🚀 深度任意模型V2基础版 - Transformers版本
深度任意模型V2基于59.5万张合成标注图像和6200万张以上真实未标注图像进行训练,是目前最强大的单目深度估计(MDE)模型,具备以下特性:
- 比深度任意模型V1拥有更精细的细节
- 比深度任意模型V1和基于稳定扩散(SD)的模型(如Marigold、Geowizard)更稳健
- 比基于SD的模型更高效(快10倍)、更轻量级
- 使用预训练模型进行微调后,能获得出色的性能
此模型检查点与transformers库兼容。
深度任意模型V2由李和杨等人在同名论文中提出。它采用了与原始深度任意模型相同的架构,但使用了合成数据和更大容量的教师模型,从而实现了更精细、更稳健的深度预测。原始的深度任意模型由李和杨等人在论文《深度任意:释放大规模未标注数据的力量》中提出,并首次在此仓库发布。
在线演示。
🚀 快速开始
深度任意模型V2为单目深度估计提供了强大的解决方案,你可以按照以下步骤快速使用该模型。
✨ 主要特性
- 细节更精细:相较于深度任意模型V1,能捕捉到更多精细的细节。
- 性能更稳健:比深度任意模型V1和基于SD的模型(如Marigold、Geowizard)更稳健。
- 高效轻量:比基于SD的模型更高效(快10倍)、更轻量级。
- 微调效果出色:使用预训练模型进行微调后,能获得出色的性能。
📚 详细文档
模型描述
深度任意模型V2采用了DPT架构,并以DINOv2为骨干网络。
该模型在约60万张合成标注图像和约6200万张真实未标注图像上进行训练,在相对和绝对深度估计方面均取得了最先进的成果。
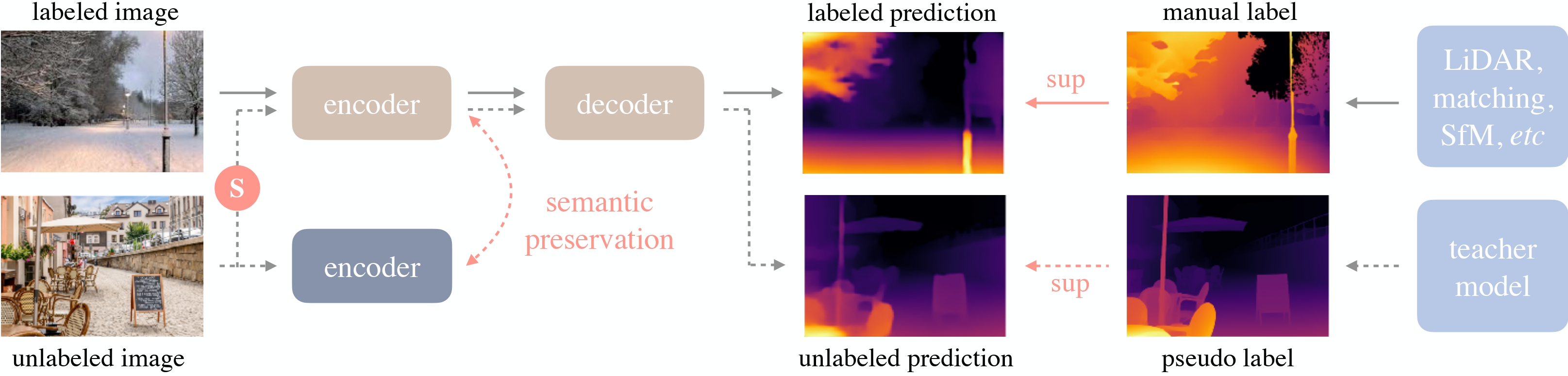
深度任意模型概述。取自原论文。
预期用途与限制
你可以使用该原始模型进行零样本深度估计等任务。请参考模型中心,查找其他感兴趣的版本。
如何使用
基础用法
以下是如何使用该模型进行零样本深度估计的示例:
from transformers import pipeline
from PIL import Image
import requests
pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Large-hf")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
depth = pipe(image)["depth"]
高级用法
你也可以使用模型和处理器类:
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Large-hf")
model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Large-hf")
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
更多代码示例,请参考文档。
引用
@misc{yang2024depth,
title={Depth Anything V2},
author={Lihe Yang and Bingyi Kang and Zilong Huang and Zhen Zhao and Xiaogang Xu and Jiashi Feng and Hengshuang Zhao},
year={2024},
eprint={2406.09414},
archivePrefix={arXiv},
primaryClass={id='cs.CV' full_name='Computer Vision and Pattern Recognition' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.'}
}
📄 许可证
本项目采用CC BY-NC 4.0许可证。
 Safetensors
Safetensors Transformers 支持多种语言
Transformers 支持多种语言%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)