🚀 Minerva-1B-base-v1.0模型卡片
Minerva是由Sapienza NLP与未来人工智能研究(FAIR)和CINECA合作开发的首个完全基于意大利语预训练的大语言模型(LLMs)系列。值得注意的是,Minerva模型是真正开放(数据和模型)的意大利语 - 英语大语言模型,大约一半的预训练数据包含意大利语文本。
🚀 快速开始
使用Hugging Face Transformers调用Minerva模型
import transformers
import torch
model_id = "sapienzanlp/Minerva-1B-base-v1.0"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
input_text = "La capitale dell'Italia è"
output = pipeline(
input_text,
max_new_tokens=128,
)
✨ 主要特性
- Minerva是首个完全基于意大利语从头开始预训练的大语言模型系列。
- 该模型是真正开放(数据和模型)的意大利语 - 英语大语言模型,约一半预训练数据包含意大利语文本。
📚 详细文档
模型描述
这是Minerva-1B-base-v1.0的模型卡片,该模型拥有10亿参数,在2000亿个标记(1000亿意大利语标记和1000亿英语标记)上进行训练。
该模型是Minerva大语言模型系列的一部分:
🚨⚠️🚨 偏差、风险和局限性 🚨⚠️🚨
此部分识别可预见的危害和误解。
这是一个基础模型,未经过对齐处理。模型可能存在以下问题:
- 过度代表某些观点,而忽视其他观点。
- 包含刻板印象。
- 包含个人信息。
- 生成以下内容:
- 仇恨性、辱骂性或暴力性语言。
- 歧视性或偏见性语言。
- 可能不适用于所有场景的内容,包括色情内容。
- 产生错误,包括将不正确的信息当作事实输出。
- 生成无关或重复的输出。
我们意识到当前预训练大语言模型存在偏差问题。更具体地说,作为(意大利语和英语)语言的概率模型,它们反映并放大了训练数据中的偏差。有关此问题的更多信息,请参考我们的调查:
模型架构
Minerva-1B-base-v1.0是基于Mistral架构的Transformer模型,通过修改层数、头数和隐藏状态维度,使其达到10亿参数。请查看配置文件以详细了解我们为该模型选择的超参数。
Minerva大语言模型系列的组成如下:
| 模型名称 |
标记数 |
层数 |
隐藏层大小 |
注意力头数 |
KV头数 |
滑动窗口 |
最大上下文长度 |
| Minerva-350M-base-v1.0 |
700亿(350亿意大利语 + 350亿英语) |
16 |
1152 |
16 |
4 |
2048 |
16384 |
| Minerva-1B-base-v1.0 |
2000亿(1000亿意大利语 + 1000亿英语) |
16 |
2048 |
16 |
4 |
2048 |
16384 |
| Minerva-3B-base-v1.0 |
6600亿(3300亿意大利语 + 3300亿英语) |
32 |
2560 |
32 |
8 |
2048 |
16384 |
模型训练
Minerva-1B-base-v1.0使用来自MosaicML的llm-foundry 0.6.0进行训练。使用的超参数如下:
| 模型名称 |
优化器 |
学习率 |
贝塔系数 |
误差项 |
权重衰减 |
调度器 |
热身步数 |
批量大小(标记) |
总步数 |
| Minerva-350M-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
余弦调度器 |
2% |
400万 |
16,690 |
| Minerva-1B-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
余弦调度器 |
2% |
400万 |
47,684 |
| Minerva-3B-base-v1.0 |
解耦AdamW |
2e-4 |
(0.9, 0.95) |
1e-8 |
0.0 |
余弦调度器 |
2% |
400万 |
157,357 |
模型评估
我们使用LM-Evaluation-Harness库对模型进行评估,该库是一个全面的框架,用于在广泛的评估任务中测试生成式语言模型。
所有报告的基准数据均来自LM-Evaluation-Harness套件。
意大利语数据
英语数据
训练数据
Minerva-1B-base-v1.0在从CulturaX采样的1000亿意大利语标记和1000亿英语标记上进行训练。数据选自以下来源:
- OSCAR-2201
- OSCAR-2301
- mC4
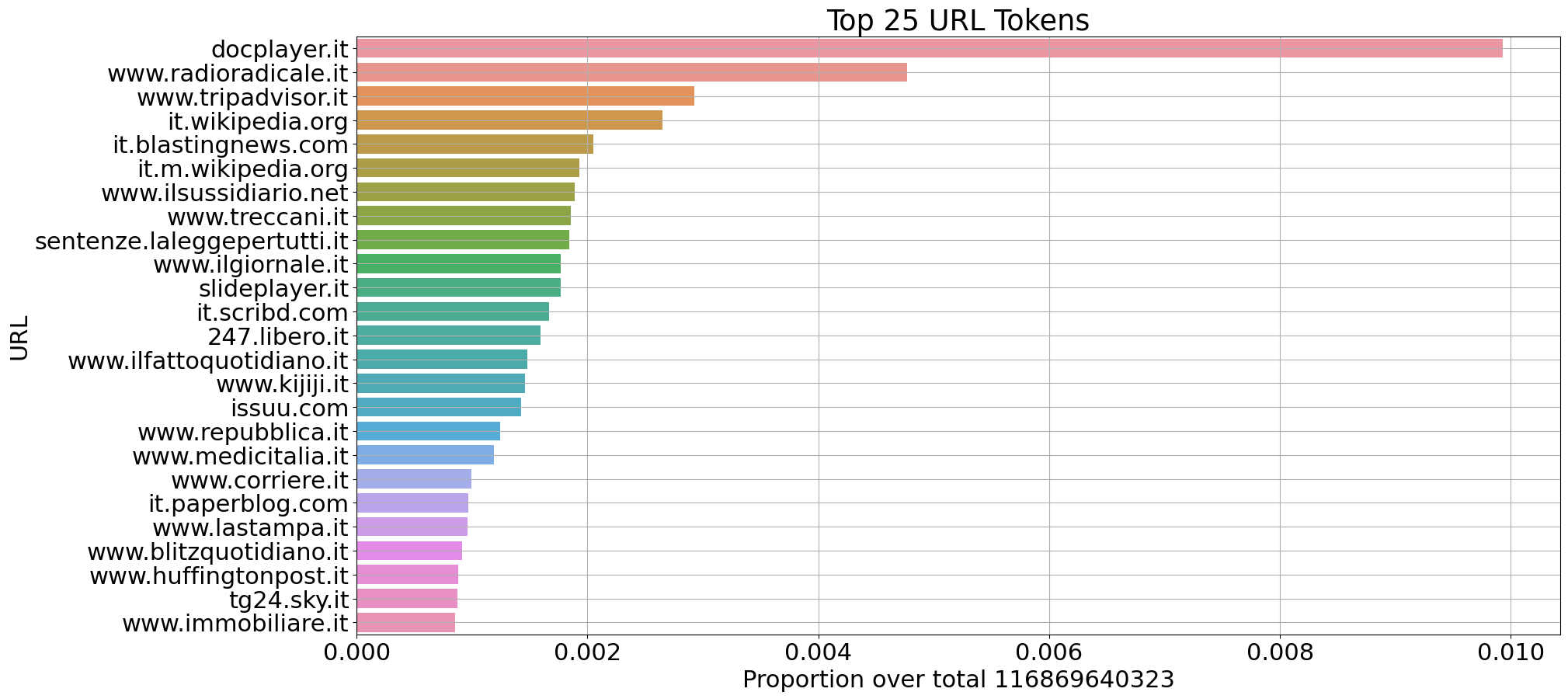
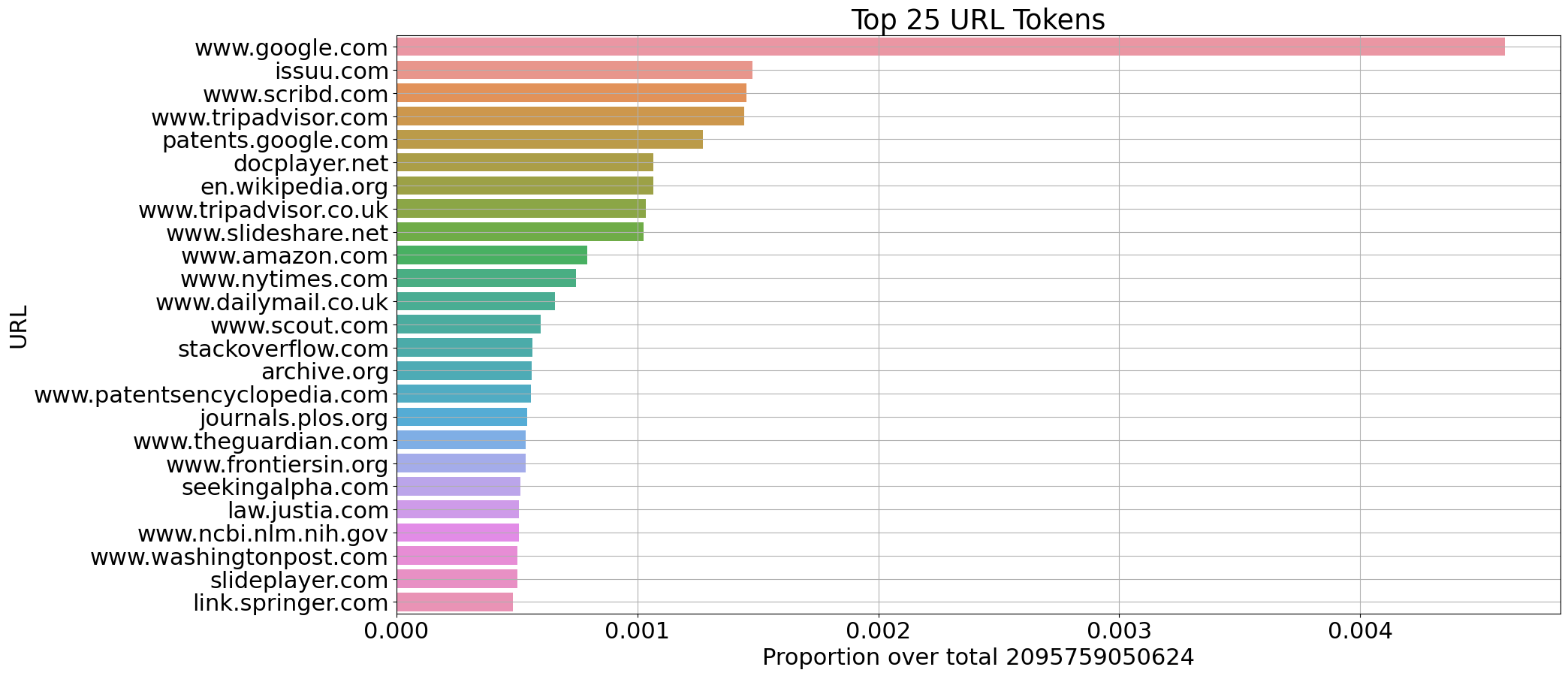
我们从CulturaX的选定来源中提取了意大利语(1150亿标记)和英语(2100亿标记)文档的一些统计信息:
每个领域标记数量的比例(意大利语)
每个领域标记数量的比例(英语)
分词器丰富度
分词器丰富度衡量每个分词单词产生的平均标记数量。在特定语言中显示高丰富度值的分词器通常表明它会对该语言的单词进行广泛分割。分词器丰富度与模型在特定语言上的推理速度密切相关,因为较高的值意味着需要生成更长的标记序列,从而降低推理速度。
基于Cultura X(CX)数据样本和维基百科(Wp)计算的丰富度:
| 模型 |
词汇表大小 |
丰富度(意大利语,CX) |
丰富度(英语,CX) |
丰富度(意大利语,Wp) |
丰富度(英语,Wp) |
| Mistral-7B-v0.1 |
32000 |
1.87 |
1.32 |
2.05 |
1.57 |
| gemma-7b |
256000 |
1.42 |
1.18 |
1.56 |
1.34 |
| Minerva-1B-base-v1.0 |
32768 |
1.39 |
1.32 |
1.66 |
1.59 |
注意事项
Minerva-350M-base-v1.0是一个预训练的基础模型,因此没有审核机制。
Sapienza NLP团队
- Riccardo Orlando:数据预处理、模型训练
- Pere-Lluis Huguet Cabot:数据预处理、词汇表、评估
- Luca Moroni:数据整理、数据分析、下游任务、评估
- Simone Conia:数据整理、评估、项目监督
- Edoardo Barba:数据预处理、下游任务、项目监督
- Roberto Navigli:项目负责人和协调人
特别感谢以下人员的支持
- Giuseppe Fiameni,英伟达
- Sergio Orlandini,CINECA
致谢
这项工作由PNRR MUR项目PE0000013 - FAIR资助。我们感谢CINECA在ISCRA计划下授予的“IscB_medit”奖项,感谢其提供高性能计算资源和支持。
📄 许可证
本模型采用Apache-2.0许可证。
 Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)