🚀 波斯语米斯特拉尔7B模型
波斯语米斯特拉尔7B模型是专门为波斯语问答和自然语言处理任务设计的微调版本模型,能有效提升波斯语相关任务的处理能力。

模型描述 |
输出示例 |
基准测试结果 |
使用方法 |
训练与微调
🚀 快速开始
以下是使用该模型的简单步骤,你可以按照下面的代码示例进行操作。
✨ 主要特性
- 基于米斯特拉尔7B模型进行微调,专为波斯语问答和自然语言处理任务设计。
- 通过在多个波斯语数据集上训练,提升了对波斯语的理解和处理能力。
📦 安装指南
使用该模型需要安装transformers库,你可以使用以下命令进行安装:
pip install transformers
💻 使用示例
基础用法
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("aidal/Persian-Mistral-7B")
model = AutoModelForCausalLM.from_pretrained("aidal/Persian-Mistral-7B")
input_text = "پایتخت ایران کجاست؟"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
📚 详细文档
模型描述
波斯语米斯特拉尔是米斯特拉尔7B的微调版本,专为波斯语问答和自然语言处理任务而设计。
输出示例
示例1:
- 输入:"درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیت ها در بدن"
- 训练后输出:"درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیت ها در بدن است. که به طور معمول از طریق تزریق وریدی استفاده می شود."
- 训练前输出:" درمان اصلی برای افراد مبتلا او آر اس، جایگزینی مایعات و الکترولیتها.The most important treatment for people with diarrhea is oral rehydration solution."
示例2:
- 输入:"سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و"
- 训练后输出:"سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و 150,000 نفر از آنها را کشتند."
- 训练前输出:"سال ۱۹۴۴ متفقین به فرانسه اشغال شده توسط آلمان، در عملیاتی در نرماندی حمله کرده و خرج گرفت.The United States and France have condemned the killing of a French aid worker in Afghanistan by Tal"
基准测试结果
| 模型 |
数据集 |
得分 |
| base-model-7b |
ARC-easy |
41.92% |
| base-model-7b |
ARC-easy |
39.12% |
| fa-model-7b |
ARC-easy |
37.89% |
| base-model-7b |
ARC-challenge |
37.12% |
| fa-model-7b |
ARC-challenge |
39.29% |
训练与微调
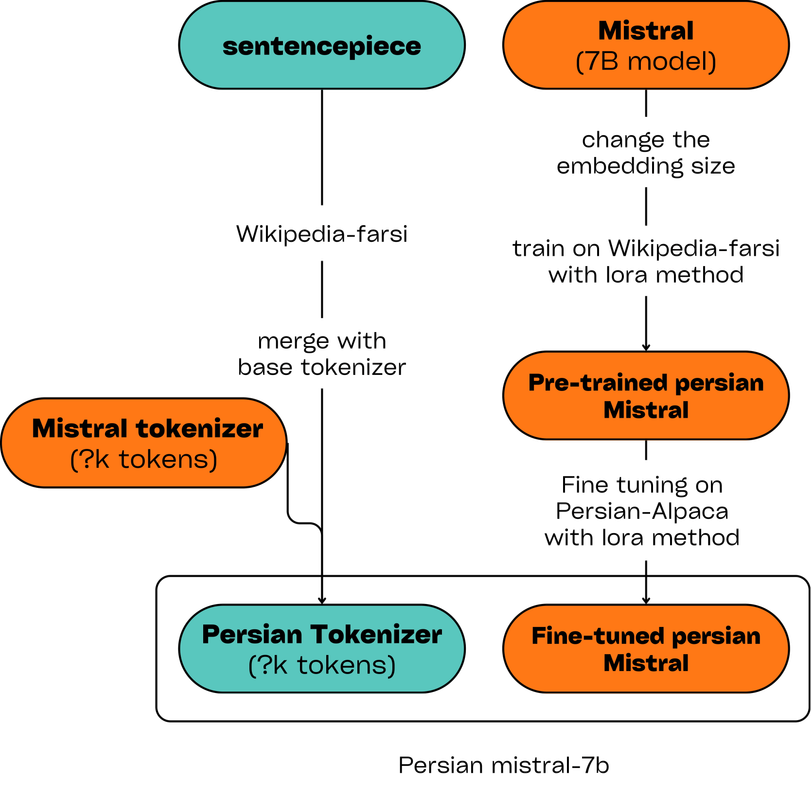
- 扩展分词器:基础的米斯特拉尔分词器不支持波斯语。作为初始步骤,我们在波斯语维基百科语料库上训练了一个SentencePiece分词器,随后将其与米斯特拉尔分词器集成。
- 预训练:在接下来的步骤中,我们扩展了基础模型的嵌入层,使其与波斯语分词器的大小相匹配。然后,我们使用LoRA方法在三个不同的数据集上训练模型:波斯语维基百科、伊斯兰书籍集合和Khamenei.ir的内容。
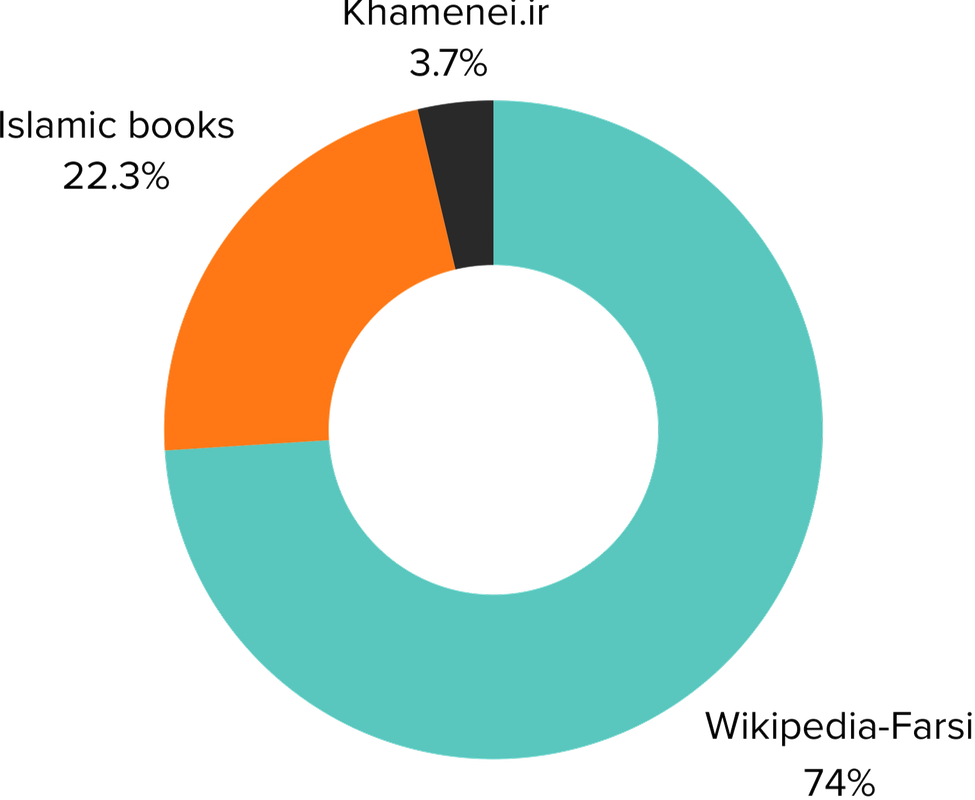
波斯语维基百科:1.83亿个词元,伊斯兰书籍:5500万个词元,Khamenei.ir:900万个词元
- 指令微调:在最后一步,我们使用LoRA方法在斯坦福阿尔帕卡的翻译版本上对模型进行微调,以增强模型的问答能力。
以下图表展示了上述步骤:
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)