(即2个说话人、3种音高和4种情感)。
- 多样化配置:开源了3种配置,即EMOVA - 3B/7B/72B,以支持不同计算预算下的全模态使用。您可以查看模型库,为您的计算设备找到最合适的模型!
📚 详细文档
| 属性 |
详情 |
| 库名称 |
transformers |
| 标签 |
全模态大语言模型、多模态大语言模型、情感语音对话 |
| 许可证 |
Apache - 2.0 |
| 数据集 |
Emova - ollm/emova - alignment - 7m、Emova - ollm/emova - sft - 4m、Emova - ollm/emova - sft - speech - 231k |
| 语言 |
英文、中文 |
| 基础模型 |
Emova - ollm/qwen2vit600m、Emova - ollm/Qwen2.5 - 3B - Instruct_add_speech_token_4096_nostrip |
| 模型索引名称 |
emova - qwen - 2 - 5 - 3b - hf |
| 新版本 |
Emova - ollm/emova - qwen - 2 - 5 - 3b - hf |
模型评估结果
| 任务类型 |
数据集名称 |
指标类型 |
指标值 |
指标名称 |
是否验证 |
| 多模态 |
AI2D |
准确率 |
78.6 |
准确率 |
是 |
| 多模态 |
ChartQA |
准确率 |
81.5 |
准确率 |
是 |
| 多模态 |
DocVQA |
准确率 |
93.5 |
准确率 |
是 |
| 多模态 |
InfoVQA |
准确率 |
71.2 |
准确率 |
是 |
| 多模态 |
MathVerse |
准确率 |
31.4 |
准确率 |
是 |
| 多模态 |
MathVista |
准确率 |
62.6 |
准确率 |
是 |
| 多模态 |
MMBench |
准确率 |
79.2 |
准确率 |
是 |
| 多模态 |
MME |
得分 |
2175 |
得分 |
是 |
| 多模态 |
MMVet |
准确率 |
57.3 |
准确率 |
是 |
| 多模态 |
OCRBench |
准确率 |
803 |
准确率 |
是 |
| 多模态 |
RealWorldQA |
准确率 |
62.6 |
准确率 |
是 |
| 多模态 |
Seed - Bench - Image |
准确率 |
74.9 |
准确率 |
是 |
| 多模态 |
Science - QA |
准确率 |
92.7 |
准确率 |
是 |
| 多模态 |
TextVQA |
准确率 |
77.2 |
准确率 |
是 |
| 自动语音识别 |
LibriSpeech (clean) |
字错率 |
5.4 |
测试字错率 |
无 |
不同模型性能对比
| 基准测试 |
EMOVA - 3B |
EMOVA - 7B |
EMOVA - 72B |
GPT - 4o |
VITA 8x7B |
VITA 1.5 |
百川全模态 |
| MME |
2175 |
2317 |
2402 |
2310 |
2097 |
2311 |
2187 |
| MMBench |
79.2 |
83.0 |
86.4 |
83.4 |
71.8 |
76.6 |
76.2 |
| SEED - Image |
74.9 |
75.5 |
76.6 |
77.1 |
72.6 |
74.2 |
74.1 |
| MM - Vet |
57.3 |
59.4 |
64.8 |
- |
41.6 |
51.1 |
65.4 |
| RealWorldQA |
62.6 |
67.5 |
71.0 |
75.4 |
59.0 |
66.8 |
62.6 |
| TextVQA |
77.2 |
78.0 |
81.4 |
- |
71.8 |
74.9 |
74.3 |
| ChartQA |
81.5 |
84.9 |
88.7 |
85.7 |
76.6 |
79.6 |
79.6 |
| DocVQA |
93.5 |
94.2 |
95.9 |
92.8 |
- |
- |
- |
| InfoVQA |
71.2 |
75.1 |
83.2 |
- |
- |
- |
- |
| OCRBench |
803 |
814 |
843 |
736 |
678 |
752 |
700 |
| ScienceQA - Img |
92.7 |
96.4 |
98.2 |
- |
- |
- |
- |
| AI2D |
78.6 |
81.7 |
85.8 |
84.6 |
73.1 |
79.3 |
- |
| MathVista |
62.6 |
65.5 |
69.9 |
63.8 |
44.9 |
66.2 |
51.9 |
| Mathverse |
31.4 |
40.9 |
50.0 |
- |
- |
- |
- |
| Librispeech (字错率↓) |
5.4 |
4.1 |
2.9 |
- |
3.4 |
8.1 |
- |
💻 使用示例
本仓库包含以 EMOVA代码库 原始格式 组织的 EMOVA - Qwen2.5 - 3B 检查点,因此,它应与EMOVA代码库一起使用。其配对的配置文件可在 此处 获取。您可以查看 此处 以使用此检查点启动Web演示。
📄 许可证
本项目采用Apache - 2.0许可证。
📚 引用
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)